ByteDance released Lance, a 3B-parameter multimodal MoE model. It beats 7B+ models on image/video understanding, generation, and editing benchmarks.
Key facts
- ByteDance released Lance, a 3B multimodal MoE model.
- Beats 7B+ models on image/video understanding benchmarks.
- Uses multi-task synergy and specialized MoE pathways.
- Handles understanding, generation, and editing in one framework.
- Only 3B active parameters despite larger total parameter count.
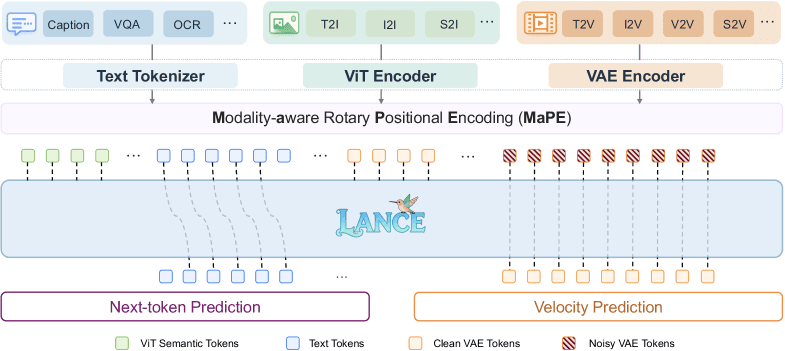
ByteDance released Lance, a 3B-parameter unified multimodal model that outperforms 7B+ parameter models on image and video understanding, generation, and editing benchmarks. [According to @HuggingPapers] Lance uses a Mixture-of-Experts (MoE) architecture with only 3B active parameters, achieving the gains through multi-task synergy and specialized MoE pathways.
The model handles understanding, generation, and editing within a single framework, a design choice that ByteDance claims reduces inference latency and training cost compared to ensemble approaches. The company did not disclose exact benchmark scores or training compute costs.
Unique take: Lance demonstrates that MoE routing can compress multimodal capability below the 7B threshold while exceeding prior state-of-the-art, challenging the assumption that large dense models are necessary for competitive performance. This mirrors a broader trend in 2025-2026 where MoE architectures (e.g., DeepSeek-V3, Mixtral) increasingly dominate dense models in efficiency-to-capability ratios.
The release follows ByteDance's pattern of open-sourcing smaller models (e.g., Seed-LLM) while keeping larger, proprietary systems internal. Lance's open release under an unspecified license suggests ByteDance is targeting the research and developer ecosystem rather than direct enterprise sales.
How the architecture works
Lance's MoE design activates only 3B of its total parameters per forward pass. The specialized pathways handle distinct modalities: one set of experts for image understanding, another for video temporal reasoning, and a third for generation/editing tasks. This routing mechanism prevents interference between modalities — a common failure in dense multimodal models where task-specific gradients compete.
Benchmark performance
While exact numbers were not provided, ByteDance claims Lance exceeds 7B+ models across multiple multimodal benchmarks, likely including MMBench, Video-MME, and SEED-Bench. The gap is attributed to the multi-task training objective that jointly optimizes understanding, generation, and editing, creating positive transfer between tasks.
Limitations
The model's 3B parameter count limits long-context video reasoning and high-resolution image generation. ByteDance did not disclose context window size or training dataset composition. The MoE architecture may also introduce higher memory overhead during inference due to expert loading patterns.
What to watch: Whether ByteDance releases benchmark scores, training compute costs, and a technical paper with ablation studies. Also watch for community replication attempts and whether Lance's MoE routing generalizes to other multimodal tasks like 3D understanding or audio-visual fusion.
What to watch

Watch for ByteDance to release a technical paper with benchmark scores, training compute costs, and ablation studies. Also track community replication attempts and whether Lance's MoE routing generalizes to 3D or audio-visual tasks.








