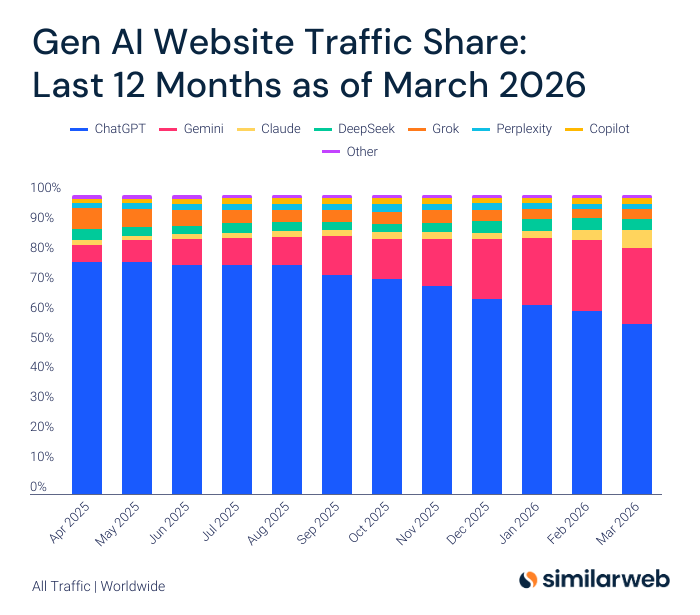
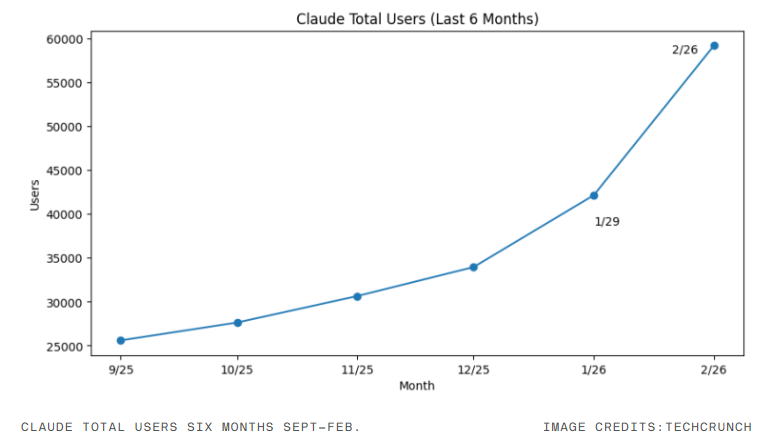
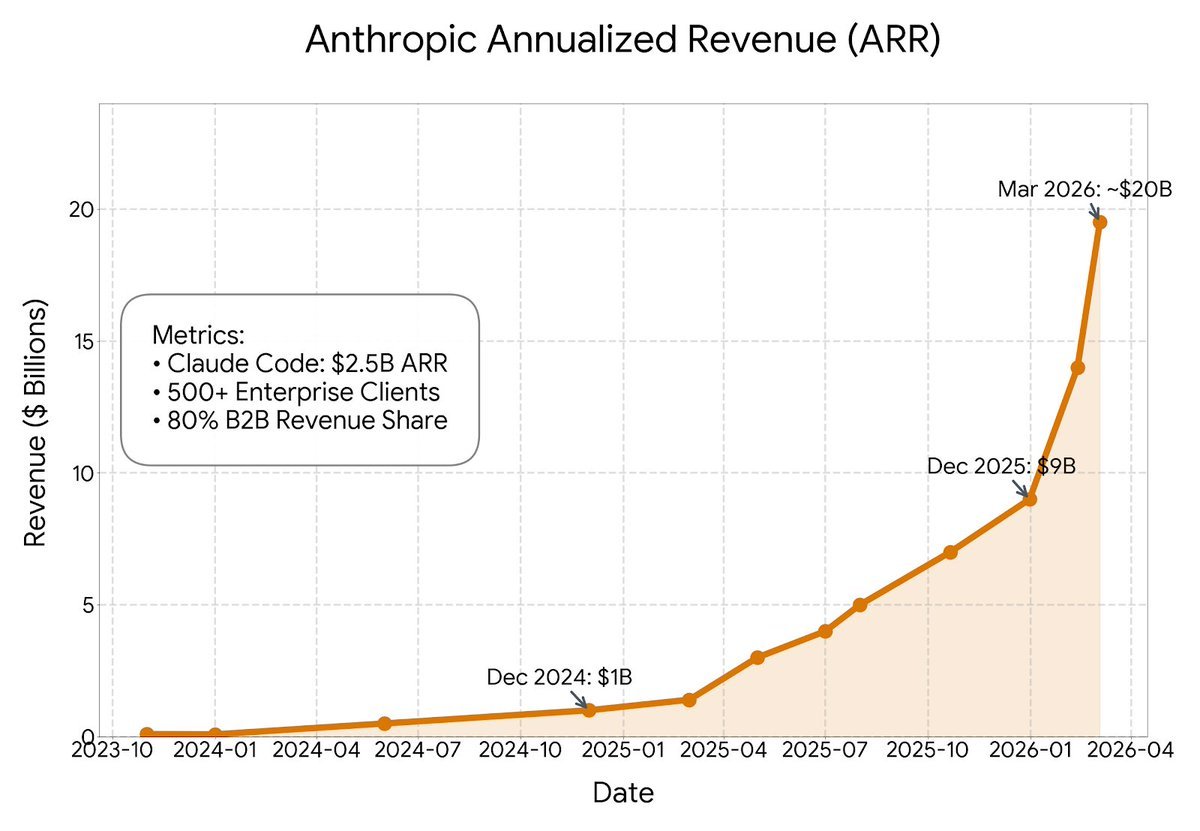
What Happened
AI researcher Ethan Mollick conducted an informal test of three major AI coding assistants—Claude (Anthropic), ChatGPT (OpenAI), and Microsoft Copilot—by giving them the same prompt: "make me a working strategy game in excel, it should have some form of graphics."
The results revealed significant differences in how each AI agent approached the task:
- ChatGPT successfully built a working strategy game with formulas and implemented a "smart" enemy AI opponent
- Claude created a game board but didn't build a complete game, instead positioning itself as a game master that would respond to player moves
- Microsoft Copilot created only a board with no functional game mechanics
Context
This test highlights the varying capabilities of current AI coding assistants when faced with complex, multi-step creative tasks that require both programming logic and visual design elements within a constrained environment like Microsoft Excel.
Excel represents a particularly challenging platform for game development due to its spreadsheet-based architecture, requiring creative use of formulas, conditional formatting, and potentially VBA (Visual Basic for Applications) to create interactive experiences.
The fact that ChatGPT implemented a "smart" enemy suggests it went beyond basic game mechanics to include opponent AI logic, which would require more sophisticated programming than simply creating a static game board.
This informal comparison follows similar benchmarking efforts by researchers and developers testing AI capabilities across different domains, though this particular test appears to be more qualitative than quantitative, focusing on functional outcomes rather than standardized metrics.