
The Innovation
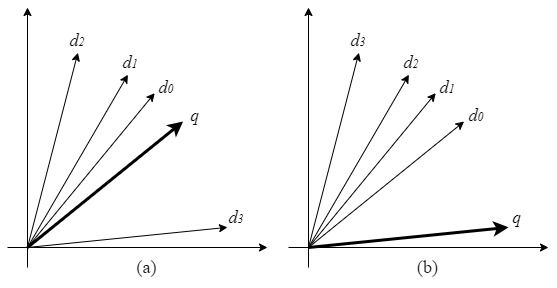
This research paper, "Vector Retrieval with Similarity and Diversity: How Hard Is It?" from arXiv, addresses a core challenge in modern AI-powered search and recommendation systems. The problem, termed Vectors Retrieval with Similarity and Diversity (VRSD), is formalized as retrieving a set of items (represented as dense vectors) that are both highly relevant to a user's query and diverse from one another.
The authors prove this dual-objective optimization is NP-complete, establishing a rigorous theoretical bound on its inherent difficulty. This explains why common heuristics like Maximal Marginal Relevance (MMR)—used in platforms from Amazon to Netflix—can be unstable. MMR relies on a manually tuned parameter to balance relevance and diversity, leading to optimization fluctuations and unpredictable results.
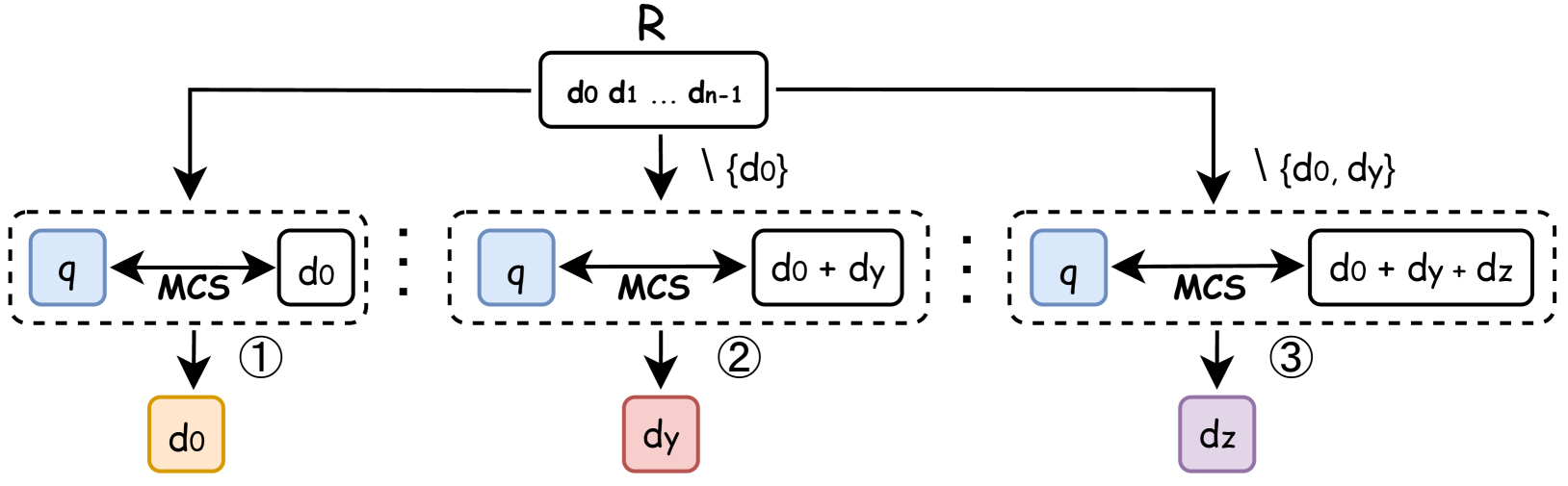
To solve VRSD, the researchers propose a novel, parameter-free heuristic algorithm. Instead of the sequential, greedy approach of MMR, their method maximizes the similarity between the query vector and the sum of the selected candidate vectors. This formulation intrinsically promotes diversity, as adding similar vectors yields diminishing returns, while adding a diverse yet relevant vector significantly increases the sum's alignment with the query. The algorithm was validated on scientific QA datasets using both objective geometric metrics and LLM-simulated subjective assessments, consistently outperforming MMR and k-Determinantal Point Processes (k-DPP).
Why This Matters for Retail & Luxury
For luxury and retail, vector retrieval is the engine behind critical client-facing and internal systems. Every semantic search on an e-commerce site, every "complete the look" recommendation, and every curated product feed in a mobile app relies on retrieving the right items from a massive vector database. The classic tension is clear: show only the most similar items (e.g., five identical black turtlenecks), and you miss cross-sell opportunities and bore the client. Show a diverse but irrelevant set, and you lose trust.
