What Happened
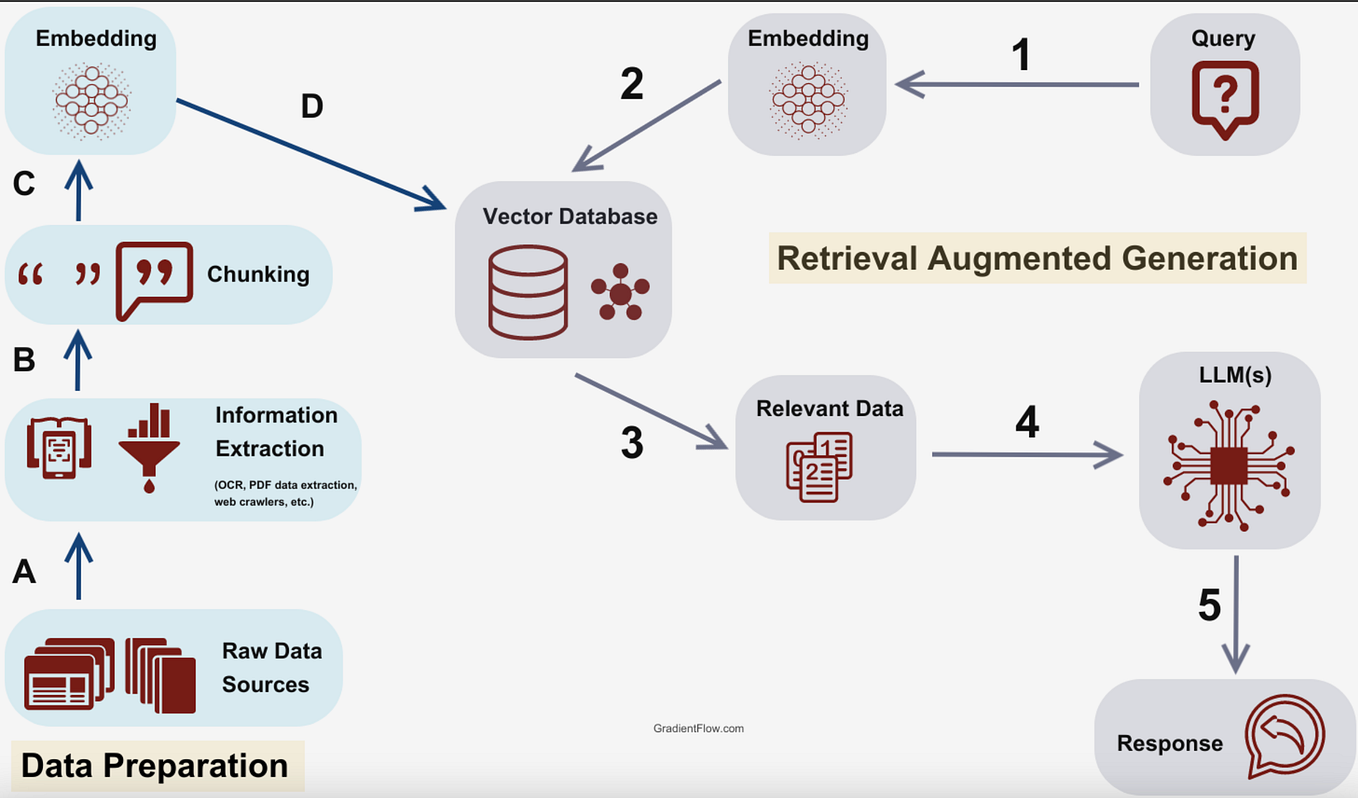
A developer shared a hands-on tutorial on building a minimal recommendation engine using only embeddings, without relying on deep learning frameworks or large-scale infrastructure. The project, documented on Medium, focuses on item-to-item recommendations by computing similarity between pre-trained embeddings.
Technical Details
The core idea is straightforward: use pre-trained embeddings (e.g., from a language model or a domain-specific encoder) to represent each item as a vector. Then, for a given item, find the nearest neighbors in embedding space using cosine similarity or Euclidean distance. This approach captures semantic relationships—items with similar meanings or properties cluster together.
Key steps:
- Obtain embeddings for each item (e.g., product descriptions, movie titles, or user queries).
- Store embeddings in a simple vector database or in-memory structure.
- For a query item, compute distances to all other items and return the top-N most similar.
The developer notes that this method works well for small to medium-sized catalogs (e.g., hundreds to thousands of items) and can be implemented in a few lines of Python using libraries like numpy and scikit-learn.
