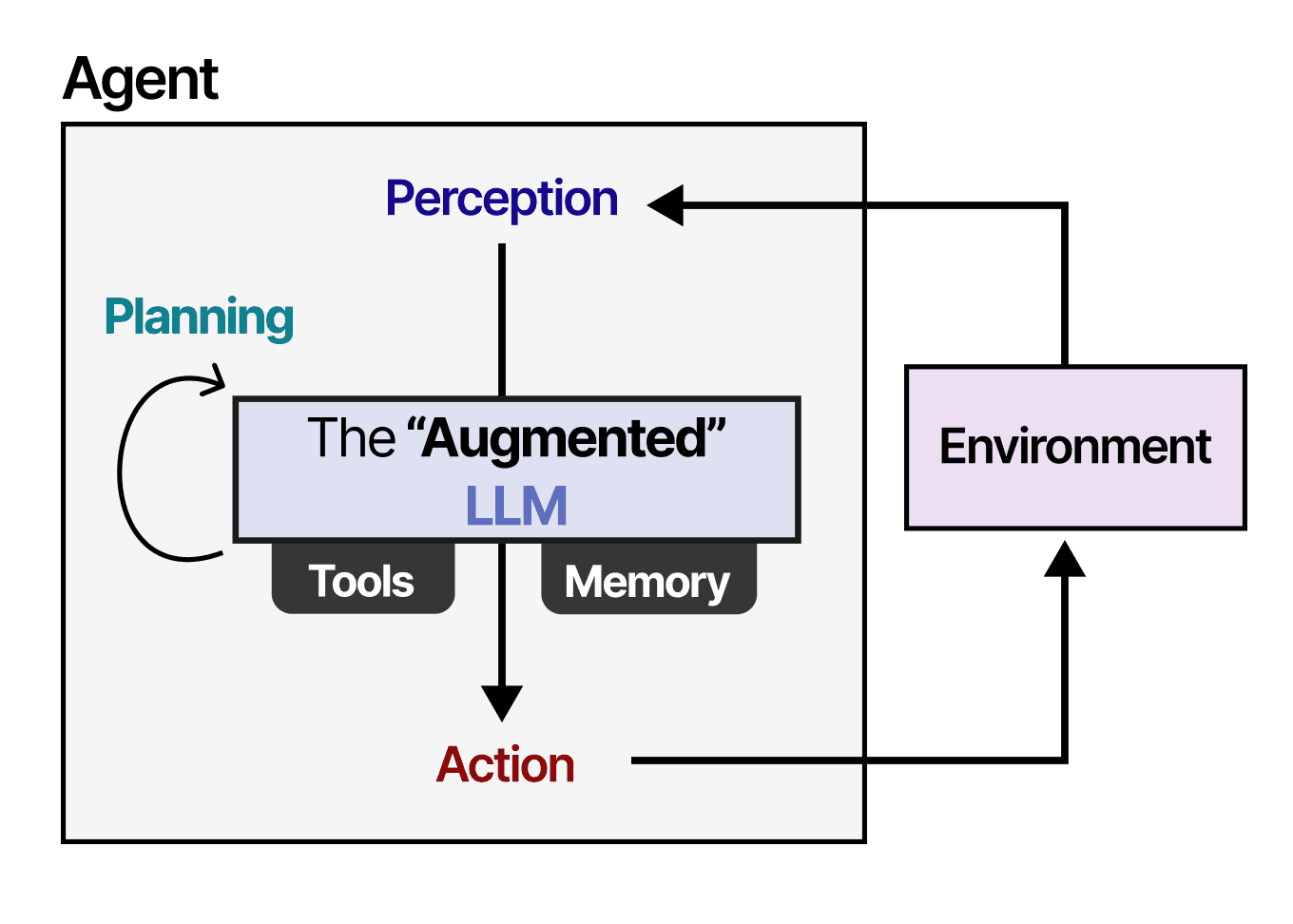
What Happened
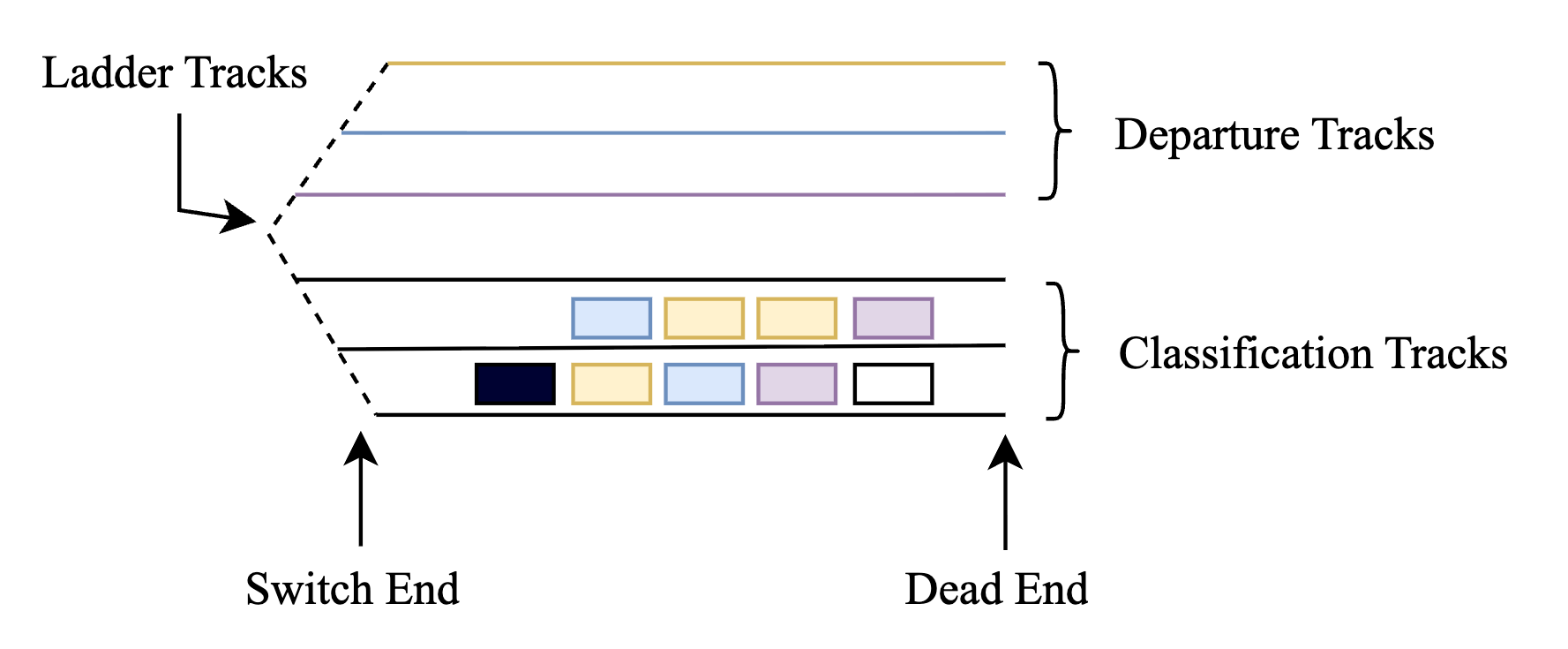
A new research paper, published on arXiv, introduces a Hybrid Heuristic-Reinforcement Learning (HHRL) framework designed to solve a notoriously difficult class of logistics optimization problems: railcar shunting. In freight railyards, planners must disassemble incoming trains and reassemble railcars into new outbound trains. This process is constrained by the physical layout of classification tracks, which can operate as either stacks (LIFO access) or queues (FIFO access), making optimal planning a combinatorial nightmare.
The paper tackles a specific, complex scenario requiring the assembly of multiple outbound trains using two locomotives in a yard with two-sided track access. The core innovation is a problem decomposition strategy: the two-sided, two-locomotive problem is broken down into two simpler subproblems, each with one-sided access and a single locomotive. The HHRL framework then solves these by integrating:
- Railway-specific heuristics: Domain knowledge to guide the search and reduce the problem's state-action space.
- Reinforcement Learning (Q-learning): An RL agent learns optimal shunting policies through exploration and reward, accelerated by the heuristic guidance.
The results from numerical experiments indicate that this hybrid approach is both efficient and effective in producing high-quality solutions for these complex shunting problems, outperforming more naive methods.
Technical Details
The problem's complexity stems from its state space. With multiple tracks, locomotives, and railcars needing specific final configurations, the number of possible states and actions explodes. Pure RL approaches would struggle with exploration and sample efficiency.
The HHRL framework's key technical contributions are:
- State-Action Space Reduction: The domain heuristics prune obviously poor actions and aggregate similar states, making the learning problem tractable for Q-learning.
- Guided Exploration: Instead of random exploration, the heuristics provide a "warm start," directing the RL agent toward promising regions of the search space. This drastically reduces the number of training episodes required to find a good policy.
- Modular Decomposition: By splitting the two-sided problem into coupled one-sided problems, the framework can leverage solutions and policies developed for the simpler, well-studied one-sided shunting case.
