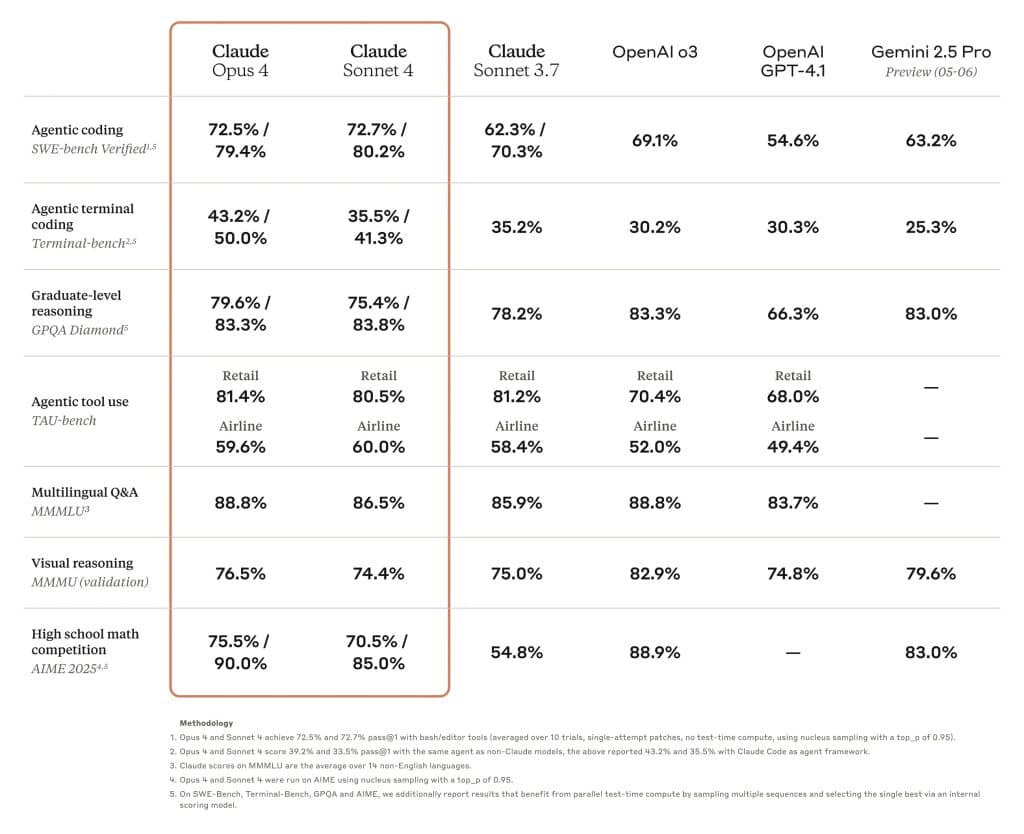
Researchers from MIT and Anthropic have developed a new benchmark that systematically identifies significant limitations in current AI coding assistants. The benchmark reveals specific categories of coding tasks where large language models consistently fail, providing concrete data on their weaknesses.
- New benchmark developed by MIT and Anthropic researchers
- Systematically identifies categories where AI coding assistants fail
- Provides concrete data on current model limitations
- Focuses on practical coding tasks beyond standard test suites
Source: MIT, Anthropic, and New Benchmarks Just Revealed AI’s Biggest Coding Limits by devsplate