ColPali, a late-interaction retrieval architecture, eliminates OCR and chunking for document-heavy RAG by encoding each 16×16 image patch of a PDF page into a 128-dim vector. On the ViDoRe benchmark, it outperforms prior SOTA systems across most document domains, but at an 8× storage cost per page.
Key facts
- ColPali encodes each 16×16 image patch into a 128-dim vector.
- A full A4 page produces ~1000 patch vectors.
- ViDoRe benchmark: ColPali outperforms prior SOTA across most document domains.
- Storage cost is roughly 8× more than bi-encoder setups.
- No OCR, chunking, or captioning step required.
Key Takeaways
- ColPali eliminates OCR and chunking for document-heavy RAG by encoding each 16×16 image patch into a 128-dim vector.
- It outperforms prior SOTA on the ViDoRe benchmark but costs 8× more storage per page.
The Three Patterns of Multimodal RAG
Text-only RAG fails on enterprise data: tables become garbled text, charts vanish, and scanned invoices lose stamps and handwriting. [According to the Multimodal RAG article] there are three architectural patterns, each with distinct tradeoffs.
Pattern 1: Extract-then-Embed (Late Fusion)
This is the most widely deployed pattern today. Process each modality through a specialized extractor — GPT-4V for image captions, Whisper for audio — then embed using standard text embedders like OpenAI ada-002 or BGE-M3. Operationally simple, reuses existing text RAG infrastructure. But it loses information at every extraction step: a bar chart captioned as "a bar chart showing revenue trends" is not the same as the chart. Captioning via GPT-4V during ingestion is expensive and slow at scale.
Pattern 2: Native Multimodal Embedding (Early Fusion)
Embed each modality directly into a shared vector space using a cross-modal encoder like CLIP (512-dim) or Meta's ImageBind (6 modalities). No captioning step means faster ingestion. But CLIP's 512-dim embedding is low-capacity for complex visual reasoning — it degrades on technical diagrams and scientific plots unless fine-tuned. Suitable for image-heavy corpora like product catalogs or medical scans.
Pattern 3: ColPali / Late Interaction — The Current Best for Documents
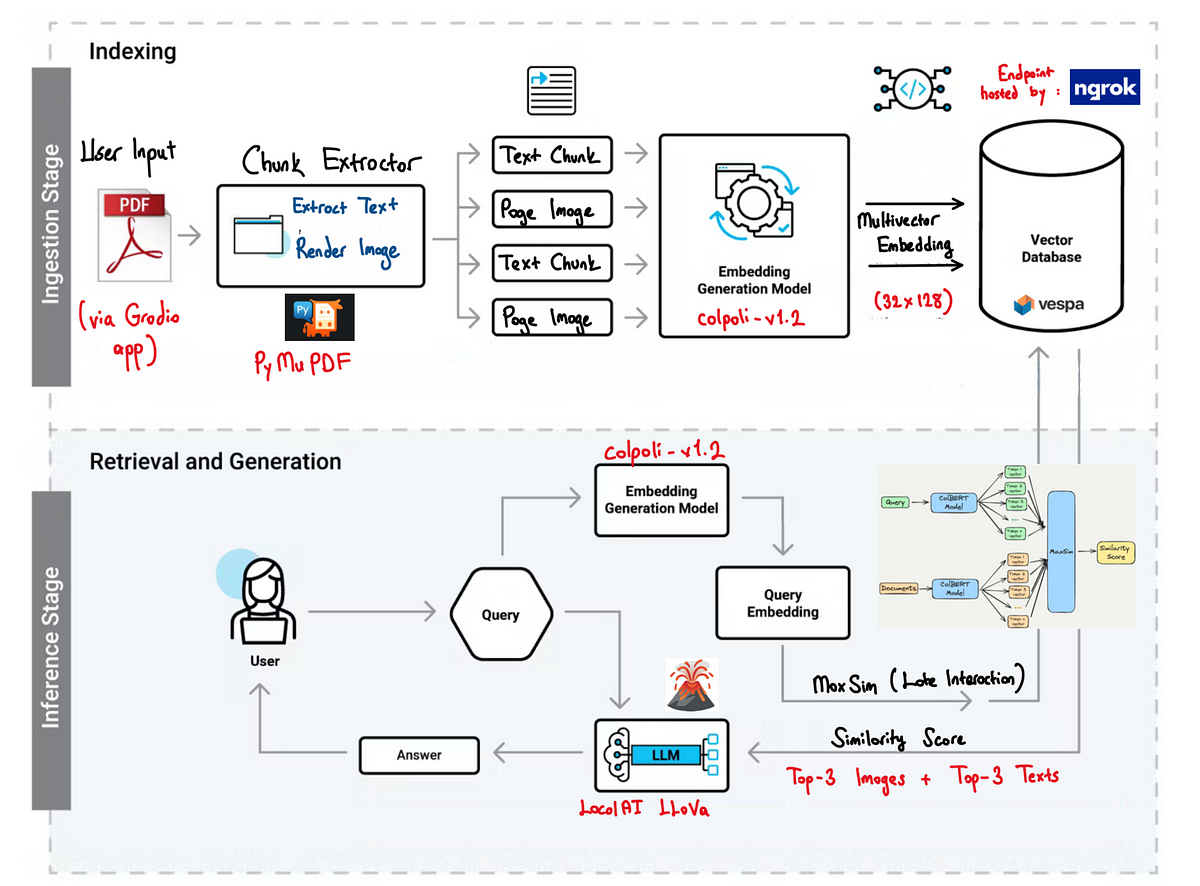
ColPali encodes each 16×16 image patch of a document page into its own vector, producing a multi-vector representation per page. A full A4 page yields ~1000 patch vectors. At query time, it computes maximum similarity across all patch-query token pairs using a MaxSim late interaction mechanism (borrowed from ColBERT).
