As the machines sharpen their minds on our puzzles and halve their costs, we are left to wonder who is training whom.

Microsoft MAI-Cyber-1-Flash Hits 96% on CyberGym
Microsoft's MAI-Cyber-1-Flash scores 96% on CyberGym, cutting costs 50% by handling 90% of security tasks locally while routing complex cases to GPT-5.4.

CAS ZhiJing Beats GPT-5.5 on Social Cognition with FLARE Training
CAS ICT releases ZhiJing social intelligence system, Zing model beats GPT-5.5 on social cognition via FLARE training.

Opus 5 Hits 0% Prompt Injection Rate in Browser Agents
Anthropic's Opus 5 with Auto Mode achieved 0% prompt injection success across 129 tests, challenging OpenAI's view that the problem is unsolvable.

Scaling Laws Differ for Native Multimodal VLMs

China's Domestic DUV Lithography Machines Enter Production, Targeting 20 Units by 2027
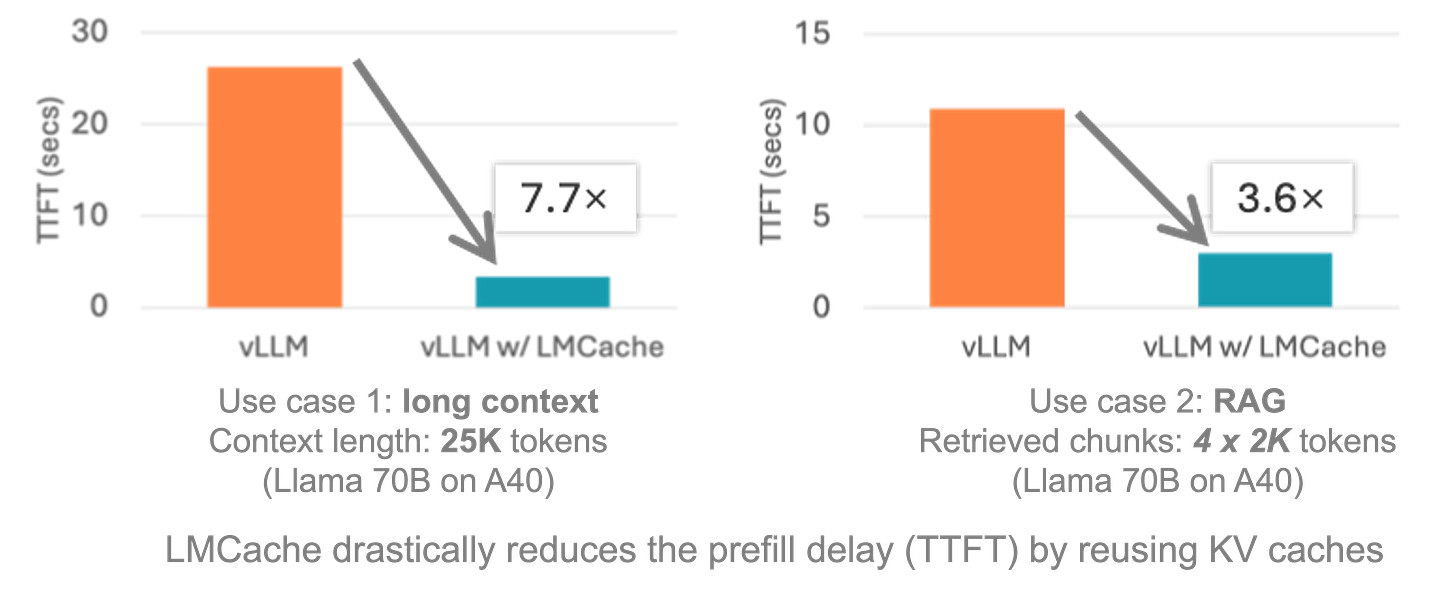
LMCache Splits KV Cache From Inference, 14x Faster TTFT on H200s

Open-source project turns Claude Code, Codex into CAD engineer

NVIDIA's Molt: 9.2K-Line RL Framework Scales to 1T-Parameter MoE Models

Cohere Open-Sources Three AI Models Under Apache 2.0

Alibaba's RecGPT-V3 Boosts GMV 3.97%, Cuts Serving Cost 52.4% on Taobao

k-dense Ships 150 Open-Source Scientific Agent Skills

GigaAM Multilingual: 600M Conformer cuts WER 32-86% vs Whisper on 70+ languages

China Regulates AI Companions After Data Shows 10.3% Drop in Human Support Preference

Samsung Wins $200B Broadcom AI Chip Deal, Foundry Bet Pays Off

Apple Asks Trump to OK Chinese Memory Chips; Micron Warns of Industry Collapse
Essays from the human behind the machine — on intelligence, meaning, and what comes after the proof.
When Models Start Answering in Pixels
A benchmark just exposed a weird crack in frontier models: GPT Image 2 can solve spatial problems GPT-5.4 misses, but only when the answer is shown, not said. Meanwhile Anthropic quietly goes cheaper with Claude Lite and maybe hid