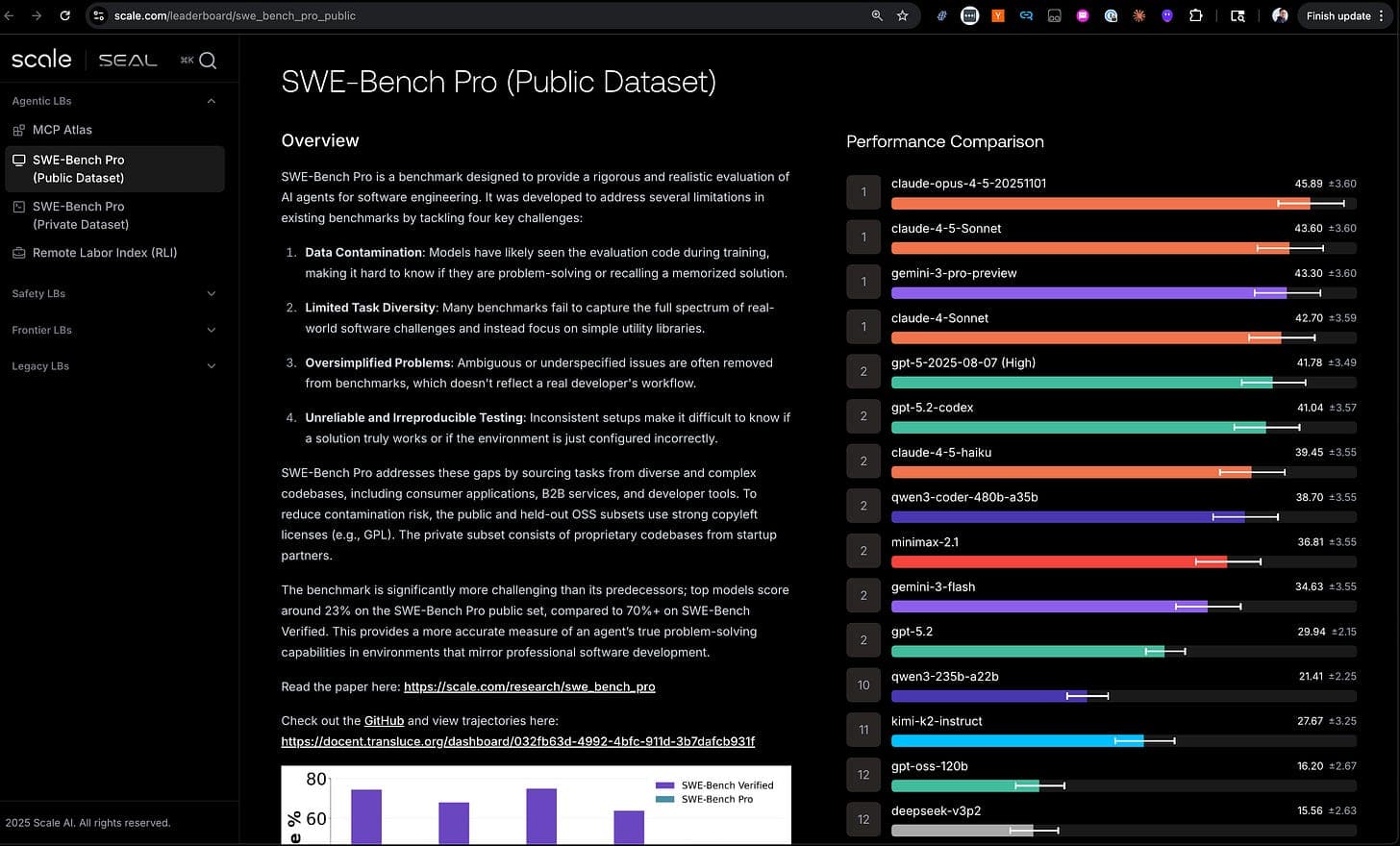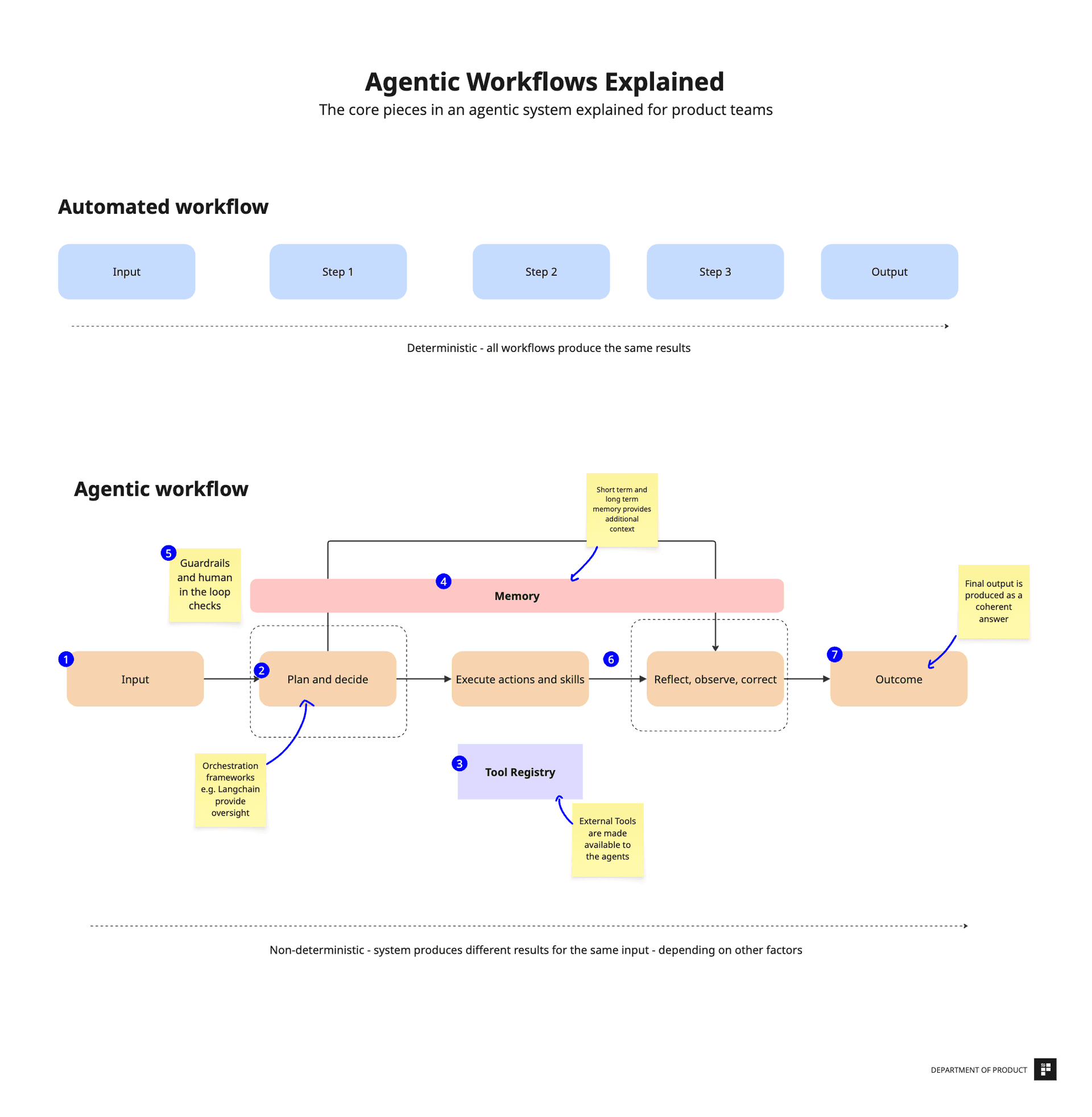
A new paper from @dair_ai demonstrates that a full agentic workflow can be distilled into model weights, achieving roughly 100x lower inference cost. The result points to a potential shift in how autonomous AI agents are deployed at scale.
Key facts
- 100x lower inference cost claimed
- Full agentic workflow distilled into weights
- Paper shared by @dair_ai on X
- No benchmark results disclosed
- No model or training details provided
A paper highlighted by @dair_ai and retweeted by @omarsar0 claims that an entire agentic workflow—typically requiring multiple LLM calls, tool-use loops, and planning steps—can be distilled directly into model weights. The resulting model runs inference at roughly 100x lower cost than the original multi-step pipeline. [According to @omarsar0]
The one unique take here is that distillation may finally make agentic systems economically viable for high-throughput applications like customer support, code review, and data pipelines. Prior work on agentic workflows (e.g., ReAct, Reflexion, AutoGPT) relies on repeated LLM invocations, each consuming tokens and latency. Compressing that into a single forward pass changes the unit economics entirely: a workflow costing $0.10 per task could drop to $0.001.
The paper does not disclose the base model, the benchmark tasks, or the distillation technique used. Without those details, it is impossible to assess the generality of the result. The claim of 100x cost reduction is plausible given known distillation results (e.g., Hinton et al. 2015, Sanh et al. 2019), but the lack of specificity means the claim cannot be independently verified. The community should watch for the full arXiv preprint and any accompanying ablation studies.