The critical difference from CLIP: instead of one vector per page, you get one vector per 16×16 image patch.
Ingestion pipeline: screenshot the PDF page (via pdf2image), pass through PaliGemma-3B VLM to get patch grid embeddings [n_patches × 128-dim], store in a multi-vector index (PLAID or Qdrant with multi-vector support). No OCR, no chunking, no captioning. The VLM sees the actual rendered page — table borders, font sizes, column layout, embedded figures.
What works: Dramatically outperforms OCR-based pipelines on documents with complex layouts — legal contracts, medical forms, financial reports with embedded charts. The ViDoRe benchmark shows ColPali outperforming prior SOTA retrieval systems across most document domains. Ingestion pipeline is drastically simpler — the "longest part" in OCR-based pipelines is entirely eliminated.
What breaks: Multi-vector storage is expensive. Each page generates ~1000 128-dim vectors vs. a single 1536-dim vector in bi-encoder setups — roughly 8× more storage. At millions of documents, PLAID-style compressed indices or quantization are needed. Query latency is higher per query, though for corpus sizes under a few hundred thousand pages the overhead is on the order of milliseconds.
When to use it: Document-heavy enterprise use cases — legal, finance, medical. Any corpus where layout, tables, charts, and typography carry semantic meaning. Not a good fit for retrieval over natural images (CLIP is better there) or pure text corpora (standard text RAG beats it).
Audio — The Modality Nobody Gets Right
Two approaches exist: transcription-first (Whisper large-v3 → text RAG) or native audio embeddings (ImageBind, CLAP). Transcription is lossy — paralinguistic information is gone. Native embeddings preserve tone and emphasis but require fine-tuning on domain-specific audio.
The Unique Take

ColPali represents a structural shift: it treats document pages as images, not text. This inverts the traditional RAG assumption that text extraction must precede retrieval. For enterprise workloads where layout carries meaning (legal contracts, financial reports), ColPali's patch-level approach is meaningfully superior despite the 8× storage overhead. The tradeoff is clear: pay 8× in storage cost to eliminate the brittle OCR/chunking pipeline entirely.
What to watch
Watch for enterprise adoption of ColPali in legal and financial document retrieval systems over the next 6 months. Key metric: whether multi-vector storage costs drop via PLAID-style compressed indices, and whether Qdrant or Pinecone add native multi-vector support.








