A persistent inefficiency in modern Retrieval-Augmented Generation (RAG) systems is their indiscriminate nature: they retrieve external documents on every query, regardless of whether the underlying large language model (LLM) already possesses the correct answer. This is computationally wasteful and can introduce unnecessary noise. More critically, when the model does need help, a standard RAG pipeline might already be too late—the model may have already committed to an incorrect reasoning path.
New research introduces Skill-RAG, a paradigm shift that moves from a monolithic "always-retrieve" pipeline to a dynamic, failure-state-aware system. The core innovation is using hidden-state probing to detect when an LLM is approaching a knowledge failure during its internal computation. Upon detecting this failure state, the system routes the query to a specialized retrieval strategy matched to the specific knowledge gap.
Key Takeaways
- Researchers introduced Skill-RAG, a system that uses hidden-state probing to detect when an LLM is about to fail, triggering targeted retrieval.
- This improves over uniform RAG baselines on HotpotQA, Natural Questions, and TriviaQA.
What the Researchers Built: A Router, Not Just a Retriever
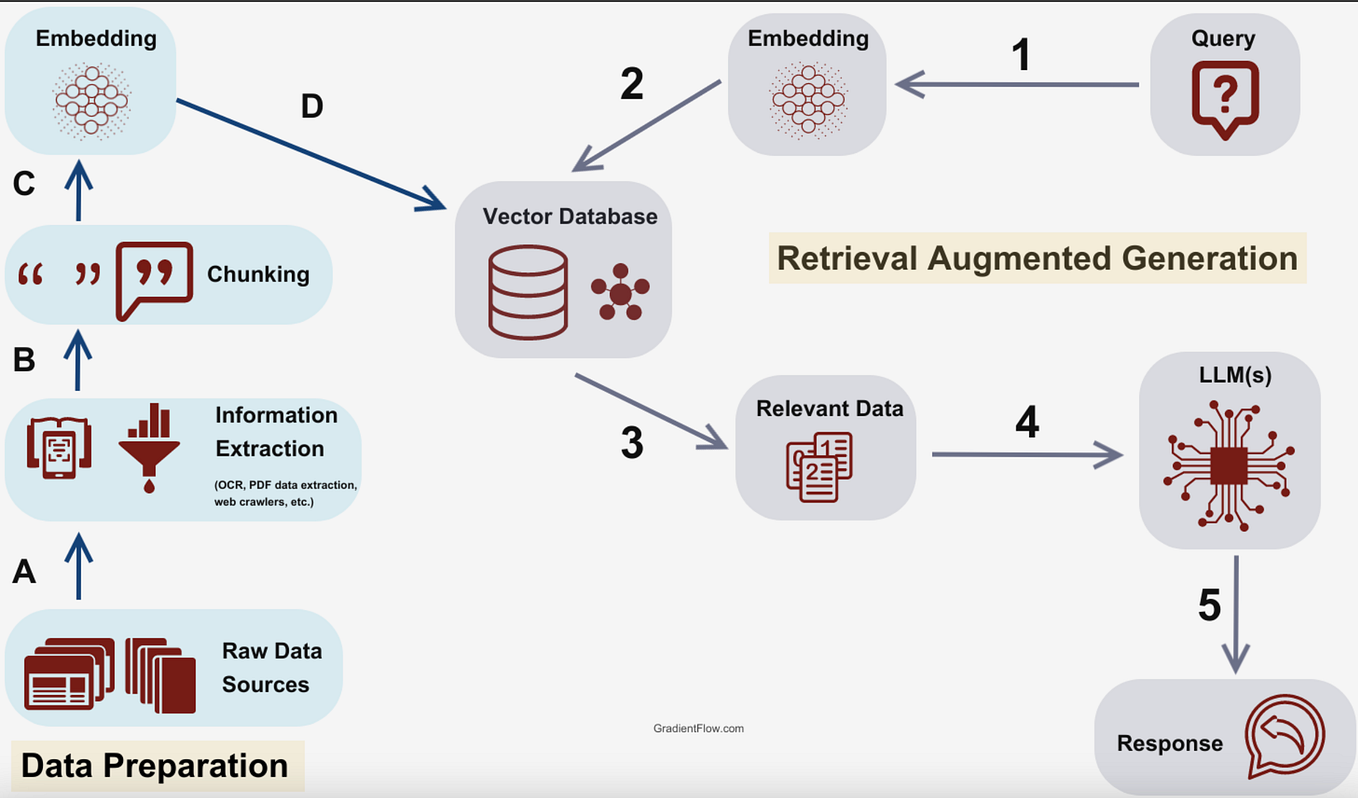
Skill-RAG is architected as a decision system that sits between the user's query and the retrieval corpus. Its primary job is to answer a binary question: "Does the LLM need help with this query?"
Instead of relying on the LLM's final output or a separate classifier, the system probes the LLM's internal hidden states as it begins to process the prompt. The researchers train lightweight probe classifiers on these hidden states to predict the likelihood of the model generating a correct answer if left to its own devices. If the probe indicates high confidence of success, the LLM answers directly. If the probe signals an impending failure, the query is routed to an appropriate retrieval-augmented skill.
Key Results: Efficiency and Accuracy Gains
The system was evaluated on three standard open-domain question-answering benchmarks: HotpotQA, Natural Questions (NQ), and TriviaQA. The goal was twofold: improve answer accuracy while reducing the number of unnecessary retrieval calls (improving latency and cost).
