An initial, informal evaluation of Moonshot AI's newly released Kimi 2.6 Thinking model suggests it is a capable open-weights reasoning model but still carries noticeable performance deficits when compared to the current state-of-the-art (SoTA) closed-source models like those from OpenAI or Anthropic.
The assessment, shared by researcher and professor Ethan Mollick, tested the model on a mix of complex reasoning and creative tasks. The most notable observation was the model's propensity for extensive "thinking" traces—it produced a 74-page reasoning document for the "Lem Test"—but ultimately delivered what was described as an "okay-ish" final answer. This indicates a potential disconnect between the volume of internal reasoning and the quality of the final output.
On creative and technical tasks, Kimi 2.6 Thinking showed basic competency but lacked polish:
- TiKZ Unicorn: Generated an "okay" vector graphic of a unicorn using the TiKZ LaTeX package.
- Twigl Shader: Created an "adequate" shader code for a "neogothic city in the waves" using the Twigl shading language.
The results point to a model that is functionally impressive for an open-weights release—capable of complex chain-of-thought reasoning—yet still exhibits the "rough edges" typical of models that trail the frontier. Its performance appears to sit in a tier below the fluency and precision of leading closed-source counterparts.
What Happened
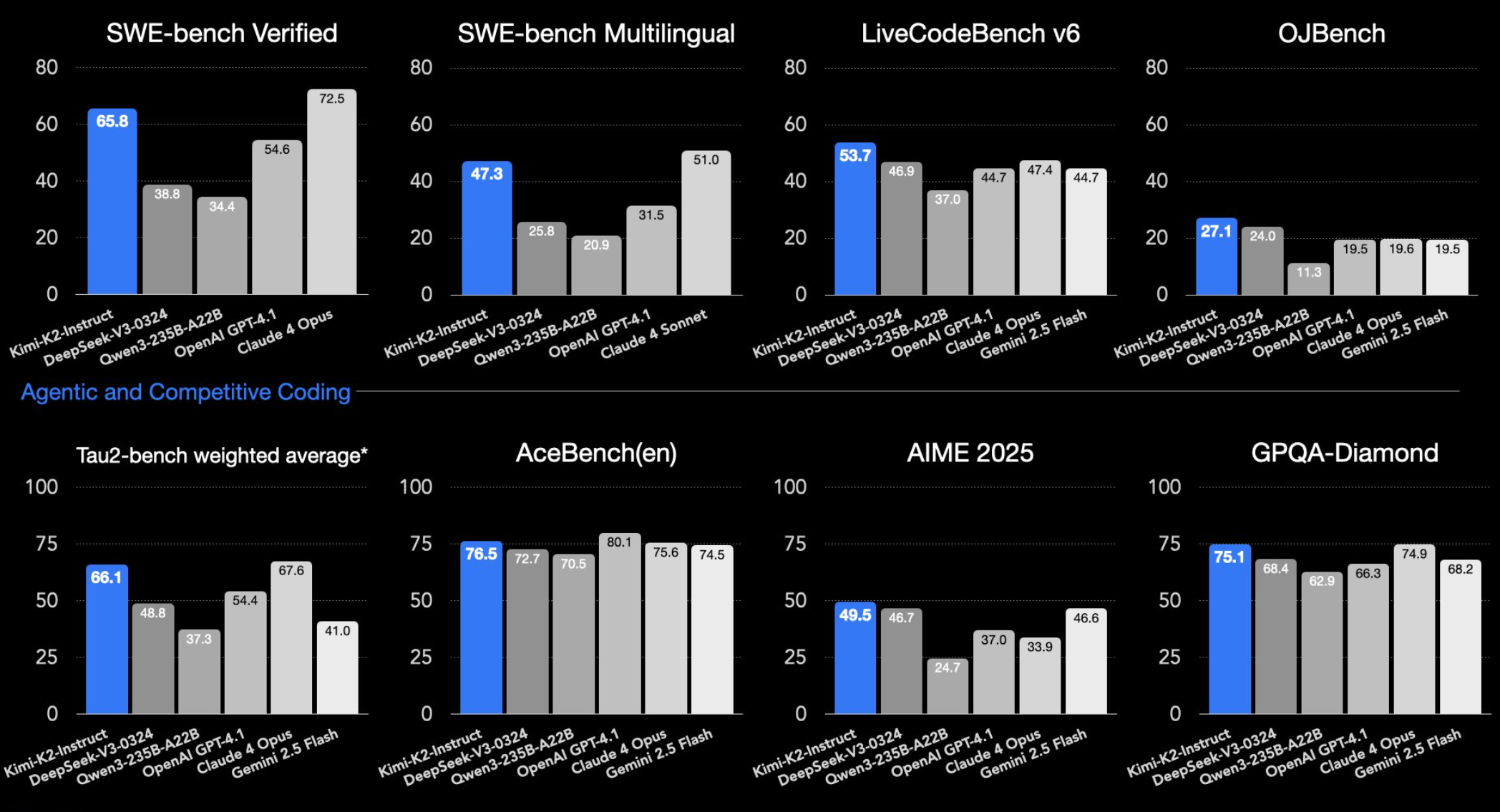
Moonshot AI has publicly released the weights for Kimi 2.6 Thinking, a model explicitly architected for enhanced reasoning processes. The shared evaluation is one of the first public benchmarks of its capabilities outside of controlled testing. The model was put through a series of challenging prompts designed to test both its structured problem-solving (the Lem Test) and its ability to execute on creative, technical instructions (generating code for graphics and shaders).
Context
This release continues the trend of AI labs open-sourcing reasoning-specialized models to compete with and provide alternatives to closed-source offerings. The "Thinking" designation typically refers to models trained or fine-tuned to externalize their reasoning steps, a technique shown to improve performance on complex tasks. However, maintaining both open weights and frontier-level performance remains a significant challenge, as the highest-performing models are often kept proprietary.
gentic.news Analysis
The performance profile of Kimi 2.6 Thinking fits a now-familiar pattern in the open-source landscape. We are seeing a proliferation of capable, specialized open-weight models that narrow the gap with closed SoTA in specific areas—here, reasoning trace length—but still fall short in delivering consistently refined, high-quality outputs. This was evident in our coverage of DeepSeek's earlier reasoning model releases, which also showed strong benchmarks but required careful prompting for optimal real-world use.