This technology directly benefits:
- E-commerce & Digital Merchandising: Powering "Shop the Look," "You May Also Like," and semantic search results that are both accurate and inspiring.
- Clienteling & CRM: Generating hyper-personalized, curated product selections for client outreach (e.g., "For your upcoming trip to Gstaad") that tell a cohesive yet varied story.
- Marketing & Content Hubs: Curating diverse yet on-brand product assortments for email campaigns, landing pages, and digital lookbooks.
- Internal Knowledge Retrieval (RAG): Enabling design, buying, and merchandising teams to query internal archives (past collections, trend reports, supplier info) and get comprehensive, non-redundant insights.
Business Impact & Expected Uplift
Balancing similarity and diversity is not an academic exercise; it directly drives key commercial metrics. While the paper does not provide retail-specific numbers, industry benchmarks for advanced recommendation systems are well-established.
A robust, parameter-free system for diverse retrieval can be expected to impact:
- Conversion Rate & Average Order Value (AOV): By presenting a more compelling and serendipitous assortment, you encourage discovery and add-to-bag. McKinsey & Company notes that advanced recommendation engines can drive 5-15% increases in revenue. A significant portion of this lift comes from effective diversification beyond obvious substitutes.
- Customer Engagement & Session Duration: Diverse, relevant results keep users exploring. Adobe's Digital Economy Index suggests highly engaging product discovery can increase session time by 20-30%.
- Operational Efficiency: Eliminating the need for manual tuning of diversity parameters (like MMR's λ) saves data science and merchandising teams significant time and reduces the risk of sub-optimal live performance.
Time to Value: For a company with an existing vector-based retrieval system (e.g., using Pinecone, Weaviate, or pgvector), implementing this heuristic could show measurable A/B test results within 1-2 quarters, including integration, testing, and iteration.
Implementation Approach
- Technical Requirements: This is an algorithm designed to work on top of an existing vector database and embedding infrastructure. You need:
- Data: Item embeddings (from images, text descriptions, or multimodal models) and a query embedding model.
- Infrastructure: A vector database (Pinecone, Weaviate, RedisVL, Milvus) or a database with vector extensions (PostgreSQL with pgvector).
- Team Skills: Machine Learning Engineers or Data Scientists proficient in Python and information retrieval concepts. Understanding of your current RAG or recommender system architecture is crucial.
- Complexity Level: Medium. The algorithm itself is a heuristic, not a model requiring training. The complexity lies in correctly integrating it into your production retrieval pipeline, replacing or augmenting existing MMR or ranking logic.
- Integration Points: The primary integration is with your Recommendation/Search Service Layer and Vector Database. It sits between the query embedding and the final result set returned to the UI. It must also connect with your E-commerce Platform (e.g., Shopify Commerce Components, Salesforce Commerce Cloud) and CRM/CDP for personalized query context.
- Estimated Effort: 2-4 months for a dedicated team. This includes prototyping the algorithm, integrating it into a staging environment, designing and running rigorous A/B tests (e.g., on recommendation carousels or search results pages), and gradual rollout.
Governance & Risk Assessment
- Data Privacy: The algorithm operates on item and query vectors, not raw customer data. However, the query vectors may be derived from personalized user history. Ensure this embedding process complies with GDPR/CCPA principles of data minimization and purpose limitation. All training of embedding models must use consented data.
- Model Bias Risks: The core risk is not in the VRSD algorithm itself but in the embedding models it depends on. If your image or text embeddings encode biases (e.g., associating "professional" with specific body types or skin tones, or "wedding" only with dresses), the "most similar" vectors will perpetuate this. Diversity will then be diversity within a biased subspace. Mandatory mitigation: Regular auditing of embedding spaces for fairness across sensitive attributes.
- Maturity Level: Advanced Prototype / Research-to-Production. The theoretical foundation is robust (NP-completeness proof), and the empirical evaluation on standard datasets is strong. However, it has not been documented in large-scale, billion-item retail production systems. It represents a state-of-the-art approach ready for piloting by engineering-mature retailers.
- Honest Assessment: This is not a plug-and-play SaaS solution. It is a production-ready algorithmic advancement for companies that already have vector retrieval in place and are frustrated with the limitations and tuning overhead of MMR. For these companies, implementing VRSD is a low-risk, high-potential-reward upgrade to a critical system component. For others, it should be part of a broader roadmap to build modern AI-powered discovery.







