Key Takeaways
- A systematic diagnostic study finds LLM-based cross-encoder rerankers perform poorly in cold-start movie recommendation, suffering from low retrieval coverage, severe exposure bias, and minimal score discrimination.
- The performance gap is attributed to retrieval stage limitations, not the reranker's capacity.
What Happened
A new research paper, "Diagnosing LLM-based Rerankers in Cold-Start Recommender Systems: Coverage, Exposure and Practical Mitigations," presents a sobering reality check for the application of Large Language Models (LLMs) in recommendation systems. Published on arXiv, the study systematically diagnoses why LLM-based cross-encoder rerankers—which have gained significant attention for their potential in cold-start scenarios with limited user history—often fail in practical deployment.
The researchers conducted controlled experiments on the Serendipity-2018 movie recommendation dataset with 500 users across multiple random seeds. The results were stark: a simple popularity-based ranking baseline substantially outperformed the LLM reranking approach. The hit rate at 10 recommendations (HR@10) was 0.268 for popularity ranking versus a mere 0.008 for LLM reranking, a statistically significant gap (p < 0.001).
Technical Details: The Three Critical Failure Modes
The paper identifies three core failure modes that explain this dramatic underperformance:
Low Retrieval Coverage: The candidate generation stage feeding into the LLM reranker retrieved a very narrow set of items. The recall@200 (the fraction of relevant items found in the top 200 candidates) was only 0.109 for the LLM-based pipeline, compared to 0.609 for baseline retrieval methods. This suggests the LLM is being asked to rank from a pool that already misses most potentially relevant items—a classic "garbage in, garbage out" scenario.
Severe Exposure Bias: The LLM reranker exhibited extreme concentration in its recommendations. Across all recommendations generated, the reranker suggested only 3 unique movies. In contrast, a random baseline recommended 497 unique items. This creates a critical diversity problem, where the system would repeatedly show the same handful of items to all users, regardless of their potential interests.
Minimal Score Discrimination: The LLM's scoring mechanism failed to meaningfully distinguish between relevant and irrelevant items. The mean score difference was a negligible 0.098, with a Cohen's d effect size of 0.13, indicating no practical discrimination. The reranker's output scores were essentially uninformative for ranking.
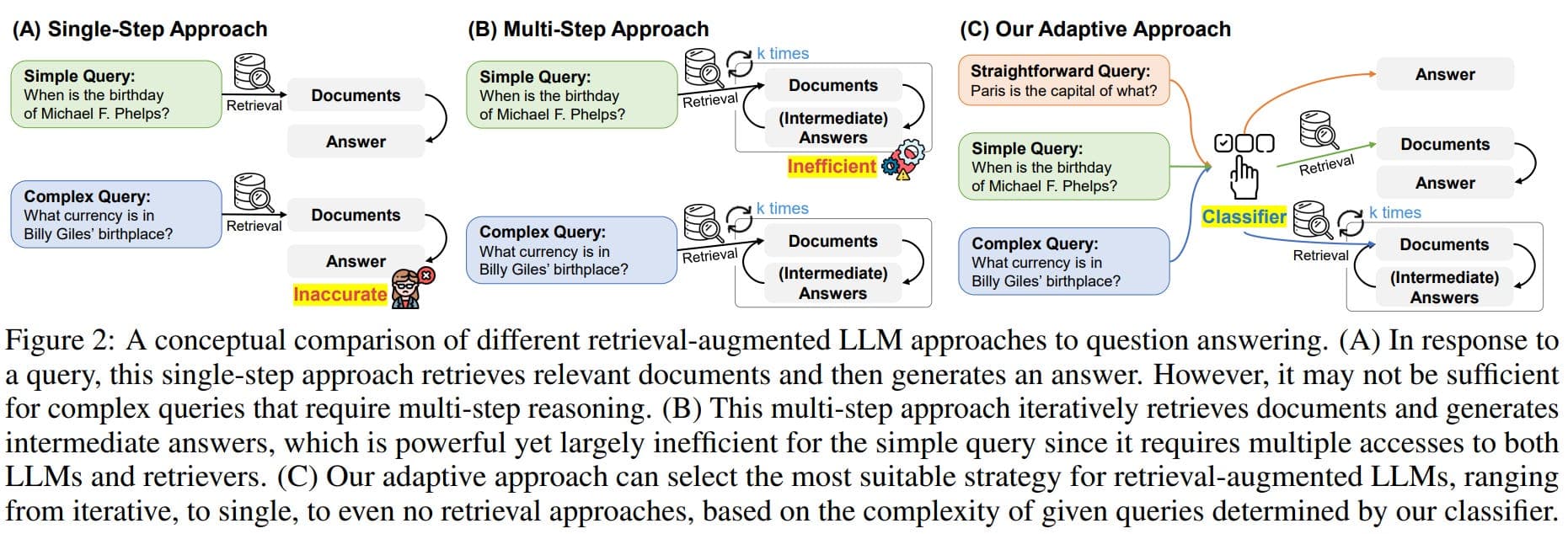
The study's crucial insight is that the primary performance gap is attributable to limitations in the retrieval stage, not the inherent capacity of the LLM-based cross-encoder reranker itself. The reranker is starved of a sufficiently broad and relevant candidate set from the outset.
