What Happened
A new research paper titled "MDKeyChunker: Single-Call LLM Enrichment with Rolling Keys and Key-Based Restructuring for High-Accuracy RAG" was posted to arXiv on March 8, 2026. The paper addresses fundamental limitations in current Retrieval-Augmented Generation (RAG) pipelines and proposes a novel three-stage approach specifically designed for Markdown-formatted documents.
The core problem identified is that standard RAG implementations typically rely on fixed-size chunking (e.g., 500-character windows), which treats documents as plain text streams. This approach ignores inherent document structure—headers, code blocks, tables, lists—and often fragments coherent semantic units across chunk boundaries. Furthermore, extracting useful metadata from these chunks (like titles, summaries, or entities) traditionally requires multiple, sequential LLM calls per chunk, driving up cost and latency.
Technical Details
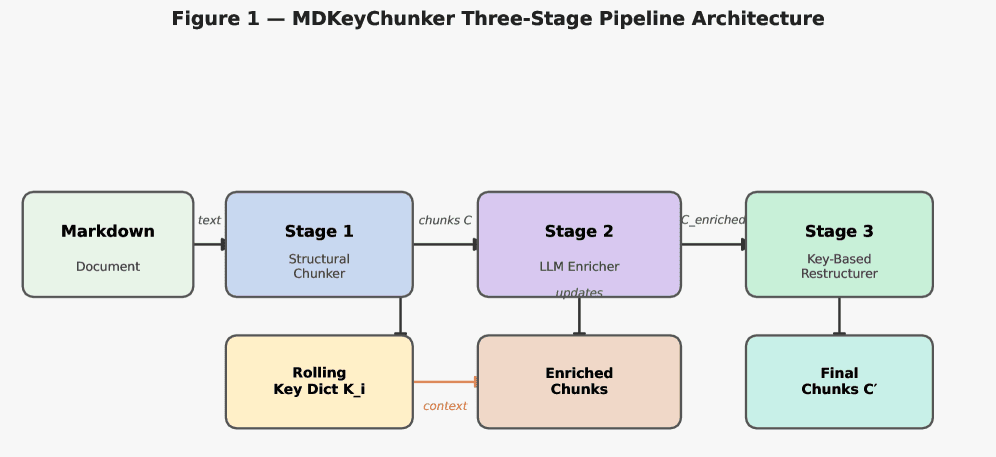
MDKeyChunker introduces a pipeline with three distinct stages:
Structure-Aware Chunking: Instead of arbitrary character splits, the system first parses the Markdown document to identify atomic structural units. Headers, code blocks, tables, and lists are treated as indivisible elements. Chunks are then created by grouping these units, respecting their hierarchical relationships. This preserves the logical flow and context intended by the document's author.
Single-Call LLM Enrichment with Rolling Keys: This is the paper's key innovation. Each structurally-defined chunk is sent to an LLM in a single prompt designed to extract seven metadata fields simultaneously:
- A title for the chunk.
- A concise summary.
- A set of keywords.
- Typed entities (e.g., people, organizations, products).
- Hypothetical questions the chunk could answer.
- A semantic key—a short, descriptive phrase capturing the chunk's core topic.
- A rolling key dictionary. This mechanism passes forward a compact set of the most relevant semantic keys from previous chunks in the same document. This provides the LLM with document-level context without needing to re-process the entire text, enabling more consistent and coherent metadata generation across related sections.
By extracting all fields in one call, the method eliminates the need for separate extraction passes, significantly reducing API calls and associated costs.
Key-Based Restructuring: After enrichment, the pipeline analyzes the generated semantic keys. Chunks that share the same or highly similar semantic key are merged using a bin-packing algorithm (respecting a maximum token limit). This final step "re-groups" related content that may have been separated during the initial structural parsing, creating final retrieval units that are thematically cohesive.
The paper presents an empirical evaluation on a corpus of 18 Markdown documents, using 30 test queries. Key results include:
- Config D (BM25 over structural chunks): Achieved perfect Recall@5=1.000 and a high Mean Reciprocal Rank (MRR)=0.911.
- Config C (Dense retrieval over the full MDKeyChunker pipeline): Achieved Recall@5=0.867.
The authors note the implementation is in Python with only four dependencies and is designed to work with any OpenAI-compatible API endpoint, suggesting practical deployability.
Retail & Luxury Implications
The research described in MDKeyChunker is fundamentally a backend infrastructure improvement for knowledge management and question-answering systems. For retail and luxury enterprises, the potential applications are significant but hinge on the format and structure of internal documents.

Potential High-Value Use Cases:
Enhanced Internal Knowledge Bases: Luxury houses operate with vast amounts of structured internal knowledge: product material specifications (Markdown tables), brand heritage documents, retail operation manuals, and compliance guidelines. MDKeyChunker's structure-aware approach could dramatically improve the accuracy of RAG systems used by customer service, retail staff, or design teams to query this corpus. A store manager could ask, "What are the care instructions for the new calfskin bag?" and the system would retrieve the exact, unfragmented section from the materials manual.
Product Catalog Enrichment at Scale: Product descriptions, technical sheets, and sustainability reports often have semi-structured data. Using this pipeline, a brand could automatically generate enriched metadata (summaries, keywords, entities) for thousands of product entries, powering more accurate search and recommendation engines on B2B or internal platforms.
Cost-Effective Agent Systems: The "single-call enrichment" design directly targets the operational cost of running AI assistants. For a global brand deploying AI agents to answer staff queries across hundreds of stores, reducing the number of LLM calls per interaction by a factor of seven (one call instead of seven) for the document processing phase translates to substantial savings at scale.
Critical Considerations & Gaps:
- Markdown Limitation: The most immediate constraint is the pipeline's focus on Markdown documents. While technical and operational documents may be authored in Markdown, a vast majority of corporate knowledge—PDF reports, PowerPoint decks, Word documents, emails—is not. The utility of this specific tool is limited to environments where Markdown is the primary documentation format or where a reliable conversion pipeline exists.
- Research vs. Production: The evaluation uses a small, controlled corpus (18 docs). Performance at the scale of a global enterprise's document repository (millions of documents across varied quality and structure) remains unproven.
- Beyond Text: The method does not address multi-modal content (images, videos) which are paramount in retail for product imagery, campaign assets, and store design documents.








