
An AI That Does AI Research By Itself
A team in Shanghai just built something that should get every AI researcher's attention.
ASI-Evolve is an AI system that does AI research — autonomously. It reads scientific papers, comes up with ideas, designs experiments, runs them, analyzes results, and uses what it learned to do better next time. Over and over. Without anyone guiding it.
They pointed it at three fundamental challenges in AI, and it outperformed humans on all three.
The system is fully open-sourced on GitHub.
Challenge 1: Design a Better Neural Architecture
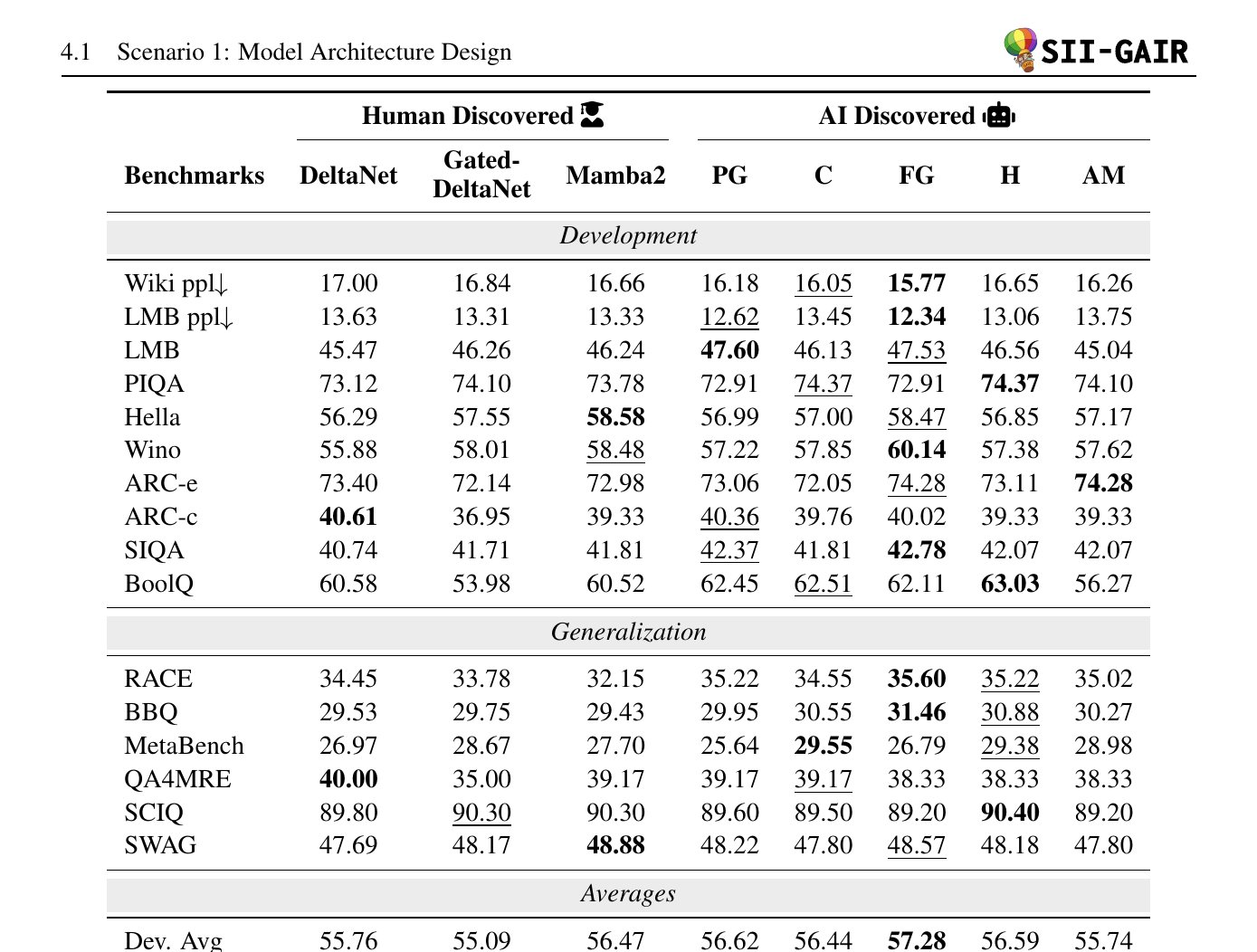
Human researchers spent years improving linear attention models. The best recent human gain was +0.34 points (Mamba2 over DeltaNet).
