What Happened
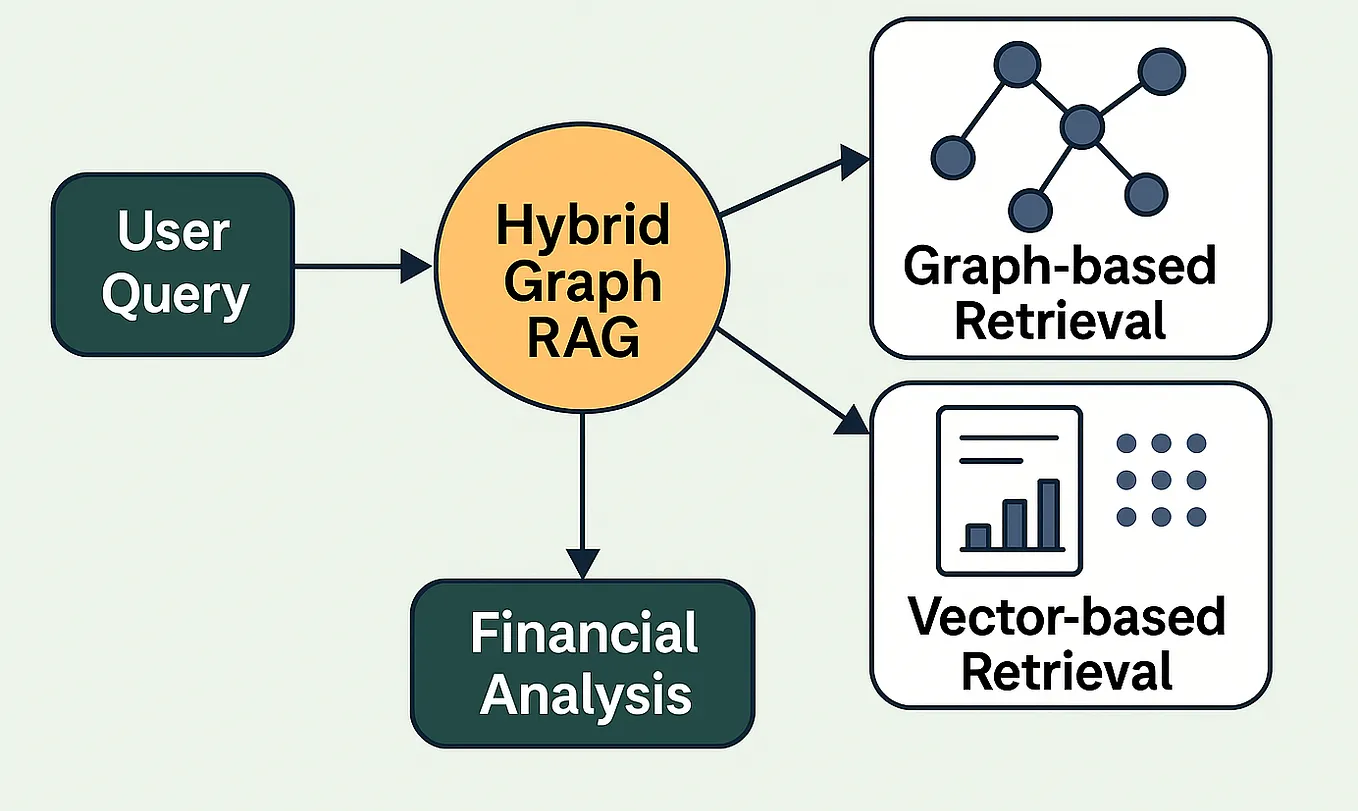
Akshay Pachaar, developer advocate at FalkorDB, published results from the GraphRAG-Bench benchmark, demonstrating that traditional vector database-based retrieval-augmented generation (RAG) fails on queries requiring multi-hop reasoning and contextual summarization. The benchmark compares vector similarity search (top-k chunk retrieval) against FalkorDB's graph-based RAG approach.
Key Numbers
- Complex Reasoning: Graph RAG scores 83.61% higher than vector DBs
- Contextual Summarization: Graph RAG scores 85.08% higher
- These are the two query types where retrieval must traverse relationships between entities, not just score chunks independently
How Vector DBs Work (and Fail)
Vector databases convert text chunks into embeddings and retrieve the top-k most similar chunks to a query using cosine similarity or another distance metric. This works well for single-hop fact lookups — "What is the capital of France?" — where the answer exists in one chunk. But for questions like "Which company founded by Sam Altman has a valuation over $100 billion?", the answer requires stitching information across multiple chunks: one chunk mentions Sam Altman founded OpenAI, another mentions OpenAI's valuation. Vector search scores each chunk independently against the query, missing the relational link.
What Graph RAG Does Differently

Graph-based RAG stores entities (people, companies, concepts) as nodes and relationships as edges. When a query comes in, the retrieval traverses the graph to find paths connecting relevant entities, rather than scoring flat chunks. This allows the system to reason across multiple pieces of information that are semantically related but not co-located in the same text chunk.
FalkorDB's GraphRAG SDK is open-source, allowing developers to build graph-based retrieval pipelines on top of their existing LLM infrastructure.
gentic.news Analysis
This benchmark quantifies a known weakness in production RAG systems. Practitioners have long observed that vanilla vector search struggles with complex queries, leading to workarounds like query decomposition (breaking a question into sub-questions) or multi-step retrieval. The GraphRAG-Bench results put a number on that gap: over 80% on the hardest query types.
FalkorDB is positioning itself as a complement to, not a replacement for, vector databases. The GraphRAG SDK can sit on top of existing vector stores, adding a graph layer for reasoning. This is a pragmatic approach — few teams will rip out their Pinecone or Weaviate instance, but many will add a graph index for complex queries.
However, graph-based retrieval introduces its own challenges: schema design (what counts as a node vs. an edge), entity resolution (are "OpenAI" and "OpenAI Inc." the same node?), and scaling graph traversal to large knowledge bases. The benchmark doesn't address these operational costs. Teams should evaluate whether their query workload includes enough multi-hop questions to justify the added complexity.
Frequently Asked Questions
What is GraphRAG-Bench?
GraphRAG-Bench is a benchmark created by FalkorDB to compare graph-based retrieval-augmented generation against traditional vector database retrieval across different query types, including single-hop lookups, complex reasoning, and contextual summarization.
Why do vector databases fail on complex reasoning?
Vector databases retrieve chunks based on semantic similarity to the query, scoring each chunk independently. Complex reasoning requires connecting information across multiple chunks that may not individually be similar to the query but together contain the answer. Vector search misses these relational connections.
Is FalkorDB's GraphRAG SDK free?
Yes, the GraphRAG SDK is 100% open-source and available on GitHub. It can be integrated with existing vector databases or used standalone with FalkorDB's graph database.
Should I replace my vector database with a graph database?
Not necessarily. Vector databases remain effective for simple fact lookups and semantic search. Graph-based retrieval adds value for complex, multi-hop queries. Many production systems will benefit from a hybrid approach, using vector search for initial retrieval and graph traversal for reasoning.