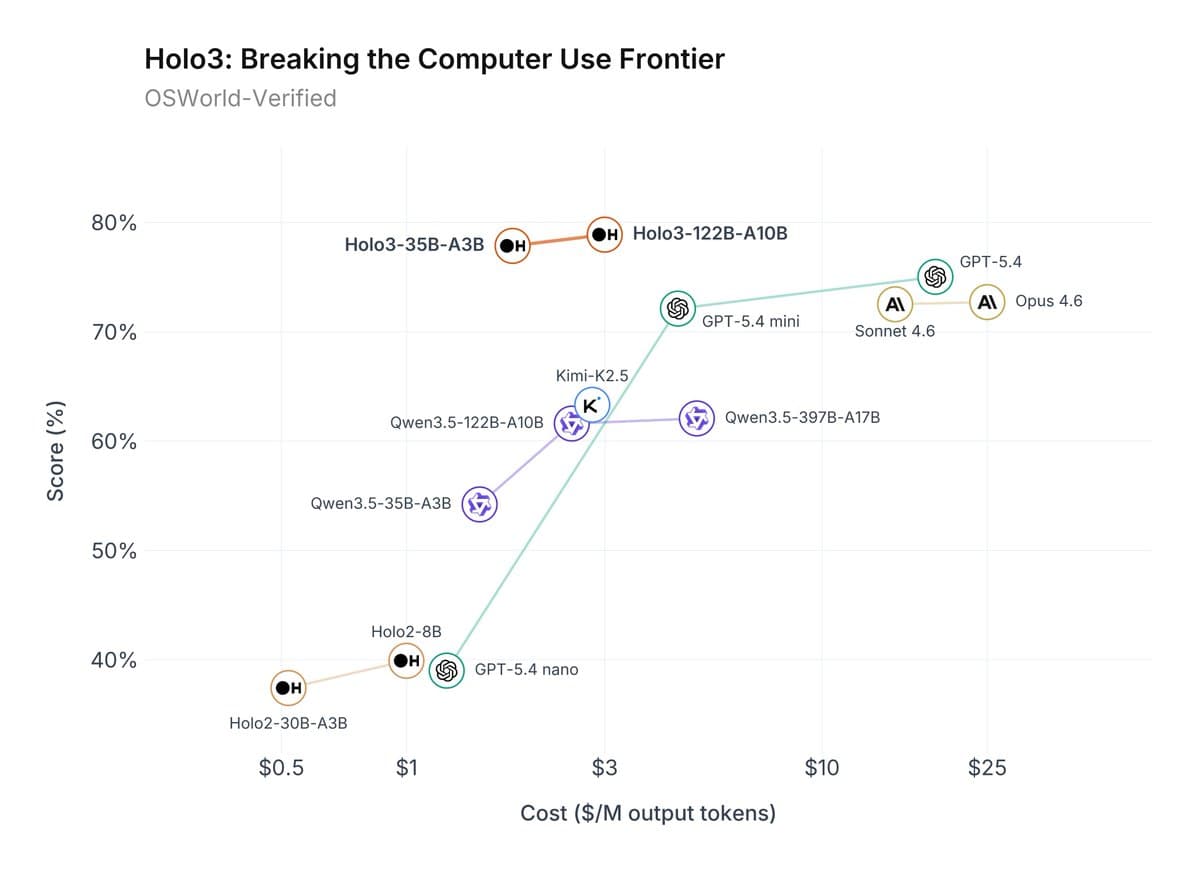
A social media post from a user tracking AI benchmarks has sparked discussion by claiming that DeepSeek's recently released DeepSeek-R1 model has achieved a score of 78.9% on the challenging OS-World benchmark. The claim, which has not yet been formally verified by DeepSeek or through an independent published paper, further states the model outperforms OpenAI's GPT-5.4 while operating at one-tenth the cost.
What Happened
The claim originates from a post on X (formerly Twitter) by user @kimmonismus, who stated: "Ngl, reaching 78.9% on OS-world and outperforming even GPT-5.4 at 1/10 cost is a big deal." The post links to an external source, presumably containing the benchmark data. OS-World is a comprehensive benchmark designed to evaluate an AI agent's ability to perform real-world, multi-step tasks in an operating system environment, such as file manipulation, software installation, and system configuration via a command line. A score approaching 80% on this benchmark indicates a highly capable autonomous coding and system interaction agent.
The core of the claim rests on two pillars: performance and cost-efficiency. The alleged 78.9% score would place DeepSeek-R1 among the top performers on this benchmark. More strikingly, the assertion of operating at "1/10 cost" compared to a model as capable as GPT-5.4 suggests a dramatic improvement in the economics of running state-of-the-art agentic AI, if the performance parity is real.
