Agent4POI achieves a 23.2% relative gain over the strongest baseline on three POI benchmarks. The framework generates dynamic, context-conditioned multimodal representations at inference time, proving static embeddings cannot satisfy context-sensitive ranking.
Key facts
- 23.2% relative gain over strongest baseline on three POI benchmarks.
- Degrades 7.5% under context-shift vs 16-17% for baselines.
- Outperforms content-based baseline by up to 2.4x in cold-start.
- Uses four-phase LLM agent with frozen model and cross-modal chain-of-thought.
- Semantic caching system enables low-latency inference-time ranking.
The Static Embedding Bottleneck
Existing multimodal POI recommenders encode each point of interest once into a fixed vector, pre-computed without any knowledge of the user's current situation. This design fundamentally precludes reasoning about why the same cafe affords solo work on Monday but group celebration on Friday evening. Agent4POI formally proves that no pre-computed encoder can satisfy context-sensitive ranking under standard bilinear scoring [According to the arXiv preprint].
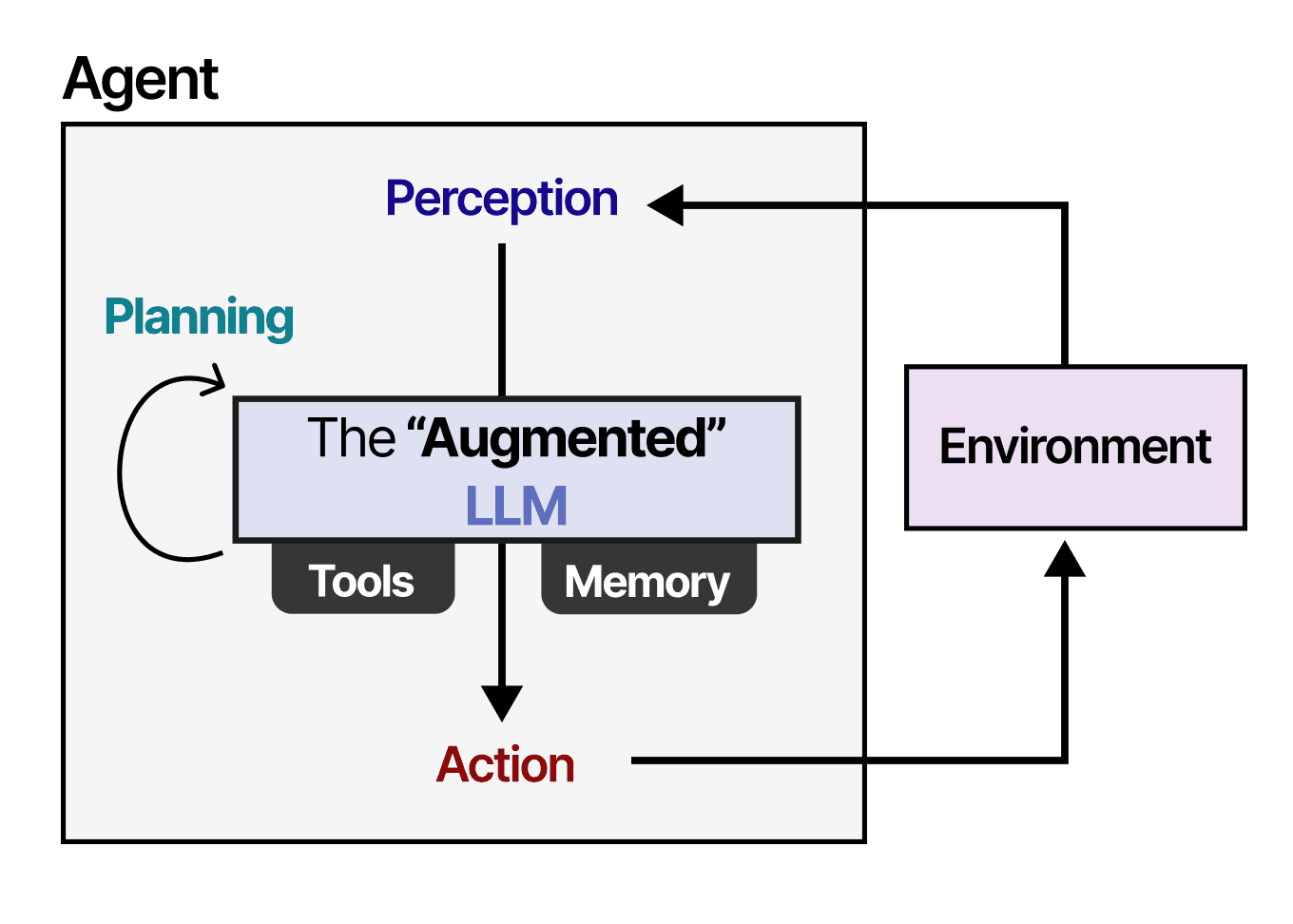
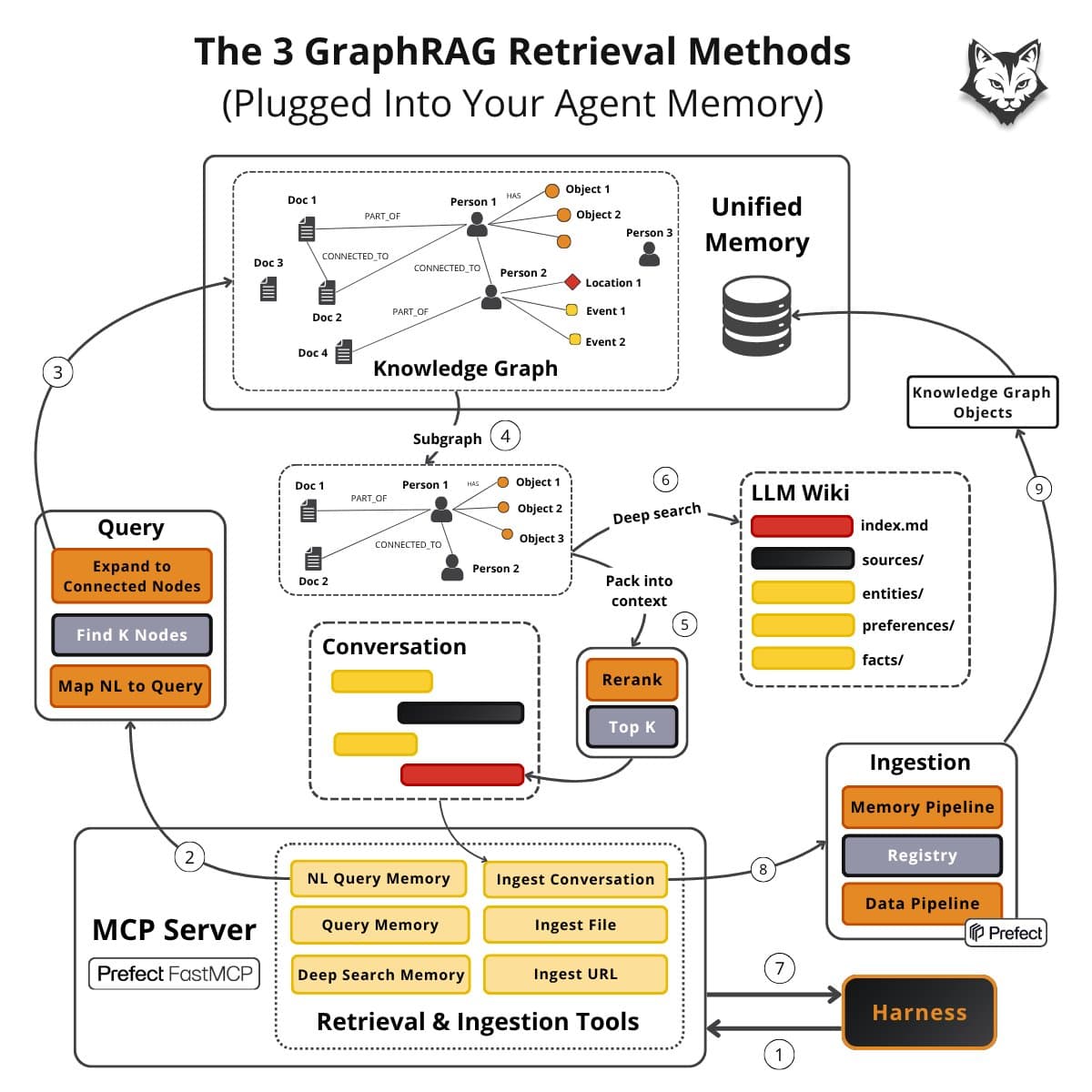
Four-Phase Inference Pipeline
Agent4POI inverts the computation: given a situational context (e.g., time, day, companion), a frozen LLM generates context-specific affordance queries in Phase 1. Phase 2 executes a five-step cross-modal chain-of-thought over image, review, and metadata evidence. The resulting uncertainty-aware affordance representation is grounded in Gibsonian affordance theory. Phase 3 structures these cross-modal verdicts into an uncertainty-adjusted representation, which Phase 4 aligns with user preferences via a semantic caching system for low-latency ranking.

Benchmark Results and Cold-Start Advantage
