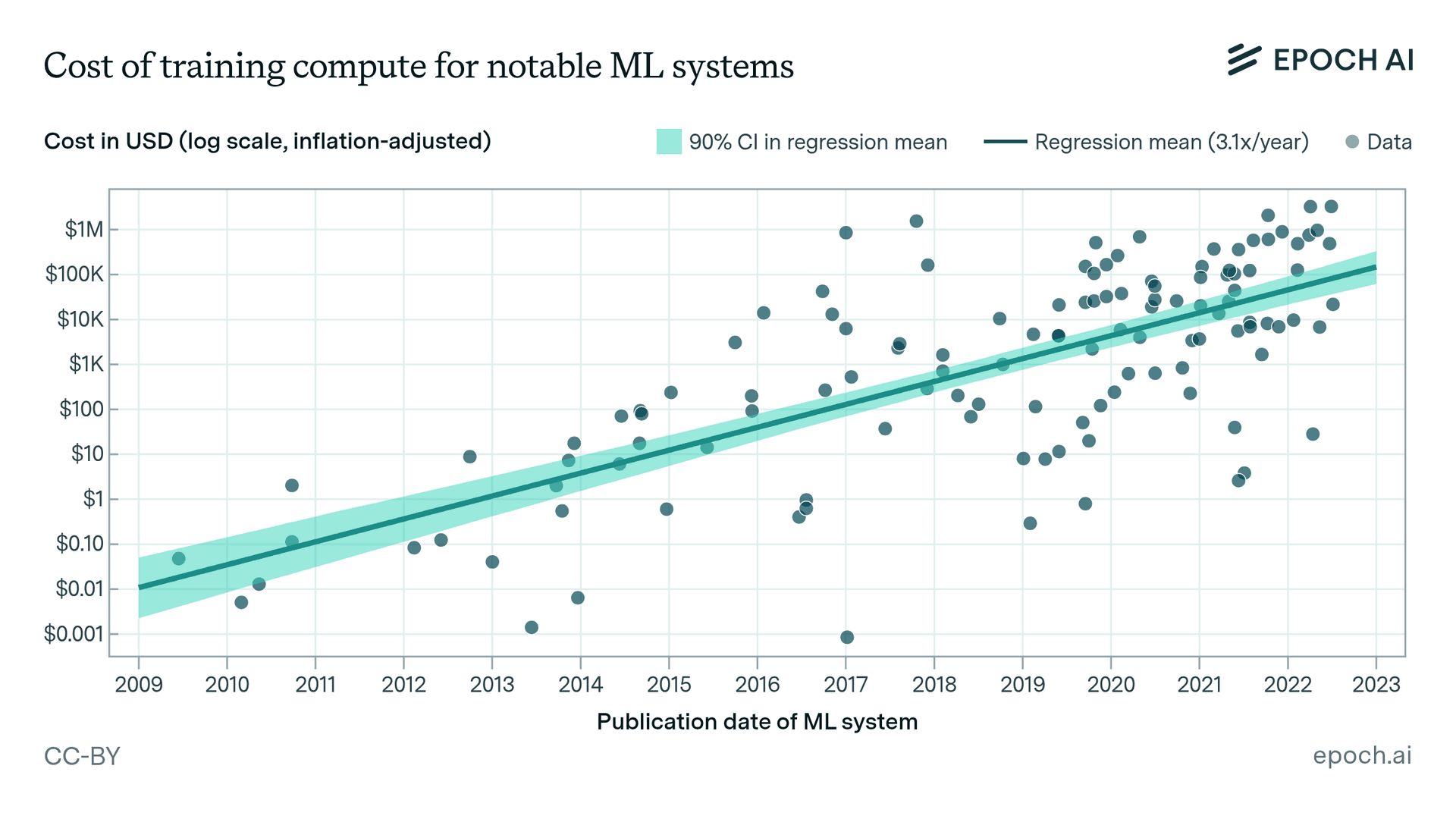
A provocative new analysis has exposed what might be one of the most critical weaknesses in modern artificial intelligence development: while companies spend billions of dollars training state-of-the-art AI models, they typically allocate only thousands of dollars to evaluate those same models through benchmark testing. This staggering disparity between training investment and evaluation rigor raises fundamental questions about how we measure AI progress and whether current benchmarks truly reflect real-world capabilities.
