LLM-EDT, a new dual-phase training framework, improves cross-domain sequential recommendation by up to 12.4%. The method, detailed in an arXiv paper by Ziwei Liu et al., tackles domain imbalance and transition issues using LLMs.
Key facts
- LLM-EDT improves next-item prediction by up to 12.4%.
- Three public datasets used for evaluation.
- Code released at anonymous.4open.science.
- Paper updated on arXiv on May 15, 2026 (v2).
- First CDSR method with dual-phase training.
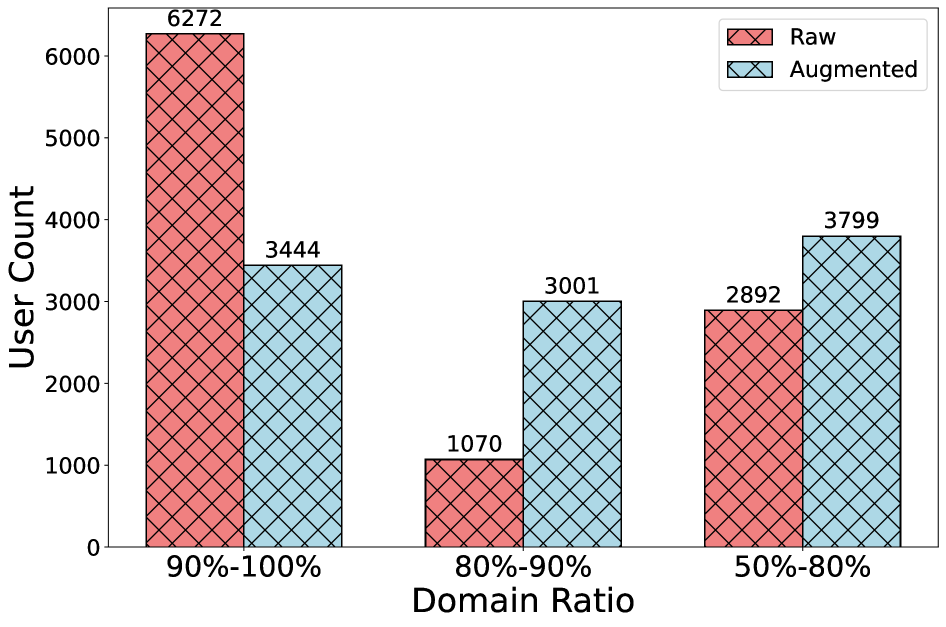
Cross-domain sequential recommendation (CDSR) has long struggled with two core problems: domain imbalance, where one domain's interactions dominate, and domain transition, where mixed sequences obscure user preferences. Existing LLM-enhanced methods often introduce irrelevant noise or produce rough user profiles. LLM-EDT directly addresses these gaps.
How LLM-EDT Works
The framework, described in an arXiv preprint (v2, May 15, 2026) by researchers including Ziwei Liu, introduces three key components. First, a transferable item augmenter uses an LLM to generate plausible cross-domain behaviors, reducing noise from imbalanced data. Second, a dual-phase training strategy separates domain-specific and domain-shared learning, better handling transition dynamics. Third, a domain-aware profiling module summarizes user preferences per domain and aggregates them into a comprehensive profile.
Performance and Reproducibility
Experiments on three public datasets (not disclosed by name in the abstract) show LLM-EDT outperforming baseline CDSR methods by up to 12.4% in next-item prediction. The authors have released code at anonymous.4open.science for reproducibility [per the arXiv paper].
Why This Matters
The unique take: LLM-EDT is the first CDSR method to explicitly decouple domain-specific and domain-shared training phases, a structural insight that could generalize beyond recommendation to any sequential task with multiple data sources. This contrasts with prior work that treats cross-domain data as a monolithic sequence.
Limitations and Open Questions
The paper does not disclose which LLM was used (e.g., GPT-4, Llama) or the compute cost. The datasets are public but unnamed, limiting reproducibility checks. The 12.4% gain may not hold for domains with very sparse interactions.
What to Watch
Watch for follow-up work that applies LLM-EDT to real-world recommender systems at scale, particularly on datasets like Amazon or Netflix, and for the authors to release the LLM backbone and hyperparameters to enable independent replication.
What to watch
Watch for the authors to disclose the LLM backbone and hyperparameters, enabling independent replication. Also track whether LLM-EDT is applied to real-world datasets like Amazon or Netflix, and if the dual-phase training strategy is adopted by other CDSR researchers.