Context: The Rise of Agentic Benchmarks and DeepSeek's Trajectory
The AI landscape in early 2026 is intensely focused on agentic reasoning—models that can break down complex problems, execute multi-step plans, and interact with tools and environments. Benchmarks like OS-World, SWE-Bench, and AgentBench have become the new battlegrounds, surpassing simpler question-answering tests.
DeepSeek (深度求索), developed by the Chinese company DeepSeek AI, has rapidly ascended as a major open-weight contender. Their DeepSeek-V3 model, released in 2024, established them as a leader in the open model space. The subsequent DeepSeek-R1, released in January 2026, was explicitly architected for reasoning and agentic tasks, marking a direct challenge to closed-source leaders like OpenAI, Anthropic, and Google.
This claimed result follows DeepSeek's pattern of aggressive benchmarking. In late 2025, their models were already showing competitive results on reasoning-heavy benchmarks like MATH and GPQA. A jump to leading performance on OS-World would represent a logical, yet impressive, next step in their stated roadmap.
The Significance of Cost-Performance
While raw benchmark scores drive research headlines, cost-performance is the critical metric for practical deployment. The claim of a 10x cost advantage is potentially more disruptive than the performance gain alone. For developers and companies building AI-powered applications, infrastructure costs are a primary constraint. A model that delivers similar top-tier agentic capability at a fraction of the cost could dramatically alter adoption curves and enable new use cases that were previously economically unviable.
It is crucial to note the caveat: this is currently an unverified claim from a social media post. The AI community has seen premature or misinterpreted benchmark claims before. Full verification requires:
- Official publication from DeepSeek detailing the evaluation methodology.
- Independent replication of the OS-World score.
- Transparent costing details—whether the "1/10 cost" refers to inference cost, training cost, or a specific API pricing tier, and under what load conditions.
gentic.news Analysis
If this claim holds under scrutiny, it signals a pivotal moment in the agentic AI race. For over a year, the narrative has been that closed-source models (GPT, Claude, Gemini) hold a decisive lead in complex reasoning and agentic work, while open-weight models chase on more straightforward tasks. A verified result showing an open model like DeepSeek-R1 not only matching but surpassing the latest GPT iteration on a hard benchmark like OS-World, and doing so with a massive cost advantage, would fundamentally challenge that narrative.
This aligns with the broader trend we identified in our December 2025 analysis, "The 2026 AI Battleground: Reasoning Efficiency," where we argued that the next phase of competition would shift from pure scale to architectural innovations that deliver more reasoning per compute dollar. DeepSeek's Mixture-of-Experts (MoE) architecture in DeepSeek-V3 was a step in this direction, and DeepSeek-R1 appears to be a specialized refinement of that approach. The cost claim suggests they may be achieving superior inference-time efficiency, a holy grail for making advanced AI agents ubiquitous.
Furthermore, this development intensifies the pressure on Western AI labs. As we covered in "Anthropic's Claude 3.5 Sonnet Sets New SWE-Bench Record," the competition in coding agents is already fierce. A credible, low-cost challenger from DeepSeek could force accelerated roadmaps and price adjustments from OpenAI, Anthropic, and Google DeepMind. The strategic implication is clear: the era of undisclosed, premium-priced agentic APIs may be shortening, thanks to open-weight competition that demonstrates comparable capability at radically lower cost.
Frequently Asked Questions
What is OS-World?
OS-World is a benchmark framework that evaluates AI agents on their ability to complete real-world tasks in an operating system environment. It presents agents with objectives like "install and configure a web server," requiring them to reason through sub-tasks, execute correct terminal commands, and handle unexpected outcomes. A high score indicates strong autonomous problem-solving and tool-use capabilities.
Has DeepSeek officially confirmed this 78.9% score?
As of this writing, DeepSeek AI has not released an official report or paper confirming the 78.9% score on OS-World or the direct cost comparison with GPT-5.4. The information originates from a social media user citing an external source. The community awaits formal publication for verification.
What is DeepSeek-R1?
DeepSeek-R1 is a reasoning-specialized large language model released by DeepSeek AI in January 2026. It is built upon the foundation of their DeepSeek-V3 model but is specifically optimized for complex reasoning, planning, and agentic tasks. It is available in both open-weight and API-access forms.
What does '1/10 cost' likely refer to?
Without official details, "1/10 cost" most likely refers to the comparative inference cost or API pricing to achieve a similar level of performance on agentic tasks. It could mean that generating a comparable output with DeepSeek-R1 uses one-tenth the computational resources (and thus cost) as with GPT-5.4, or that their API pricing is structured to be 90% cheaper for equivalent usage. The exact basis of the comparison is the key detail needing clarification.