The Billion-Dollar Training Reality
Modern large language models and multimodal AI systems represent some of the most expensive technological developments in history. Training models like GPT-4, Claude 3, and Gemini Ultra involves massive computational resources, specialized hardware, extensive data collection and curation, and teams of highly skilled researchers and engineers. Industry estimates suggest these efforts can cost anywhere from $100 million to over $1 billion per model, with costs continuing to escalate as models grow more complex.
These astronomical investments reflect the competitive nature of the AI industry, where companies race to develop models with superior capabilities across reasoning, coding, creative tasks, and specialized domains. The training process itself has become increasingly sophisticated, involving multiple stages of pre-training, fine-tuning, alignment, and safety measures—each adding to the overall cost structure.
The Thousand-Dollar Testing Problem
In stark contrast to these training budgets, the evaluation of these models through standardized benchmarks often operates on shoestring budgets. According to the analysis referenced in the original source, comprehensive benchmark testing for even the most advanced models might cost only a few thousand dollars. This creates what researchers are calling "the evaluation gap"—a fundamental mismatch between the resources allocated to creating AI systems and those allocated to understanding what those systems can actually do.
This disparity manifests in several concerning ways:
- Limited test coverage: With constrained evaluation budgets, benchmark tests often sample only a fraction of a model's potential capabilities
- Simplistic metrics: Evaluation tends to focus on easily quantifiable scores rather than nuanced understanding of model behavior
- Lack of adversarial testing: Insufficient resources for systematic probing of model weaknesses and failure modes
- Benchmark gaming: Models can be optimized specifically for test performance without genuine capability improvement
An Experiment in Closing the Gap
The referenced initiative represents a deliberate effort to address this evaluation crisis. While specific methodological details are available through the provided links, the core approach involves creating more comprehensive, rigorous, and resource-intensive evaluation frameworks that better match the scale of investment in model development.
This experiment, developed in partnership with Martian, aims to establish new standards for AI evaluation that include:
- More extensive test sets: Moving beyond small, curated benchmarks to larger, more diverse evaluation datasets
- Multi-dimensional assessment: Evaluating not just accuracy but also robustness, consistency, and reasoning processes
- Real-world task simulation: Creating evaluation scenarios that better reflect how models will be used in practice
- Transparent methodology: Documenting evaluation processes thoroughly to enable replication and improvement
Why This Matters for AI Development
The evaluation gap has significant implications for the entire AI ecosystem. When billion-dollar models are validated through thousand-dollar tests, several critical problems emerge:
Safety concerns: Inadequately tested models may have undiscovered vulnerabilities or failure modes that could cause harm when deployed in real applications.
Misleading progress metrics: Benchmarks that don't adequately stress-test models can create false impressions of capability, leading to overconfidence in AI systems.
Inefficient resource allocation: Companies might invest in model improvements that optimize for benchmark performance rather than genuine utility.
Reduced innovation: When evaluation is inadequate, it becomes harder to identify which research directions actually lead to meaningful advances.
The Path Forward for AI Evaluation
Closing the evaluation gap will require concerted effort across the AI community. Several approaches show promise:
Increased investment in evaluation: Companies and research institutions need to allocate resources to evaluation that are proportional to their training investments.
Collaborative benchmarking: Shared evaluation efforts can pool resources and expertise to create more comprehensive tests.
Dynamic evaluation frameworks: Benchmarks that evolve alongside models, incorporating new challenges and domains as AI capabilities expand.
Standardized reporting: Transparent documentation of evaluation methodologies, costs, and limitations.
Independent verification: Third-party evaluation to complement internal testing and reduce potential conflicts of interest.
The Broader Implications
This evaluation gap discussion touches on fundamental questions about how we measure technological progress. As AI systems become more integrated into critical infrastructure, healthcare, education, and other sensitive domains, the reliability of our evaluation methods becomes increasingly important. The current situation—where we spend orders of magnitude more on creating systems than on understanding them—represents a significant risk that the AI community must address.
The experiment highlighted in the original source represents an important step toward more rigorous AI evaluation. By acknowledging and addressing the resource disparity between training and testing, researchers can develop evaluation methodologies that better reflect the complexity and importance of modern AI systems.
Source: Analysis referenced in @hasantoxr's Twitter thread and associated methodology documentation.







