What Happened
A comprehensive technical guide, "The Ultimate Guide to LoRA: How to Fine-Tune LLMs Correctly, Part 2," has been published, offering a deep dive into the mechanics of Low-Rank Adaptation. This is not a superficial overview but a detailed examination intended for practitioners who need to understand the underlying principles to implement LoRA effectively. The guide promises to cover the mathematics, memory architecture, structural consequences, and deployment decisions behind this pivotal fine-tuning technique.
While the full article is behind a paywall, the provided snippet and title clearly indicate its scope. LoRA has become a cornerstone technique for efficiently adapting large language models by training small, low-rank matrices that are injected into the model's existing weight matrices, drastically reducing the number of trainable parameters and GPU memory requirements compared to full fine-tuning.
Technical Details
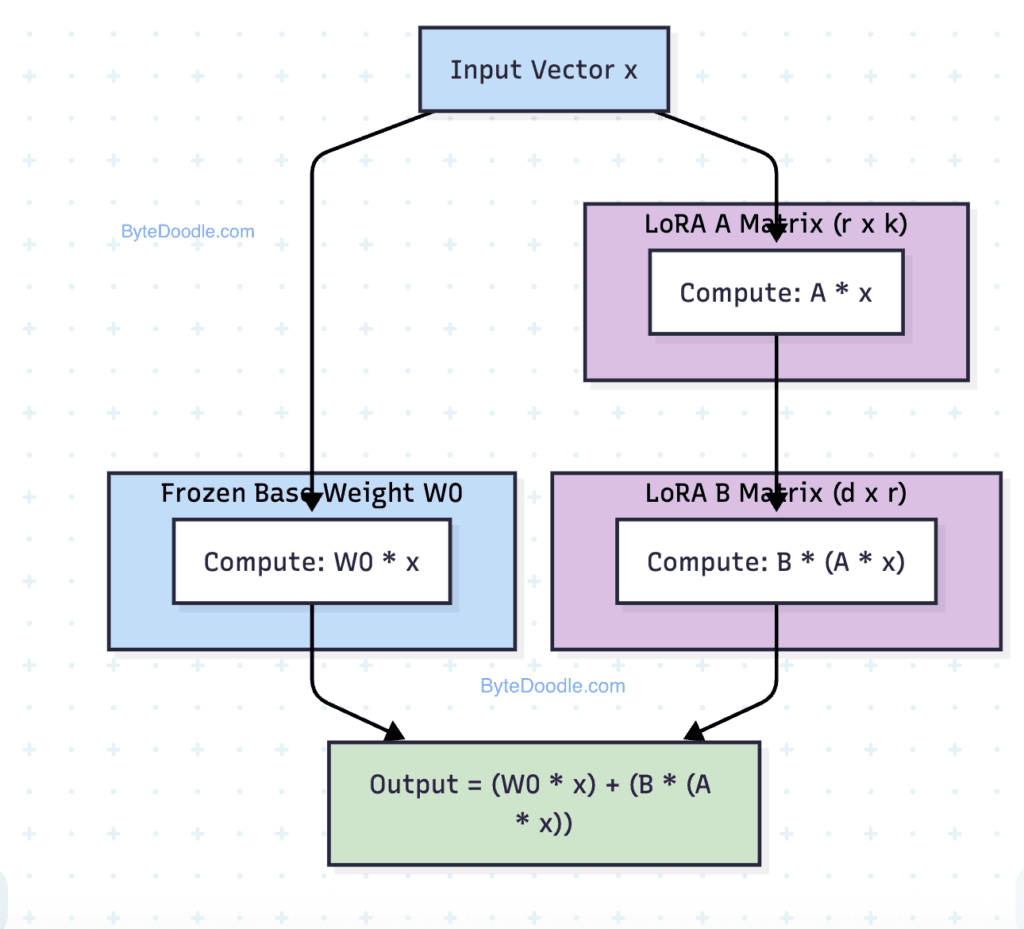
Low-Rank Adaptation (LoRA) is a parameter-efficient fine-tuning (PEFT) method. Its core innovation is the hypothesis that the weight update matrix (ΔW) for a pre-trained model during adaptation has a low "intrinsic rank." Instead of updating all 7 billion or 70 billion parameters of a model, LoRA freezes the pre-trained weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture.
