What Happened
A technical article on Medium, titled "Prompt Engineering, RAG e Fine-tuning: as diferentes estratégias de customização de LLMs e seus…" (Prompt Engineering, RAG and Fine-tuning: the different LLM customization strategies and their…), provides a comparative overview of the three dominant methods for adapting foundation models to specific tasks. While the full article is paywalled, the snippet and surrounding context from an RSS feed indicate its core thesis: Large Language Models (LLMs) have fundamentally changed AI product development, and choosing the right customization path is crucial.
The feed also surfaces related articles that highlight the ongoing industry discourse around these methods. One piece argues that LLMs are "overkill for the vast majority of use cases," challenging the default assumption to reach for the largest model. Another warns that RAG deployments are "doomed" without addressing a hidden bottleneck, pointing to the operational complexities often underestimated in production. A third discusses a new tool, "ArcLinkTune," aimed at simplifying the notoriously difficult and guesswork-heavy process of fine-tuning.
Collectively, these sources paint a picture of a maturing field moving from experimentation to pragmatic implementation, where the choice of technique has significant implications for cost, performance, and maintainability.
Technical Details: The Three Pillars of Customization
Based on the established knowledge in the field, which aligns with the article's premise, the three strategies can be broken down as follows:
Prompt Engineering: This is the simplest and most immediate method. It involves carefully crafting the input instructions (prompts) to guide a pre-trained, general-purpose LLM (like GPT-4 or Claude 3) toward a desired output. It requires no additional training or infrastructure but demands skill in iterative testing and is limited by the model's inherent knowledge and reasoning capabilities. Hallucination and a lack of domain-specific knowledge are key risks.
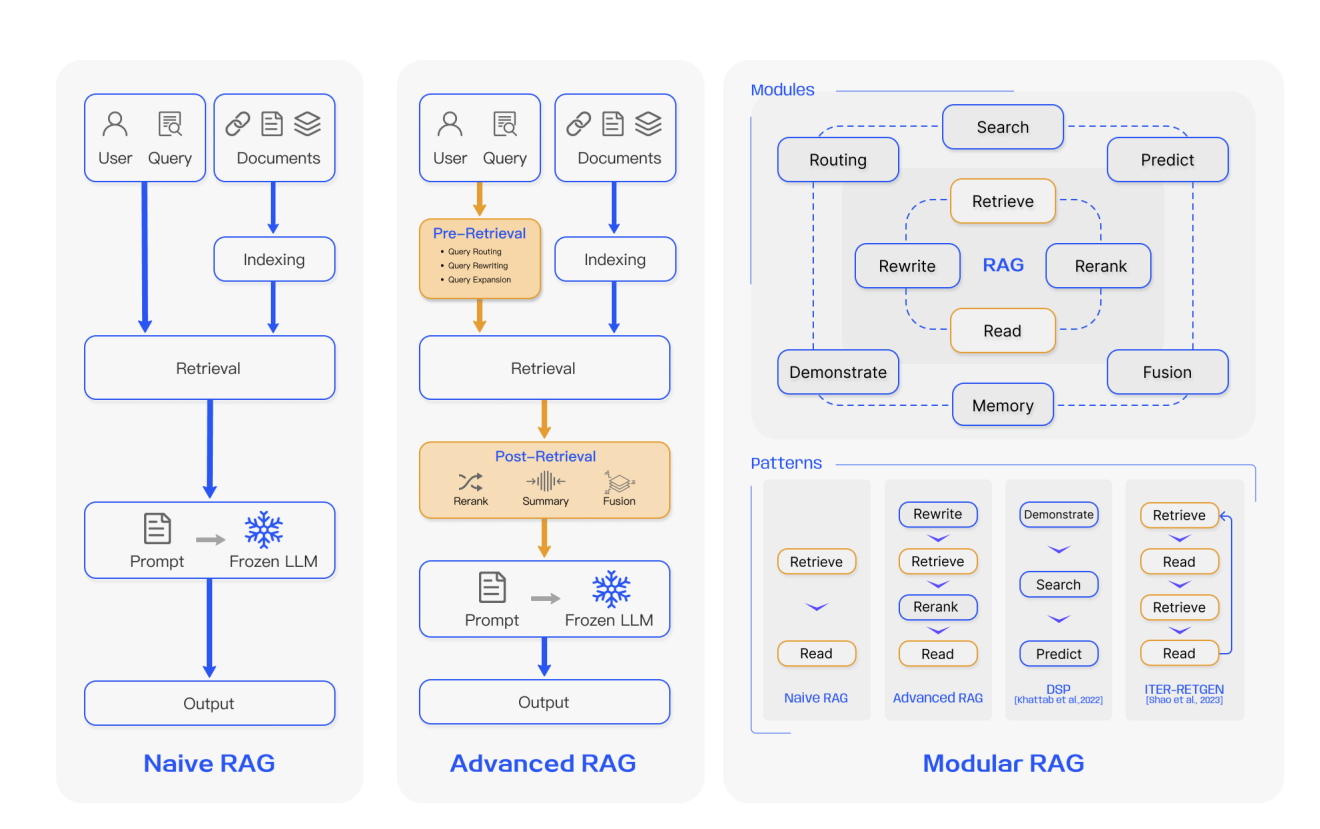
Retrieval-Augmented Generation (RAG): This architecture enhances an LLM by connecting it to an external, updatable knowledge base (like a vector database of company documents). When a query is received, a retrieval system fetches relevant context from this database, which is then passed to the LLM alongside the original prompt to generate a grounded, context-aware response. RAG is powerful for knowledge-intensive tasks where information is proprietary or changes frequently, as it avoids the need to retrain the model. However, it introduces system complexity involving retrieval, chunking, and embedding, and its success hinges on the quality of the retrieved context.
