The Innovation — What the Source Reports
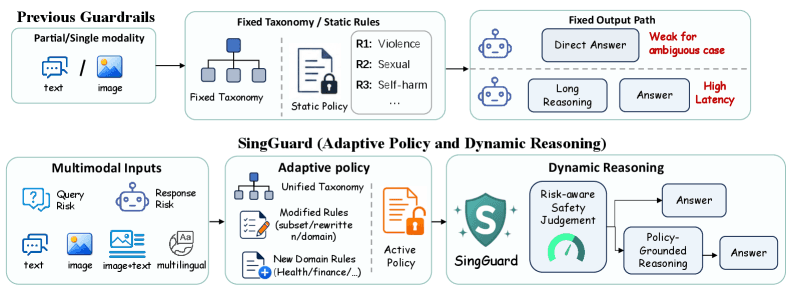
A new research paper titled "MemRerank: Preference Memory for Personalized Product Reranking" introduces a technical solution to a core problem in AI-driven e-commerce: how to effectively use a user's long and noisy purchase history for personalization without overwhelming the context window of a Large Language Model (LLM).
The central thesis is that naively appending a user's raw purchase history—a list of items, dates, and perhaps reviews—to an LLM prompt is inefficient. This raw data is often lengthy, contains irrelevant items for the current query, and includes noise that can distract the model. The result is suboptimal personalization in systems like shopping assistants or product rerankers.
To solve this, the researchers propose MemRerank, a two-component "preference memory" framework:
- A Memory Extractor: This module is trained to distill a user's purchase history into a concise, query-independent summary vector—the "preference memory." This memory aims to capture latent user tastes and patterns.
- Integration with an LLM-based Reranker: The extracted memory is then provided as additional context to an LLM tasked with reranking a list of candidate products for a user. The LLM uses this distilled signal, rather than the raw history, to personalize the ranking.
The key technical innovation is in how the Memory Extractor is trained. Instead of using a simple supervised loss, the researchers use Reinforcement Learning (RL), where the reward signal is the downstream reranking performance. The extractor learns to create memories that directly maximize the quality of the final personalized product list.
To evaluate their system, the authors built a benchmark around a "1-in-5" selection task. Given a user query and five candidate products, the LLM must identify the one the user is most likely to purchase, leveraging the provided history (either raw or distilled). MemRerank was tested with two different LLM-based rerankers and consistently outperformed three baselines: using no history, using the raw history, and using an off-the-shelf memory module. The performance gain reached up to +10.61 absolute percentage points in 1-in-5 accuracy.
The paper concludes that explicit, learned preference memory is a practical and effective component for building more capable "agentic" e-commerce systems.
Why This Matters for Retail & Luxury
For luxury and high-value retail, personalization is not a nice-to-have; it's a revenue-critical function that builds client loyalty. However, the challenge of leveraging deep client history is acute in this sector.
- The High-Value, Long-Tail Client Journey: A luxury client's history is particularly valuable. A purchase of a handbag five years ago, followed by shoes two years ago, and perfume last season, tells a story of evolving taste, brand loyalty, and life stage. MemRerank's ability to distill this longitudinal data into a coherent "taste profile" could power assistants that remember a client's preference for classic styles over logos, or their shift from ready-to-wear to haute couture.
- Overcoming the "Noise" of Gifts and Occasions: Luxury purchases are often for gifting or special occasions. A raw history showing a man's fragrance purchase might mislead a system into thinking he's interested in perfume for himself. A well-trained memory extractor could learn to identify and downweight such situational purchases, focusing on the core, repeatable preferences.
- Enabling Sophisticated Conversational Commerce: The future of luxury service is conversational—through dedicated client advisors or AI assistants. For an LLM to hold a coherent, personalized shopping conversation, it needs a quick, accurate understanding of the client. A pre-computed, distilled memory is far more efficient than re-processing hundreds of past transactions during each chat turn, enabling faster, more context-aware interactions.
Business Impact
The reported +10.61 point lift in accuracy on a 1-in-5 selection task is a significant experimental result. In a real-world reranking scenario, this could translate to:
- Higher Conversion Rates: More relevant products placed in top positions directly influence click-through and purchase rates.
- Increased Average Order Value (AOV): Better understanding of a client's taste and price tolerance allows for more confident upselling of complementary high-margin items.
- Enhanced Client Retention: Personalized experiences that demonstrate an understanding of a client's unique journey foster emotional connection and loyalty.

However, it is crucial to note this is a research result on a specific benchmark. Real-world impact would depend on the quality of historical data, the domain (luxury goods vs. fast-moving consumer goods), and integration into a live production system. The value proposition is strongest for retailers with rich, longitudinal purchase data and a strategic focus on AI-powered clienteling.
Implementation Approach
Implementing a system like MemRerank is a non-trivial engineering and MLOps undertaking, suitable for organizations with mature AI teams.

Technical Requirements:
- Data Pipeline: A robust pipeline to access and featurize user purchase histories (item IDs, categories, attributes, timestamps, price points).
- RL Training Infrastructure: Training the memory extractor with RL requires a simulated or logged environment where reranking decisions can be evaluated. This is complex and computationally intensive.
- LLM Backbone: A capable LLM (proprietary or open-source) serving as the reranker, with an API designed to accept the memory vector as input.
- Serving Architecture: A low-latency system to retrieve a user's pre-computed memory vector and inject it into the LLM prompt at inference time.
Complexity & Effort: This is a high-complexity, high-effort project. The core research challenge—training the RL-based memory extractor—would require significant machine learning expertise. A pragmatic first step for a retail AI team might be to experiment with simpler distillation techniques (e.g., using an LLM to summarize a history into text) before attempting the full RL approach.
Governance & Risk Assessment
- Privacy & Data Governance: The preference memory is a distilled representation of a user's personal purchase data. Its creation, storage, and use must comply with GDPR, CCPA, and other regulations. Clear data lineage and user consent for profiling are mandatory.
- Bias Amplification: If historical purchase data reflects societal or systemic biases (e.g., gender-stereotyped recommendations), the memory extractor could learn and amplify these patterns. Continuous bias auditing of the reranker's outputs is essential.
- Maturity Level: This is cutting-edge academic research (TRL 3-4), not a production-ready library. The risks associated with implementing a novel RL system in a customer-facing application are high. Extensive A/B testing in a controlled environment would be required before any broad deployment.
- Explainability: The memory vector is a latent representation. Explaining why a particular product was recommended ("because your memory vector indicated a preference for Italian leather goods") may be difficult, potentially clashing with demands for transparency in high-stakes luxury purchases.