For a pre-trained weight matrix (W_0 \in \mathbb{R}^{d \times k}), the update is represented as:
[ W = W_0 + \Delta W = W_0 + BA ]
where (B \in \mathbb{R}^{d \times r}), (A \in \mathbb{R}^{r \times k}), and the rank (r \ll \min(d, k)). Only the matrices A and B are trained, reducing the number of trainable parameters by orders of magnitude. For example, if (d=4096), (k=4096), and (r=8), the trainable parameters drop from ~16.7 million to ~65,536 for that single weight matrix.
The guide likely delves into:
- The Mathematics: The linear algebra behind low-rank approximations and why this assumption holds for model adaptation.
- Memory Architecture: How LoRA reduces GPU VRAM consumption not just by having fewer parameters, but by leveraging efficient optimization states (e.g., Adam optimizer states are stored only for A and B).
- Structural Consequences: How injecting these adapters affects model performance, potential interference between multiple LoRA modules, and the trade-offs in choosing the rank (r) and which layers to target (attention layers, feed-forward networks, or both).
- Deployment Decisions: Practical considerations for serving models fine-tuned with LoRA, such as merging the adapter weights back into the base model for inference latency or keeping them separate for flexibility.
Retail & Luxury Implications
For AI leaders in retail and luxury, mastering LoRA is not an academic exercise—it's an operational necessity for creating competitive, differentiated AI applications. The ability to efficiently customize large foundational models is the key to moving beyond generic chatbots and creating specialized brand assets.
1. Specialized Brand Voice and Knowledge:
A luxury house cannot use a generic model to communicate its heritage, craftsmanship, and aesthetic principles. LoRA enables the creation of a "Brand Voice Adapter"—a lightweight module trained on decades of press releases, product descriptions, and client communications. This adapter can be applied to any customer-facing model (chat, email generation, content creation) to ensure all output is consistently on-brand, from the tone used to describe a savoir-faire to the precise terminology for materials.
2. Hyper-Personalized Clienteling at Scale:
Personalization is the zenith of luxury service. A LoRA module can be trained on an individual client's purchase history, communication preferences, and style profile. Instead of maintaining thousands of fully fine-tuned massive models—a storage and compute nightmare—a retailer can maintain a single base model and dynamically load a client-specific LoRA adapter during interactions. This enables a sales associate's AI tool to generate recommendations or communication that feels uniquely tailored to that client.
3. Efficient Domain-Specific Product Intelligence:
Training a model from scratch to understand the nuances of haute horlogerie, haute couture, or fine jewelry is prohibitively expensive. A LoRA adapter can be trained on technical manuals, auction catalogs (e.g., Phillips, Christie's), and artisan interviews. This injects deep domain expertise into a general-purpose model, enabling it to power sophisticated applications like a virtual product expert that can explain the complication of a minute repeater or the provenance of a gemstone.
4. Rapid Prototyping and A/B Testing:
The low cost of training a LoRA adapter (often requiring a single GPU for a few hours) allows teams to experiment rapidly. Marketing can test different conversational tones for a campaign; e-commerce can trial different recommendation strategies. Each experiment is a separate, small adapter, making it easy to iterate, compare, and deploy the winning variant without retraining an entire model.
The guide's focus on deployment decisions is particularly critical. For a global brand serving customers in real-time, inference latency is paramount. The decision to merge a LoRA adapter into the base model (creating a single, slightly larger file) versus keeping it separate (requiring runtime composition) has direct implications on API response times and infrastructure complexity—a key consideration for any customer-facing application.








