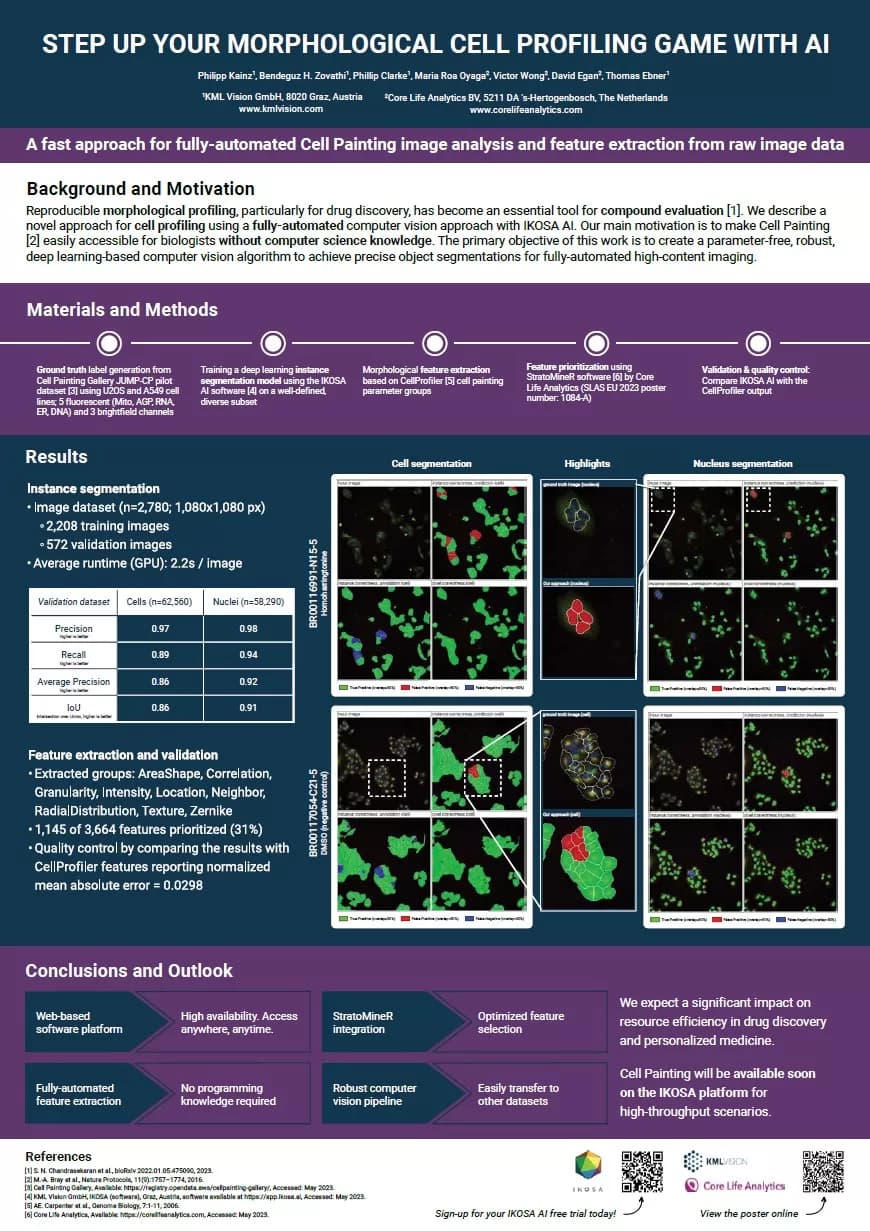
Microsoft researchers released MorphoHELM, a benchmark evaluating 20+ representation extraction methods for Cell Painting. The study, posted to arXiv on May 14, 2026, finds no deep learning model beats classic computer vision across all tasks.
Key facts
- MorphoHELM evaluates 20+ representation extraction methods.
- Posted to arXiv on May 14, 2026.
- No deep learning model beats classic CV across all settings.
- Each task tested at multiple batch effect levels.
- Code, data, and tools available at github.com/microsoft/MorphoHELM.
The Fragmented Evaluation Problem
Cell Painting, the most widely-used morphological profiling assay, generates microscopy images that capture cellular responses to perturbations. For drug screening, researchers extract representations from these images using a growing array of deep learning models. But evaluation has been fragmented — each model tested on different tasks, datasets, and metrics [According to MorphoHELM].
MorphoHELM consolidates evaluation standards, extending and correcting them for robustness. The benchmark tests methods across multiple biological signal types — including cell health, perturbation classification, and compound mechanism-of-action — while systematically varying batch effects (technical noise) [per the arXiv preprint].
Key Finding: Classic CV Still Wins
The benchmark's defining feature is its batch effect testing. MorphoHELM evaluates each task at different noise levels, directly quantifying how detection of biological signal degrades as technical noise increases. This reveals trade-offs: models that excel at one signal type often fail at others [According to MorphoHELM].
The headline result: "no existing model outperforms classic computer vision analytic strategies across all settings, which remain the strongest general use-case representations." Deep learning methods, including self-supervised and transformer-based approaches, show specialization but lack the robustness of traditional hand-crafted features and analytic pipelines.
Implications for Drug Discovery

Cell Painting is central to phenotypic drug discovery, where unbiased morphological profiling can identify novel compound activities. The benchmark's public release — datasets, code, and evaluation tools on GitHub — aims to standardize future comparisons. The finding that simple CV methods remain competitive suggests the field may need to rethink evaluation protocols that favor newer architectures [as reported by Microsoft Research].
Authors Emre Hayir, Lorin Crawford, and Alex X. Lu emphasize that batch effect control is critical for fair comparison. Without it, apparent gains from deep learning may reflect overfitting to dataset-specific noise rather than genuine biological insight.
What to watch
Watch for follow-up studies using MorphoHELM to benchmark new foundation models for microscopy, and whether self-supervised methods like DINO or MAE can close the gap with classic CV on batch-effect-controlled evaluations.