Fine-Tuning: This involves taking a pre-trained LLM and continuing its training on a specific, curated dataset. This process adjusts the model's internal weights, effectively teaching it new patterns, styles, or domain knowledge. It can yield highly specialized models that excel at a narrow task and often operate with lower latency than RAG systems. The downsides are significant: it requires high-quality labeled data, substantial computational resources, risks catastrophic forgetting of general knowledge, and creates a static model that must be retrained to incorporate new information.
Retail & Luxury Implications
The choice between these strategies is not academic for luxury and retail AI leaders; it directly impacts the feasibility, cost, and ROI of initiatives. Here’s how they map to potential use cases:
Prompt Engineering is ideal for low-risk, creative, or exploratory applications. Examples include generating initial copy for marketing campaigns, brainstorming product names, or creating varied customer email templates. It’s a fast, low-cost way to leverage AI where absolute factual accuracy is not paramount. As one related feed article skeptically notes, this approach often proves that a simpler, cheaper model with good prompting can suffice where teams might instinctively reach for an overpowered LLM.
Retrieval-Augmented Generation (RAG) is arguably the most strategically important for the sector. It is the backbone for building accurate, brand-aligned knowledge systems. Concrete applications include:
- Intelligent Clienteling Assistants: Agents that can query a unified knowledge base containing client purchase history, CRM notes, product catalogs, and brand heritage documents to provide personalized styling advice.
- Internal Policy & Process Guides: Systems that allow store staff or customer service to instantly find answers in complex manuals, sustainability reports, or compliance documents.
- Dynamic Product Q&A: Enhancing e-commerce sites with chatbots that provide accurate, detailed answers drawn from the latest technical specifications, care instructions, and inventory data.
