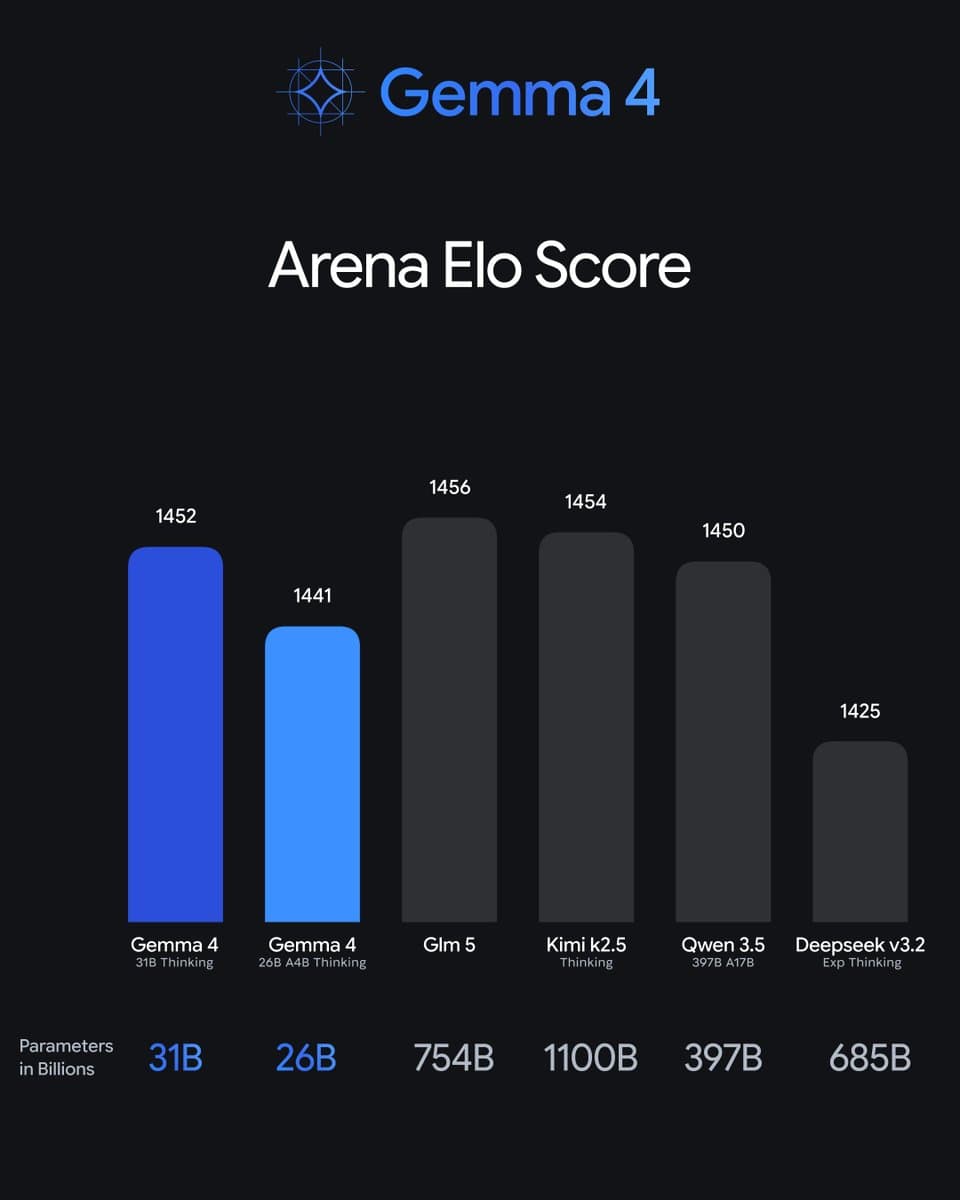
A single social media post from a developer has sparked significant discussion in the AI community by claiming that a relatively small 31-billion parameter model called "Gamma" is outperforming Alibaba's massive 397-billion parameter Qwen 3.5 model.
What Happened
On March 26, 2026, developer @kimmonismus posted on X (formerly Twitter): "Gamma 31b model outperforming Qwen 3.5 397B is nuts to me." The post included a link that appears to show benchmark results, though the specific metrics and evaluation framework aren't detailed in the public post.
The claim is striking because it suggests a model with approximately 1/13th the parameters of Qwen 3.5 is achieving superior performance. Qwen 3.5 397B, released by Alibaba's Qwen team in early 2025, represents one of the largest openly available language models and has consistently ranked among the top performers on standard benchmarks like MMLU, GSM8K, and HumanEval.
