
What Happened
A research team has published a paper on arXiv proposing a novel, fully automated framework for query expansion (QE) that addresses two critical limitations of current LLM-based approaches: dependency on hand-crafted prompts/manually chosen examples, and sensitivity to domain shifts. The system, detailed in "Automatic In-Domain Exemplar Construction and LLM-Based Refinement of Multi-LLM Expansions for Query Expansion," represents a significant step toward making sophisticated QE techniques scalable and practical for real-world applications without requiring labeled training data.
The core innovation lies in automating what has traditionally been a labor-intensive, expert-driven process. Query expansion—the technique of reformulating or augmenting a user's search query to improve retrieval results—has seen renewed interest with the advent of LLMs. However, existing methods often rely on carefully engineered prompts and manually selected "few-shot" examples that demonstrate the desired expansion behavior. This makes them brittle when applied to new domains (like moving from general web search to specialized retail product search) and difficult to scale.
Technical Details
The proposed framework operates in two main phases:
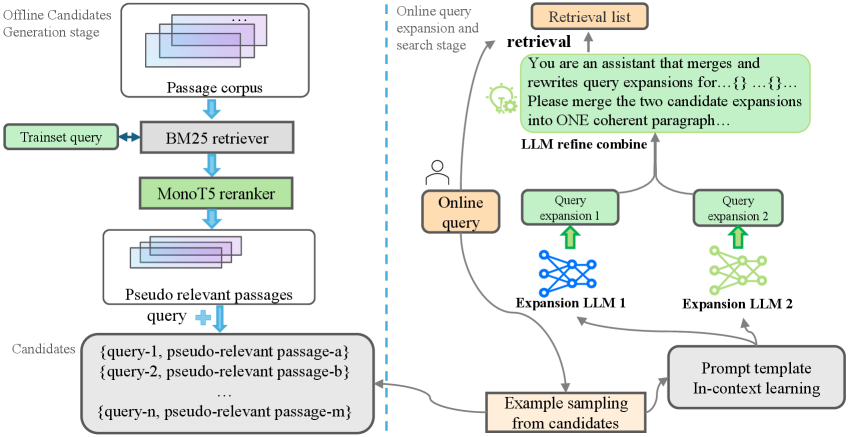
1. Automatic In-Domain Exemplar Construction
Instead of requiring a human to curate examples of good query expansions for a new domain, the system builds its own pool of demonstrations automatically:
- Harvesting Pseudo-Relevant Passages: For a target domain (e.g., a corpus of product descriptions), the system uses an initial retrieval pipeline combining BM25 (a classic keyword-based ranking function) and MonoT5 (a neural re-ranker) to find passages that are likely relevant to a set of seed queries.
- Cluster-Based Exemplar Selection: From this harvested pool, a training-free clustering strategy selects a diverse set of (query, relevant passage) pairs to serve as demonstrations. This diversity ensures the LLM sees varied examples of successful expansions, making the resulting in-context learning more robust and stable.
The result is a domain-adaptive QE system that requires zero human supervision to set up for a new corpus.
2. Multi-LLM Ensemble with Refinement
Recognizing that different LLMs have complementary strengths, the researchers employ an ensemble approach:
- Dual-LLM Expansion: Two heterogeneous LLMs (e.g., one larger, more creative model and one smaller, more precise model) independently generate expansions for the same input query, using the automatically constructed exemplars for in-context learning.
- LLM-Based Refinement: A third "refinement" LLM takes these two candidate expansions and consolidates them into a single, coherent expansion. This step synthesizes the strengths of each model's output, potentially correcting errors and combining insights.
Experimental Results & Significance
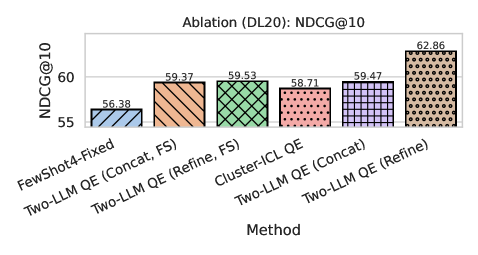
The framework was evaluated across three diverse testbeds: TREC Deep Learning 2020 (general web search), DBPedia (structured knowledge base), and SciFact (scientific claim verification). The refined ensemble delivered consistent and statistically significant gains over strong baselines, including:
- Traditional lexical methods (BM25)
- Classical QE (Rocchio)
- LLM-based zero-shot expansion
- LLM-based fixed few-shot expansion (using static, non-domain-specific examples)
The paper positions the work as both a reproducible testbed for studying exemplar selection and multi-LLM generation, and a practical, label-free solution for real-world QE deployment. By removing the need for manual prompt engineering and curated datasets, it lowers the barrier to implementing sophisticated, domain-aware search enhancement.
Retail & Luxury Implications
While the research is not applied directly to retail, the technical approach has clear implications for improving search and discovery in luxury and retail contexts. The core challenge the paper addresses—how to adapt powerful LLM capabilities to a specific domain without manual effort—is precisely the challenge faced by brands with specialized vocabularies, product attributes, and customer intent patterns.

Potential Application Pathways:
- E-commerce Search Enhancement: A luxury retailer could apply this framework to its product catalog and historical search logs. The system would automatically learn what constitutes a "good" query expansion for finding "evening gowns," "saffiano leather bags," or "GMT watches" within its specific inventory, improving recall for nuanced customer queries.
- Internal Knowledge Retrieval: For large retail groups, the method could automate the setup of semantic search over internal documents (style guides, material specifications, brand heritage archives) by self-constructing relevant examples from the corpus.
- Cross-Lingual and Conceptual Search: The automated exemplar construction could help bridge vocabulary gaps between customer language ("office to evening bag") and official product taxonomy ("medium crossbody with chain strap").
The ensemble refinement step is particularly interesting for luxury, where brand voice and attribute accuracy are paramount. One could configure the ensemble to balance a creative LLM (to understand descriptive, aspirational language) with a factual LLM (to precisely map to product SKUs and specs), with a refinement step ensuring the final expansion is both effective and brand-appropriate.
The framework's "label-free" nature is a major practical advantage. Luxury brands often lack large, labeled datasets of query reformulations, making supervised approaches infeasible. This method only requires the raw corpus (product descriptions, past queries, web copy) to bootstrap itself.
Implementation Considerations
For a technical team evaluating this approach:
- Infrastructure: Requires access to at least two, preferably three, LLM endpoints (could be different sizes of the same model family or different models entirely). The BM25-MonoT5 pipeline for exemplar harvesting is standard IR infrastructure.
- Latency: The three-stage process (exemplar construction, dual-LLM expansion, refinement) introduces latency. For real-time search, pre-computing expansions for common queries or using a distilled single-model version may be necessary.
- Cost: Multiple LLM calls per query increase inference cost. The value proposition hinges on the business impact of improved conversion from better search.
- Control: The refinement LLM's prompt would need careful tuning in a luxury context to ensure expansions align with brand terminology and avoid hallucination of non-existent attributes or styles.
This research provides a compelling blueprint for moving beyond generic, one-size-fits-all LLM prompts toward automated, domain-optimized search intelligence—a relevant direction for any retailer seeking to make their digital discovery experience as nuanced as their product offering.