This represents a sophisticated application of neuro-symbolic AI principles, where symbolic knowledge (the heuristics) is combined with a sub-symbolic learning system (RL) to solve a real-world, physical constraint satisfaction problem.
Retail & Luxury Implications
At first glance, railcar shunting seems worlds apart from luxury retail. However, the core AI methodology—hybridizing domain-specific rules with reinforcement learning to solve complex, constrained sequencing and layout problems—has direct, powerful analogs in retail logistics and inventory management.
Potential Application 1: Warehouse Picking & Replenishment Optimization.
A high-value warehouse for a luxury group (e.g., storing handbags, watches, ready-to-wear) faces a similar "shunting" problem. Items are stored in specific locations (racks, bins, secure cages). Picking orders for store replenishment or e-commerce fulfillment requires navigating this 3D grid under constraints: item fragility, security levels, picker travel time, and the order in which items are placed/retrieved from a cart or tote (a LIFO/FIFO dynamic). An HHRL-style system could learn optimal picking routes and storage policies that minimize time and handling risk, far surpassing static rule-based systems.
Potential Application 2: In-Store Inventory Rearrangement & Visual Merchandising.
Flagship stores frequently rearrange displays and back-of-house stock. Moving high-value items between the sales floor, stockroom, and secure vaults is a constrained sequencing problem with a high cost of error (damage, misplacement). A model could plan the most efficient and secure sequence of moves, respecting physical pathways and security protocols, much like planning locomotive moves in a railyard.
Potential Application 3: Global Container & Air Freight Consolidation.
For luxury houses moving goods between manufacturing sites, regional distribution centers, and stores worldwide, the consolidation of shipments into containers or air pallets is a high-stakes optimization puzzle. It involves weight, volume, value, destination, and customs constraints. The hybrid RL approach could dynamically optimize these loading plans, adapting to disruptions and maximizing asset utilization.
The gap between this academic research and production is significant but bridgeable. The retail problem would require its own set of heuristics (developed with logistics managers) and a careful definition of the state/action space and reward function (e.g., reward for speed, penalize risk of damage). The paper demonstrates the architectural blueprint for solving this class of problem.