Retail & Luxury Implications
While the study uses a movie dataset, its findings are directly applicable and critically important for retail and luxury AI teams exploring LLMs for personalization.

Cold-Start is a Core Retail Challenge: The "cold-start" scenario—where a new user has little to no interaction history, or a new product has no purchase data—is endemic in retail. Luxury brands, in particular, face this with high-value, low-frequency purchases and a constant influx of new seasonal collections. The promise of LLMs to understand nuanced product descriptions and user queries semantically makes them an attractive solution for this problem. This research throws cold water on a naive implementation.
The Risks of Direct Deployment: A retail team deploying an LLM reranker on top of a weak retrieval system could encounter the same catastrophic failures:
- Catastrophic Coverage Failure: A new visitor to a luxury fashion site might only be shown items from 2-3 specific brands or categories because the retrieval system failed to surface a broad catalog, severely limiting discovery and commercial opportunity.
- Extreme Exposure Bias: The system might obsessively recommend the same "hero" product or bestseller to every user, destroying any semblance of personalized curation and failing to promote the long-tail of the collection. For a brand like Louis Vuitton, this could mean only the iconic monogram bags are ever recommended, ignoring ready-to-wear, shoes, jewelry, and seasonal novelties.
- Wasted Compute & Poor ROI: Running a large, expensive LLM to rerank a poorly constructed candidate list is an inefficient use of resources that yields worse results than a simple heuristic like "most viewed" or "new arrivals."
The paper does not conclude that LLMs are useless for recommendation. Instead, it provides actionable recommendations for mitigation, which are highly relevant for technical architects:
- Hybrid Retrieval Strategies: Combine traditional collaborative filtering or vector search with LLM-augmented retrieval to ensure the candidate pool is both broad and semantically relevant.
- Candidate Pool Size Optimization: Experimentally determine the optimal number of initial candidates to feed to the reranker—too few causes coverage issues, too many may dilute quality and increase cost.
- Score Calibration Techniques: Apply post-processing to the LLM's output scores to improve discrimination between items, making the rankings more effective.
gentic.news Analysis
This research arrives amid a significant wave of activity and scrutiny on the core technologies involved. Large Language Models and Retrieval-Augmented Generation (RAG) have been trending topics in our coverage, appearing in 13 articles each this past week. This paper serves as a crucial counter-narrative to the unbridled optimism surrounding LLM application, emphasizing system-level engineering over model magic.

The findings align with a broader pattern of identifying vulnerabilities in complex AI systems. Just last week, we covered research exposing how just 5 poisoned documents can corrupt RAG systems, highlighting the fragility of these architectures. Similarly, this paper on rerankers exposes a different kind of fragility: performance collapse due to upstream data pipeline failures.
Furthermore, the focus on the retrieval stage as the primary culprit echoes a fundamental principle in search and recommendation engineering that luxury AI teams must heed: the ranking model is only as good as the candidates it receives. This connects to other recent arXiv publications in the recommendation space, such as "Is Sliding Window All You Need? An Open Framework for Long-Sequence Recommendation" and "LLM-HYPER: Generative CTR Modeling for Cold-Start Ad Personalization via LLM-Based Hypernetworks," all grappling with the challenge of effectively leveraging LLMs within a robust system architecture.
For luxury retail, where brand equity and curated experience are paramount, the exposure bias failure mode is particularly dangerous. It threatens to create a homogenized, repetitive digital experience that contradicts the ethos of personal luxury. Technical leaders at houses like LVMH or Kering should view this research not as a deterrent to using LLMs, but as a vital blueprint for responsible implementation. The path forward is a hybrid, systems-thinking approach that uses LLMs as powerful components within a rigorously engineered pipeline, not as standalone silver bullets for cold-start personalization.