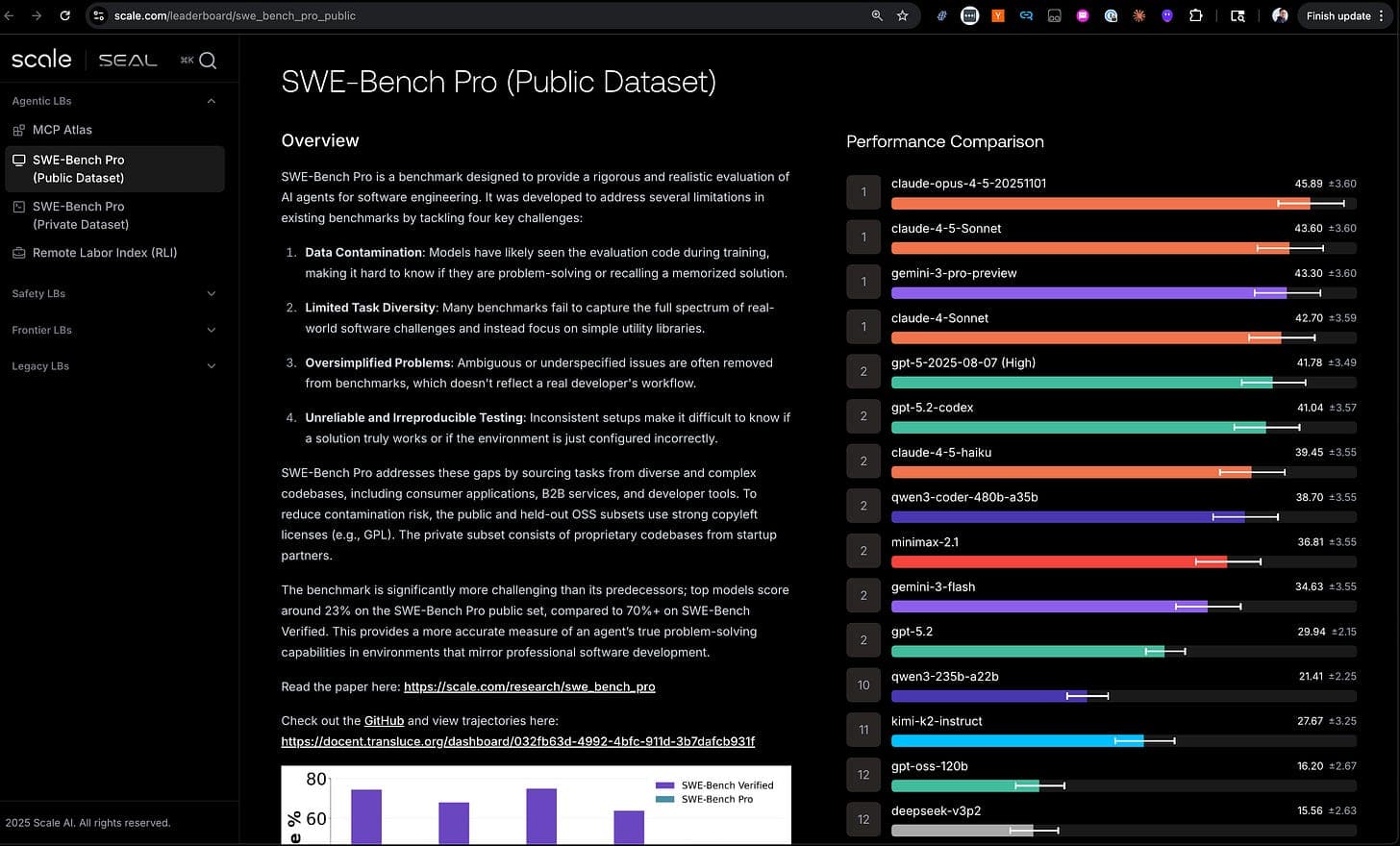
A massive, unidentified artificial intelligence model with 754 billion parameters has been uploaded to the Hugging Face platform, occupying 1.51 terabytes of storage space. The discovery, highlighted by developer Simon Willison, points to the continued scaling of model sizes available in public repositories, though the model's origin, architecture, and intended use remain unspecified.
What Happened
On April 15, 2026, Simon Willison posted a brief observation on X (formerly Twitter): "754B parameters, 1.51TB on Hugging Face." The post includes a screenshot showing a model repository on Hugging Face named "754B-1.51TB," created by a user named "bigmodel." The repository description is empty, and no accompanying paper, license, or detailed model card has been provided. The repository contains what appears to be model weights in the .safetensors format, split across multiple files.
The sheer size—1.51TB for the model weights alone—places it among the largest models ever made publicly accessible via a platform like Hugging Face. For context, Meta's Llama 3 400B parameter model is estimated to require roughly 800GB of storage in half-precision (FP16) format. This new upload is nearly double that storage footprint.