ASI-Evolve was given the same task. Over 1,773 autonomous rounds, it:
- Generated 1,350 candidate architectures
- Found 105 that beat the human baseline
- The best one scored +0.97 points — nearly 3x the human improvement
- On development benchmarks: 57.28% average accuracy vs DeltaNet's 55.76%
- On generalization (out-of-distribution): 45.40% vs DeltaNet's 44.74%
The AI discovered a consistent pattern: adaptive routing that adjusts computation based on input content. Five standout architectures include PathGateFusionNet (hierarchical budget allocation), ContentSharpRouter (learnable temperature routing), and AdaMultiPathGateNet (token-level sparse gating with entropy penalties to prevent mode collapse).
The evaluation was rigorous: small models (~20M params) explored first, then promising candidates scaled to 340M params, and top architectures validated at **1.3B parameters on 100B tokens** across 16 benchmarks.
Challenge 2: Improve Training Data
Bad training data = bad models. Cleaning data at scale is tedious, expensive, and hard to get right.
ASI-Evolve designed its own data cleaning strategies for Nemotron-CC, a 672-billion-token pretraining corpus spanning math, computer science, medicine, and STEM. The results:
- +18.64 points on MMLU (the standard knowledge benchmark)
- +18.80 points on CSQA (commonsense reasoning)
- +13.48 points on MedQA (medical knowledge)
- +3.96 points average across 18 benchmarks
Same 3B-parameter model. Same 500B training tokens. The only difference was the AI-designed data curation — and it crushed every human-designed strategy including DCLM, FineWeb-Edu, and Ultra-FineWeb.
The system converged on cleaning-focused approaches without being told what to do: targeted noise removal (HTML artifacts, duplicates, PII), format normalization, and domain-aware preservation rules. The 2.93-point gap between best and worst AI strategies shows iterative refinement matters — it's not one-shot generation.
Challenge 3: Invent a Better Learning Algorithm
This is the hardest one. Designing how models learn requires deep mathematical reasoning.
ASI-Evolve was told to improve on GRPO (Group Relative Policy Optimization), the leading RL method for LLM training. Over 300 evolutionary rounds using Qwen-3-14B, it invented 10 new algorithms that beat GRPO, with the best gaining:
- +12.5 points on AMC32 (67.5 to 80.0)
- +11.67 points on AIME24 (20.00 to 31.67)
- +5.04 points on OlympiadBench (45.92 to 50.96)
Two standout algorithms show genuine theoretical innovation:
Algorithm A (Pairwise Asymmetric Optimization) — instead of comparing against a group mean, it calculates advantage by averaging tanh-normalized pairwise reward differences. It uses an asymmetric clipping window that adjusts based on advantage sign, plus "High-Impact Gradient Dropout" that masks gradients for the most influential tokens to prevent overfitting.
Algorithm B (Budget-Constrained Dynamic Radius) — uses percentile-based normalization and a "Global Update Budget" that mathematically guarantees total policy update magnitude stays within bounds, stabilizing training on noisy data.
It Works in Medicine Too
To test real-world transfer, they applied an ASI-Evolve architecture to drug-target interaction (DTI) prediction — a core problem in AI-driven drug discovery.
Starting from the DrugBAN architecture and initialized with ~80 papers on graph neural networks and molecular modeling, the system evolved over 100+ rounds. Results across 4 datasets (BindingDB, BioSNAP, Human, C.elegans):
- +1.91 AUROC on BindingDB (94.15 to 96.06)
- +6.94 AUROC for unseen drugs (79.15 to 86.09) — the cold-start scenario
- +3.56 AUROC for unseen proteins (82.26 to 85.82)
- Beat all 6 human-designed baselines including TransformerCPI, PSICHIC, and ColdStartCPI
The best architecture introduced three innovations: Sinkhorn Attention (optimal-transport-based attention preventing collapse), Domain-Specific Marginalization (separate aggregation over drug and protein substructures), and Top-k Sparse Gating (learnable selection focusing on relevant interaction patterns).
This proves ASI-Evolve's designs aren't just AI-benchmark tricks — they carry real scientific value.
How It Works
ASI-Evolve follows a learn-design-experiment-analyze cycle:

- Cognition — a knowledge base initialized with insights from ~100-150 research papers. Provides human prior knowledge so it doesn't explore blindly.
- Researcher — samples context from past experiments, retrieves relevant cognition items via embedding search, generates a new candidate with a natural-language motivation.
- Engineer — runs the experiment. Includes a static check agent (validates before expensive training), a debug agent (handles runtime errors), and a novelty check (filters duplicates).
- Analyzer — receives the full experimental output (loss dynamics, benchmark breakdowns, efficiency traces) and distills it into a compact report. This is key — not just a scalar score, but structured feedback.
- Database — stores everything: motivation, code, results, analysis. Supports multiple sampling strategies (UCB1, greedy, MAP-Elites island, random).
