SemiAnalysis found the median coding agent request uses 96k input tokens. The analysis, pulled from 432k real coding agent requests, shows agentic workloads are reshaping inference cost assumptions.
Key facts
- Median coding agent request: 96k input tokens.
- Sample size: 432k real coding agent requests.
- 96k tokens exceeds the text of The Great Gatsby.
- Input token volume now dominates inference cost.
- Agentic workloads triple typical prompt assumptions.
SemiAnalysis published data from 432k real coding agent requests showing the median input token count is 96k tokens. For context, that exceeds the entire text of The Great Gatsby. The finding challenges conventional inference pricing models that assume output tokens dominate cost.
What the Data Reveals
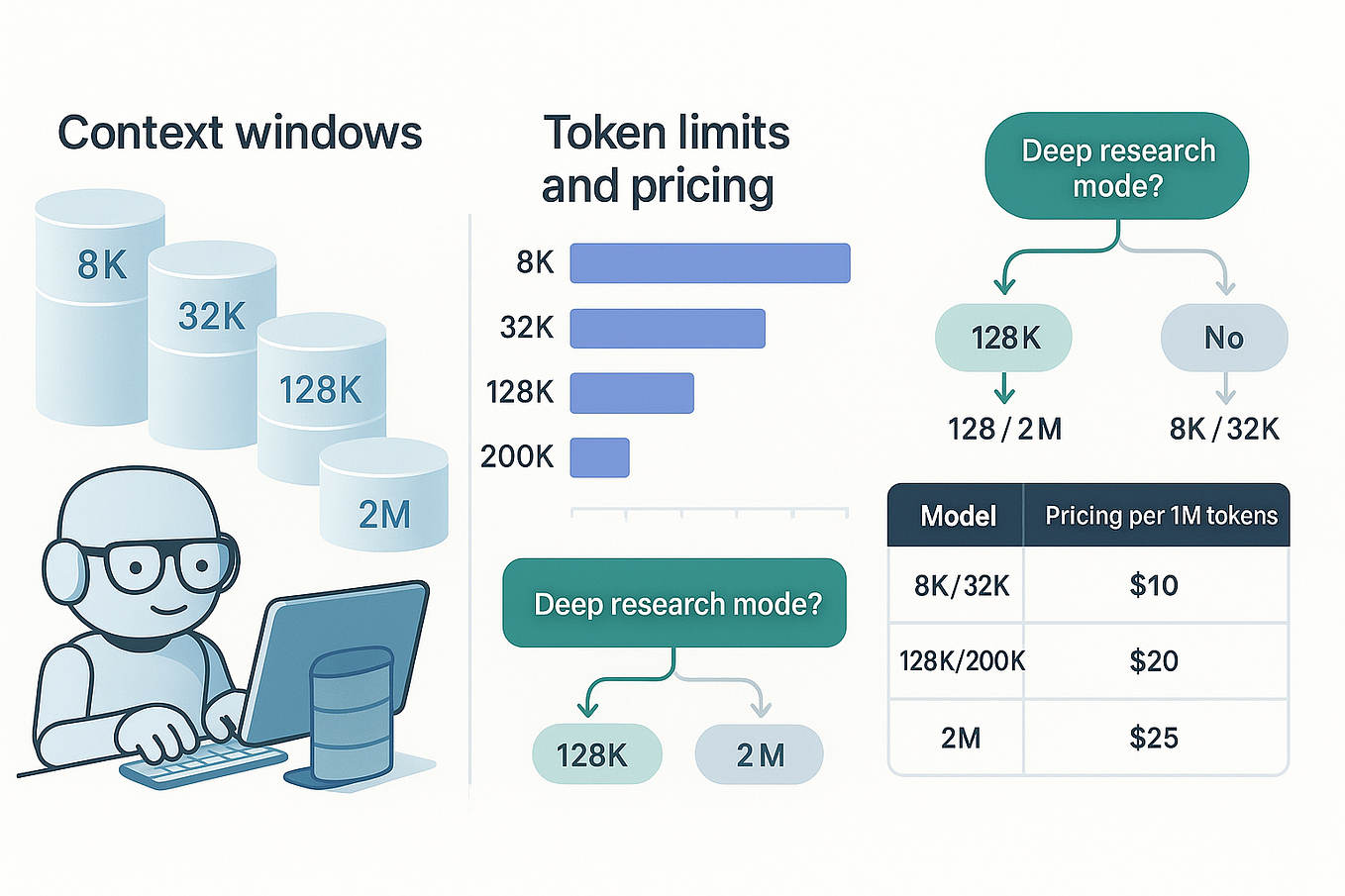
Most prompt engineering and API pricing assumes prompts of 4k-32k tokens. The median agentic request is 96k input tokens — triple the high end of that range. [According to @SemiAnalysis_], this shifts the cost center from output generation to context processing. Output tokens, while still relevant, become a secondary driver of total inference cost.
Implications for Pricing and Architecture
Current API pricing from providers like Anthropic, OpenAI, and Google often charges more per output token than per input token. With agentic workloads, the input token volume dwarfs output. A 96k input / 1k output request costs far more than a 4k input / 4k output request under standard pricing. This creates an incentive for providers to optimize context handling — via KV-cache compression, sparse attention, or sliding window techniques — rather than pure generation speed.
The finding also suggests agentic systems are not just longer prompts but fundamentally different usage patterns. The median request includes codebase context, conversation history, and tool outputs. That context accumulates over multi-step interactions, making each subsequent request more expensive than the last.
Why This Matters More Than the Press Release Suggests
The unique take: Agentic workloads invert the standard inference cost model. The industry has focused on reducing output token cost (via speculative decoding, quantization) but the real cost driver is now input token volume. Providers that optimize context processing — not generation — will win the agentic inference market.
SemiAnalysis did not disclose the exact distribution tails or the specific agent systems analyzed, but the sample size of 432k requests gives statistical weight. The company also did not specify whether the median includes failed or truncated requests, which could skew lower.
What to watch
Watch for API pricing changes from Anthropic, OpenAI, and Google in the next two quarters — specifically whether they introduce lower input token rates or context-caching features. Also track if agentic framework providers (LangChain, Vercel AI SDK) add cost-aware routing based on context size.
[Updated 23 May via reddit_claude]
The high context consumption in agentic workflows may be creating a new kind of coordination debt. A senior engineer on Reddit reported that two engineers on the same team used Claude Code to add error handling to the same service — one wrapped everything in try/catch with Sentry logging, the other built a custom Result type — both merged the same week, producing two inconsistent patterns caught only in review. The user noted that team-level speedup hasn't materialized despite individual productivity gains, because each developer's AI works from different local context and standards docs remain unread [per Reddit r/ClaudeAI].