Context: The Scale of Public Models
Hugging Face has become the de facto hub for sharing open-source and open-weight AI models. The platform hosts everything from small, fine-tuned models to massive foundational ones. The appearance of a 754B-parameter model is a significant data point in the trend of increasing model scale.
- Parameter Count: At 754 billion parameters, this model is larger than many widely known open models, including Meta's Llama 3 400B and 700B variants, DeepSeek's 671B Coder model, and the original GPT-3 (175B). It approaches the scale of models like Google's PaLM (540B) and rumored internal successors.
- Storage Footprint: The 1.51TB size suggests the weights are likely stored in a lower precision format like 4-bit or 8-bit quantization to reduce the storage and memory requirements for what would otherwise be a multi-terabyte model in FP16. Even quantized, this size presents significant challenges for download and inference, requiring high-end hardware with substantial GPU memory.
The lack of accompanying documentation is unusual for a model of this scale. Typically, releases of this magnitude are accompanied by research papers detailing the architecture (e.g., a Mixture of Experts setup), training data, and performance benchmarks. The anonymous nature of the upload raises questions about its provenance, licensing, and potential performance.
Technical and Practical Implications
For AI engineers and researchers, this upload is more of a curiosity than an immediately usable tool. Key unknowns include:
- Architecture: Is it a dense transformer or a more efficient Mixture of Experts (MoE) model? MoE models can have large parameter counts but activate only a fraction per token, making them more feasible to run.
- Training Data: The model's capabilities are entirely unknown without knowledge of its training corpus.
- Performance: There are no published benchmarks on standard evaluations like MMLU, GPQA, or coding tasks.
- License: The absence of a license makes it legally ambiguous for commercial or even research use.
Practically, loading and running a 1.51TB model is non-trivial. It would likely require model parallelism across dozens of high-memory GPUs (e.g., H100s or B200s) or optimized inference systems like vLLM or TGI with tensor parallelism. For most organizations and individuals, the barrier to inference is prohibitively high.
gentic.news Analysis
This mysterious upload fits into two ongoing, parallel trends in the AI ecosystem as of early 2026. First, it underscores the persistent drive for scale as a differentiator. Even as research explores more efficient architectures and training methods, the largest labs continue to push parameter counts into the trillions for proprietary models. A public 754B model, while massive, now sits in the upper-mid tier of known model sizes, behind rumored frontier models from OpenAI, Google, and others that may exceed 1 trillion parameters.
Second, it highlights the wild west nature of model sharing. Hugging Face's open platform enables incredible collaboration and democratization, but it also allows for anonymous, undocumented drops of enormous files. This creates a tension between open access and responsible release practices. Without a model card, benchmarks, or a license, this model is essentially a digital artifact—its value and safety are unverified. This contrasts sharply with the detailed, safety-focused release processes of major organizations like Meta for Llama 3 or Google for Gemma, which we covered extensively in 2024 and 2025.
The timing is also notable. This follows a period of intense activity in the open-source large language model (LLM) space throughout 2025, with organizations like Mistral AI, Alibaba's Qwen team, and 01.AI releasing increasingly capable models in the 100B-400B parameter range. A 754B model, if proven capable, could potentially disrupt the current open-weight leaderboard, but its anonymous and undocumented status leaves its competitive impact entirely speculative. It may simply be a test upload, a partial model, or an artifact from a research project that was never intended for public use.
Frequently Asked Questions
What is a 754B parameter model?
A 754-billion-parameter model is an artificial intelligence system, typically a large language model, with 754 billion adjustable weights or "parameters." These parameters are learned from vast amounts of text data and define the model's knowledge and capabilities. More parameters generally correlate with increased performance on complex tasks, but also demand vastly more computational power for training and inference.
How can I run a 1.51TB AI model?
Running a model of this size is extremely challenging and expensive. You would need a server cluster with multiple high-end GPUs (like NVIDIA H100 or B200) with a total GPU memory exceeding 1.51TB, likely using techniques like model parallelism to split the model across devices. For most individuals and even many research labs, the hardware requirements are currently prohibitive. Specialized inference servers and frameworks like vLLM or TensorRT-LLM would be necessary to attempt to load it.
Who uploaded the 754B model to Hugging Face?
The model was uploaded by a user named "bigmodel" on Hugging Face. The user's profile provides no identifying information, and the model repository lacks any documentation, paper, or license. The origin and authorship of the model are completely unknown. It could be from an academic group, a private company, or an individual researcher.
Is the 754B model safe to use?
Without any documentation, it is impossible to assess the model's safety. Key safety considerations include its training data (which could contain biased or harmful content), its propensity to generate unsafe outputs, and the presence of any built-in safety mitigations or alignment tuning. The lack of a license also creates legal uncertainty. Until the authors provide documentation and benchmarks, the model should be treated as an unverified artifact.