Context
If accurate, this development would challenge conventional wisdom about model scaling. The dominant paradigm in large language models has been that performance scales predictably with parameter count, compute budget, and training data size. Recent research from organizations like DeepSeek and Google has shown that architectural innovations and training techniques can improve efficiency, but a 31B model surpassing a 397B model would represent one of the most dramatic efficiency gains publicly documented.
Little public information exists about the "Gamma" model mentioned in the post. The name doesn't correspond to any major announced model from leading AI labs like OpenAI, Anthropic, Google, Meta, or Microsoft. This suggests Gamma might be:
- A research model from an academic institution
- A proprietary model from a startup
- An internal code name for a model under development
- A fine-tuned version of an existing base model
Without access to the linked benchmark data or official documentation, the technical details remain unclear. Key questions include:
- What specific benchmarks show Gamma outperforming Qwen 3.5 397B?
- What architecture does Gamma use?
- What training data and techniques were employed?
- Is this a general capability advantage or specific to certain tasks?
The Efficiency Race Intensifies
The AI industry has been increasingly focused on model efficiency for both economic and practical reasons. Training and running 400B+ parameter models requires enormous computational resources that limit accessibility. More efficient models could:
- Reduce inference costs by orders of magnitude
- Enable deployment on less powerful hardware
- Lower the environmental impact of AI systems
- Accelerate research iteration cycles
Recent months have seen multiple efficiency-focused releases, including DeepSeek's MoE models, Google's Gemma 2 27B, and Meta's Llama 3.1 70B—all demonstrating that careful architecture design and training can yield performance disproportionate to parameter count.
Verification Needed
It's important to note that this is currently an unverified claim from a single source. The AI community has seen previous instances where preliminary results didn't hold up under rigorous evaluation or where claims were based on cherry-picked benchmarks.
For the claim to be properly assessed, we would need:
- Reproducible benchmark results across standard evaluation suites
- Technical details about Gamma's architecture and training
- Independent verification from other researchers
- Comparison on the same hardware and evaluation conditions
gentic.news Analysis
This claim, if substantiated, would represent one of the most significant efficiency breakthroughs since the original Chinchilla scaling laws were established in 2022. The scaling laws suggested that for optimal performance, model size and training data should increase proportionally, with larger models generally outperforming smaller ones given sufficient training. A 31B model beating a 397B model would fundamentally challenge this paradigm.
This development aligns with a trend we've been tracking since late 2025: the diminishing returns of pure scale. In our December 2025 analysis "The End of Brute Force Scaling," we noted that while 2024 saw massive parameter count increases (GPT-4, Claude 3 Opus, Qwen 2.5 110B), 2025 has focused on architectural innovations that deliver more performance per parameter. The DeepSeek-R1 release in January 2026 demonstrated how mixture-of-experts architectures could achieve GPT-4 level performance with far fewer active parameters per inference.
The timing is particularly interesting given Alibaba's recent struggles in the AI space. Following our February 2026 coverage of "Alibaba's AI Exodus," where key Qwen team members departed for startups, the company has been under pressure to demonstrate continued innovation. If a much smaller model from another team is outperforming their flagship 397B offering, it could signal deeper issues with their technical approach.
From a practical standpoint, efficiency breakthroughs like this could dramatically lower the barrier to state-of-the-art AI. If 30B parameter models can match or exceed 400B parameter models, then running cutting-edge AI locally on consumer hardware becomes feasible, potentially disrupting the current cloud-based inference market dominated by OpenAI, Anthropic, and Google.
Frequently Asked Questions
What is the Gamma 31B model?
Based on available information, Gamma 31B appears to be a 31-billion parameter language model that reportedly outperforms much larger models. There are no official technical details or announcements about Gamma from major AI labs, suggesting it might be a research project or internal model from a smaller organization.
How could a smaller model outperform a much larger one?
Several technical approaches could enable this: superior architecture design (like more efficient attention mechanisms or better routing in mixture-of-experts models), higher quality training data, more effective training techniques (such as improved optimization algorithms or better curriculum learning), or specialized fine-tuning for specific benchmarks. The exact method Gamma uses remains unknown without official documentation.
Has this been independently verified?
No, the claim comes from a single social media post without accompanying peer-reviewed paper or reproducible benchmarks. The AI community typically requires independent evaluation on standardized benchmarks before accepting such dramatic claims. Previous instances of surprising benchmark results have sometimes been attributed to evaluation methodology differences rather than genuine capability advantages.
What would this mean for AI development if true?
If verified, this would signal a major shift toward efficiency rather than scale as the primary driver of AI progress. It could make state-of-the-art AI more accessible by reducing computational requirements, lower costs for AI providers and users, and potentially accelerate the pace of innovation by allowing faster iteration cycles with smaller models.