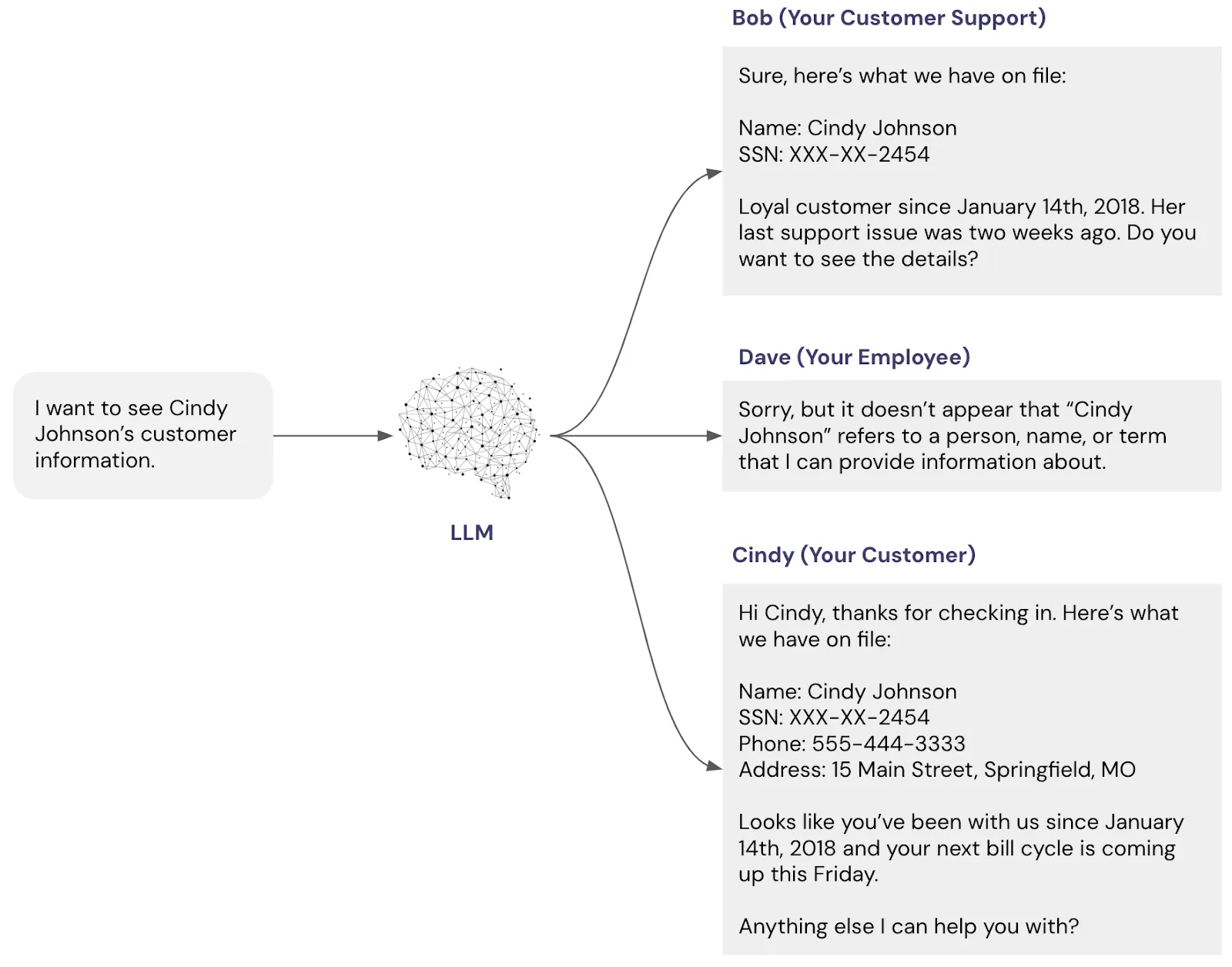
The recent surge in coverage of RAG—it appeared in 31 articles this week alone—underscores its status as the leading enterprise integration pattern. However, the feed’s warning about a "hidden bottleneck" that can doom deployments is a critical reminder. For luxury brands, this bottleneck could be the challenge of creating a unified, clean, and semantically rich knowledge graph from disparate data sources (ERP, PIM, CRM, legacy systems) before retrieval even begins.
Fine-Tuning is a specialized tool for creating consistent, brand-voice-native AI. A use case with clear ROI is fine-tuning a model on a corpus of successful customer service interactions, press releases, and brand literature to create an agent that communicates in the brand’s distinctive tone and style autonomously. It could also be used to create a model specialized in translating natural language queries into precise product attribute filters. However, the high cost and complexity mean it should be reserved for high-volume, mission-critical tasks where prompt engineering and RAG cannot achieve the required level of stylistic or behavioral consistency. The mention of tools like "ArcLinkTune" suggests the market is responding to make this process less opaque, but it remains a major undertaking.
Implementation Approach & Governance
For retail technical leaders, the pragmatic path often starts with prompt engineering for prototyping, then scales with RAG for knowledge-heavy production systems. Fine-tuning is a later-stage optimization for specific, high-value workflows.
Governance is paramount:
- RAG Systems require rigorous data governance to ensure the knowledge base is accurate, unbiased, and updated. A "garbage in, gospel out" problem is a real risk if unchecked data is retrieved and presented authoritatively by the LLM.
- Fine-Tuning demands careful curation of training data to avoid baking in unwanted biases or styles. The static nature of a fine-tuned model also creates a lifecycle management challenge.
- Privacy & IP: All three methods must be implemented with strict data boundaries, especially when using third-party model APIs. Client data used in RAG contexts or for fine-tuning must be meticulously anonymized and secured.