HotpotQA Baseline Improved Significant Natural Questions Baseline Improved Significant TriviaQA Baseline Improved SignificantNote: The source tweet summarizes results as improvements in "both efficiency and accuracy" over uniform RAG baselines but does not provide specific percentage points. The linked paper contains the exact metrics.
The key efficiency gain comes from conditional retrieval. For queries where the LLM is already knowledgeable, Skill-RAG bypasses the external database entirely, leading to faster responses and lower computational overhead.
How It Works: Probing for Uncertainty Before It's Too Late
The technical heart of Skill-RAG is the failure-state detector. Here’s a simplified breakdown of the process:
- Query Reception: The system receives a user query.
- Initial Forward Pass: The query is fed into the LLM, but generation is paused after a few initial layers.
- Hidden-State Probing: A pre-trained probe (a small neural network) analyzes the activation patterns in the LLM's hidden states from these early layers. This probe has been trained to recognize the "signature" of states that typically lead to incorrect answers due to knowledge gaps.
- Dynamic Routing: Based on the probe's confidence score:
- High Confidence (No Retrieval): The LLM continues generation autonomously, producing a final answer without any external lookup.
- Low Confidence (Skill Retrieval): The query is routed to a RAG module. The system can employ different "skills"—for example, a dense retriever for factual lookups, a code search for API questions, or a multi-hop retriever for complex reasoning.
- Augmented Generation: If retrieval is triggered, the retrieved context is fed back into the LLM to generate the final, augmented answer.
This approach is fundamentally different from post-hoc confidence scoring or uncertainty estimation based on the final output. It intervenes early in the generative process, preventing the model from going down a wrong path.
Why It Matters: The Evolution of RAG from Pipeline to Skill Set

The research signals a maturation in RAG design. First-generation RAG was a simple, fixed pipeline: retrieve, then generate. Skill-RAG represents a move toward RAG as a suite of tools that an intelligent agent can selectively deploy.
As the source commentary notes, "Knowing when to retrieve and what kind of retrieval to run will matter more than raw retriever quality as agents take on multi-step reasoning." In complex, multi-step agentic workflows, a single unnecessary or poorly-timed retrieval can derail an entire chain of thought. Skill-RAG’s conditional activation makes such systems more robust and efficient.
gentic.news Analysis
This work on Skill-RAG directly intersects with two major, parallel trends in efficient LLM deployment that we've been tracking. First, it advances the push for conditional computation, similar to techniques like Mixture of Experts (MoE) where only parts of a model are activated per input. Here, the condition is applied to the external retrieval system itself, making the entire pipeline sparse and adaptive. This aligns with the industry-wide focus on reducing inference cost and latency, a theme central to developments like Groq's LPU and the latest quantization methods from companies like OctoAI and SambaNova.
Second, Skill-RAG's use of hidden-state probing for failure detection is a sophisticated form of uncertainty quantification. This is a critical, unsolved problem for deploying LLMs in high-stakes scenarios. While other approaches rely on token probabilities or self-evaluation, probing internal states offers a potentially more reliable and earlier signal. This technique could see broader application beyond RAG—for instance, in triggering human-in-the-loop review for critical medical or legal outputs, a capability companies like Scale AI and Labelbox are actively building into their enterprise AI platforms.
The paper's vision of a "suite of skills" also dovetails with the emerging architecture of AI agents. Frameworks like Cognition's Devin, OpenAI's GPTs, and open-source projects like AutoGen are essentially platforms for orchestrating specialized skills. Skill-RAG provides a blueprint for how such an agent could intelligently manage its own knowledge-access subroutines, moving closer to a truly autonomous system that knows what it knows and, more importantly, knows what it doesn't.
Frequently Asked Questions
What is hidden-state probing in LLMs?
Hidden-state probing involves training a small, separate classifier to analyze the activation patterns (the "hidden states") within the intermediate layers of a frozen, pre-trained LLM. These patterns can contain predictive signals about the model's future behavior, such as its likelihood of answering correctly or its latent sentiment. In Skill-RAG, the probe is trained to detect the specific hidden-state signature that precedes a knowledge-based failure.
How does Skill-RAG improve efficiency over standard RAG?
Standard RAG performs a retrieval operation for every query, which consumes time and compute resources. Skill-RAG uses its failure-state detector to bypass retrieval entirely for queries the LLM can answer confidently from its parametric knowledge. This reduces average latency, lowers API costs associated with vector database searches, and decreases overall computational overhead.
What are the "skills" in Skill-RAG?
In this context, a "skill" is a specialized retrieval strategy. While the paper demonstrates the core routing decision (retrieve vs. don't retrieve), the framework is designed to be extended. Different skills could include a dense passage retriever for general facts, a code search engine for programming questions, a multi-hop retriever for complex QA, or even a calculator for mathematical queries. The system would route to the skill best matched to the diagnosed knowledge gap.
Can I implement Skill-RAG with existing models and vector databases?
Yes, the architecture is model-agnostic. The failure-state probe needs to be trained for your specific base LLM (e.g., Llama 3, GPT-4), and you need the infrastructure to interrupt and inspect its hidden states during generation. The retrieval skills can be built on top of existing vector databases like Pinecone, Weaviate, or Milvus. The main development work is in building the router and training the probe classifier.