On three POI benchmarks across standard, cold-start, and context-shift configurations, Agent4POI achieves a 23.2% relative gain over the strongest baseline. Under context-shift (e.g., recommending for a Monday morning vs Friday evening), Agent4POI degrades by only 7.5%, while the strongest baselines degrade by 16-17%. In cold-start scenarios, Agent4POI outperforms the best content-based baseline by up to 2.4x, whereas ID-based methods fail to generalize entirely.
Unique Take: Inference-Time Computation vs. Pre-Computation
The core insight here is that for context-sensitive tasks like POI recommendation, the dominant paradigm of pre-computing embeddings is mathematically insufficient. Agent4POI's approach—deferring representation until query time—mirrors a trend seen in large language models themselves, where retrieval-augmented generation and dynamic prompting have replaced static fine-tuning. The trade-off is latency: Agent4POI uses a semantic caching system to mitigate the cost of on-the-fly generation, but the paper does not disclose end-to-end inference latency numbers.
Broader Implications for Recommender Systems
This work challenges the assumption that static embeddings are sufficient for any recommendation task where context matters. The formal proof suggests that any system using pre-computed item representations under bilinear scoring is provably incapable of context-sensitive ranking. This could push the entire recommender systems field toward inference-time computation, especially for applications like real estate, travel, or event planning where context heavily influences relevance.
What to watch
Watch for follow-up work that quantifies Agent4POI's end-to-end inference latency against static embedding baselines. If latency is within acceptable bounds (e.g., <100ms per query), expect rapid adoption in production POI recommenders at companies like Google Maps or Meta.