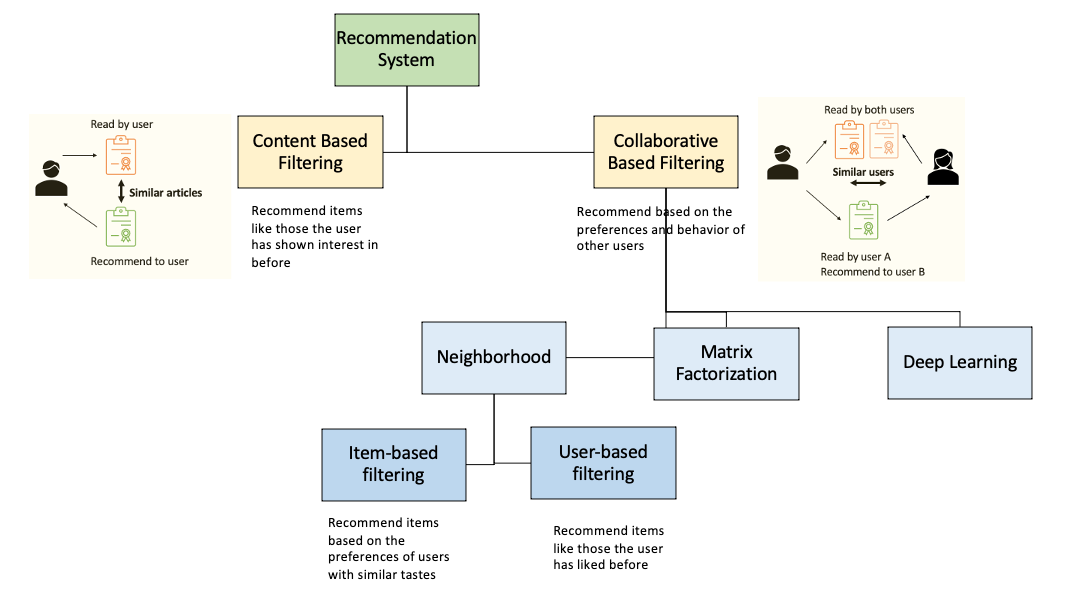
Retail & Luxury Implications
This approach has direct relevance for retail and luxury e-commerce teams looking to prototype or deploy lightweight recommendation features without heavy investment in ML infrastructure.
Use Cases
- Product recommendations on small catalogs: For boutique luxury brands with limited SKUs (e.g., 500–5,000 items), an embeddings-only engine can power "You May Also Like" or "Complete the Look" features.
- Personalized search results: Embeddings can rank search results by semantic relevance to user intent, not just keyword matches.
- Cross-sell and upsell: Compute similarity between product embeddings to suggest complementary items (e.g., a handbag that pairs with shoes).
Limitations
- Scalability: Nearest-neighbor search becomes slow beyond tens of thousands of items without approximate nearest neighbor (ANN) indexing.
- Cold start: New items without embeddings require a pre-trained model that can encode them.
- Personalization: Pure embeddings-based recommendation lacks user history or collaborative filtering signals.
Business Impact
For luxury retailers, the primary benefit is speed-to-value: a developer can build a working prototype in a day, test it with real users, and iterate. The cost is minimal—no GPU, no large datasets, no complex pipelines. If the prototype shows a 5–15% lift in click-through or conversion, it justifies investing in a more sophisticated system.
Implementation Approach
- Choose an embedding model: For product descriptions, use
all-MiniLM-L6-v2from Sentence Transformers (free, 384-dim). For images, use a pre-trained ResNet or CLIP. - Generate embeddings: Encode each product title/description/image into a vector.
- Store and index: Use FAISS (Facebook AI Similarity Search) for fast retrieval, or just
numpyarrays for small catalogs. - Build a simple API: Expose a
/recommend?item_id=Xendpoint returning top-K similar items.
Complexity: Low. A single developer can implement this in a week.
Governance & Risk Assessment
- Privacy: Embeddings from text descriptions do not contain PII unless product data includes customer names. Safe.
- Bias: Embeddings may reflect biases in the pre-trained model (e.g., gender stereotypes in product categories). Test for fairness.
- Maturity: This is a prototype-level approach. For production at scale, invest in a proper recommendation platform (e.g., Amazon Personalize, Google Recommendations AI) or a hybrid model.
gentic.news Analysis
This article is a breath of fresh air for teams tired of over-engineered recommendation systems. The "embeddings-only" approach is not novel—it's a well-known technique in information retrieval—but the developer's clear, minimal implementation makes it accessible to any engineer with basic Python skills.
For luxury and retail, the key insight is that not every problem requires a multi-million dollar ML pipeline. A small team can build a recommendation engine that works well enough to test hypotheses and gather user feedback. The 13 prior articles on Recommender Systems in our knowledge graph confirm that industry interest is high, but many implementations are overkill for niche catalogs.
Where this approach falls short is personalization and scale. It treats every user equally—no collaborative filtering, no user history. For a luxury brand with 10,000 products and 100,000 monthly visitors, it's a solid starting point. For a mass-market retailer with millions of SKUs and billions of interactions, you need something more robust.
Recommendation: Use this tutorial as a quick-start guide. Build the prototype, measure impact, and then decide whether to invest in a full-scale system.
Source: medium.com