Ablation: What Actually Matters?
The team ran controlled ablation studies:
Without the Analyzer: The system starts well (thanks to cognition) but hits a plateau. Without structured feedback, improvements become sporadic. The Analyzer's ability to interpret multi-dimensional experimental results is critical for sustained progress.
Without the Cognition base: Cold-start is much slower. The system takes longer to find productive regions. But it still evolves — proving the core learn-experiment-analyze loop works even without human priors, just slower.
Sampling strategy matters: UCB1 (exploitation-heavy) combined with the cognition base reached SOTA on circle packing in just 17 steps. MAP-Elites (diversity-preserving) needed 79 steps for the same score. With good priors, you can be greedy.
The framework also works across different base models: GPT-5-mini and Qwen3-32B both converge to similar performance, showing the evolution capability isn't tied to a specific model family.
Speed: Fastest Evolutionary Framework
On the circle packing benchmark (a standard test for evolutionary frameworks):
AlphaEvolve Gemini 2.0 Flash + Claude 3.7 — 2.6359 OpenEvolve Gemini 2.0 Flash + Claude 3.7 460 2.6343 LoongFlow DeepSeek-R1 — 2.6360 SkyDiscover GPT-5 89 2.6360 ASI-Evolve GPT-5-mini 17 2.6360ASI-Evolve reaches SOTA in 17 rounds — the fastest. And it uses a cheaper model (GPT-5-mini vs GPT-5 or Gemini+Claude combos).
Why This Matters
This is the first system to demonstrate AI-driven discovery across all three pillars of AI development — architecture, data, and algorithms — in a single framework.
Among the 105 winning architectures:
- 51.7% built on the cognition base (human prior knowledge)
- 38.2% emerged from accumulated experience (the system's own past experiments)
- 10.1% were genuinely novel
As evolution proceeds, experience-derived designs rise to 44.8% while novelty drops to 6.6% — the system progressively distills its own useful patterns.
The recursive loop is closed. AI is building AI. And on these benchmarks, it's already better at it than we are.
Caveats
- Still needs human-curated initialization (100-150 papers)
- Operates at the mechanism level, not hardware-optimized CUDA kernels — wall-clock efficiency of discovered architectures after full optimization is unvalidated
- Each experiment costs real GPU hours (architecture search = 2000 training steps per candidate at ~20M params)
- LLM-as-a-Judge scores penalize computationally expensive designs, which could bias against some viable architectures
- The +0.97 architecture gain is in a high-saturation regime where any improvement is hard
Open Source
- Code: github.com/GAIR-NLP/ASI-Evolve
- Paper: arxiv.org/abs/2603.29640
- Team: Weixian Xu, Tiantian Mi, Yixiu Liu, Yang Nan, Zhimeng Zhou, Lyumanshan Ye, Lin Zhang, Yu Qiao, Pengfei Liu — Shanghai Jiao Tong University (SJTU), SII, GAIR
Frequently Asked Questions
What is ASI-Evolve?
ASI-Evolve is an open-source agentic framework for AI-for-AI research from Shanghai Jiao Tong University. It autonomously runs the full scientific research loop — reading papers, forming hypotheses, designing experiments, executing them, and analyzing results. It discovered 105 neural architectures better than human designs, improved training data by 18 points on MMLU, and invented RL algorithms outperforming GRPO by 12.5 points on competition math.
Can ASI-Evolve replace human AI researchers?
Not yet. It needs human-curated knowledge to start (insights from 100+ papers) and operates at the mechanism design level. About 52% of its best discoveries built directly on human prior knowledge. It augments human research rather than replacing it — but the gap is narrowing.
Is ASI-Evolve open source?
Yes, fully open-sourced at github.com/GAIR-NLP/ASI-Evolve including code, cognition base, and all experimental configurations.
How does ASI-Evolve compare to AlphaEvolve and OpenEvolve?
ASI-Evolve is broader (covers architecture + data + algorithms vs code-level optimization), faster (SOTA in 17 rounds vs 460+ for OpenEvolve), and uses a cheaper model (GPT-5-mini vs Gemini+Claude combos). On circle packing, ASI-Evolve matches or exceeds all prior frameworks while being the fastest to converge.
What base models does ASI-Evolve use?
The framework works with multiple LLMs. Results were demonstrated with GPT-5-mini and Qwen3-32B, both converging to similar performance. The evolution capability is not tied to a specific model family.
Does ASI-Evolve work outside of AI research?
Yes. When applied to drug-target interaction prediction in biomedicine, an ASI-Evolve-designed architecture achieved +6.94 AUROC improvement for unseen drugs, beating all human-designed baselines across 4 benchmark datasets.