The key takeaway for practitioners is that Kimi 2.6 Thinking likely represents a highly useful tool for specific applications where extensive, inspectable reasoning chains are valuable, even if the final answer requires human refinement. Its release puts pressure on other open-source projects to match its reasoning depth while also highlighting the performance moat that closed-source labs continue to maintain. The real competition is no longer about basic capability, but about polish, reliability, and efficiency—areas where open-source models still struggle.
Looking at the broader KG context, Moonshot AI's release is part of a strategic push from Chinese AI firms to establish a strong presence in the global open-source ecosystem. Following significant funding rounds, these companies are leveraging open-weight models to build developer mindshare and alternative platforms to U.S.-dominated closed APIs. Kimi 2.6 Thinking should be seen as a bid for technical credibility in this high-stakes environment.
Frequently Asked Questions
What is Kimi 2.6 Thinking?
Kimi 2.6 Thinking is an open-weights large language model released by Moonshot AI, specifically designed with enhanced reasoning capabilities. It is trained to produce lengthy, step-by-step "thinking" traces before delivering a final answer, a technique aimed at improving performance on complex problems.
How does Kimi 2.6 Thinking compare to GPT-4 or Claude 3.5?
Based on this initial evaluation, Kimi 2.6 Thinking demonstrates promising reasoning depth for an open model but produces less polished and accurate final outputs compared to leading closed-source state-of-the-art models like OpenAI's GPT-4 or Anthropic's Claude 3.5 Sonnet. It exhibits "rough edges" in execution quality.
What are the main use cases for a model like Kimi 2.6 Thinking?
Its primary use case is for applications where the reasoning process is as important as the answer. This includes educational tools, complex code debugging where step-by-step logic needs verification, and research prototyping. Its open weights also allow for full customization and on-premises deployment, which is not possible with closed-source API models.
Why is there still a gap between open and closed model performance?
The performance gap persists due to several factors: closed-source labs typically have access to larger, more curated training datasets and vast computational resources for training. They also employ advanced, often undisclosed training techniques (like reinforcement learning from human feedback at scale) and can run continuous, live updates on their models post-deployment, which is harder to replicate in a one-time open-weight release.