How distillation compresses agentic workflows
Distillation typically trains a smaller student model to mimic the output distribution of a larger teacher model. In this case, the teacher is an agentic workflow—a sequence of LLM calls, tool invocations, and decision points. The student learns to output the final answer directly, bypassing the intermediate steps. This is similar to the chain-of-thought distillation work by Magister et al. 2023, but applied to tool-use and multi-step planning.
What's missing from the announcement
The tweet provides no quantitative benchmark results (e.g., success rate on AgentBench, WebArena, or SWE-Bench), no model size comparison, and no training compute budget. Until those numbers surface, the claim remains a provocative teaser rather than a validated result. [The source material is limited to a single tweet]
What to watch
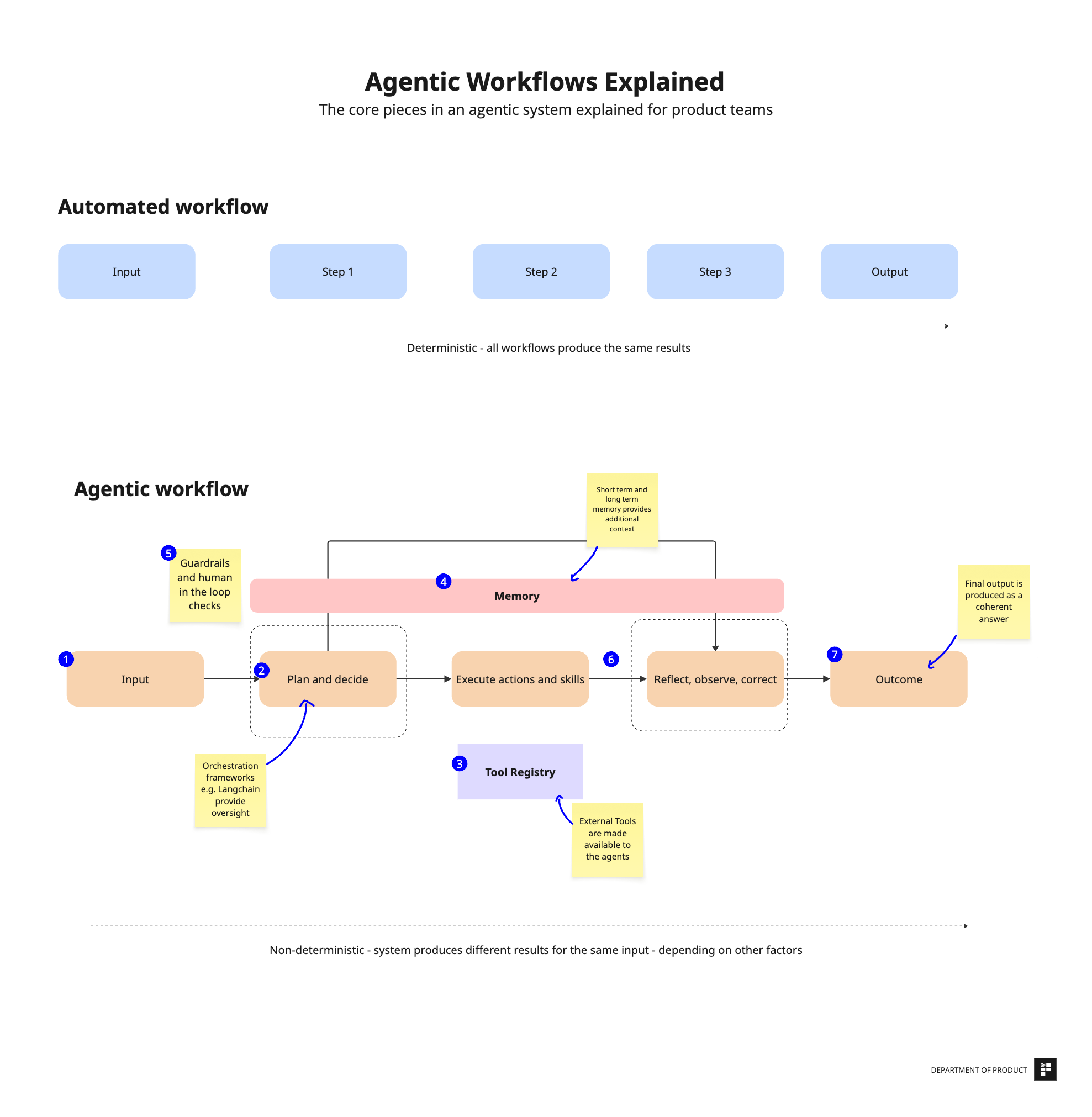
Watch for the full arXiv preprint release and any accompanying benchmark scores on AgentBench or SWE-Bench. If the method generalizes across tasks, it could reshape agent deployment economics. If not, it joins the pile of unsubstantiated distillation claims.