
Key Takeaways
- The article presents a detailed, production-ready framework for building an enterprise RAG system, covering architecture, security, and deployment.
- It provides a concrete path for companies to move beyond experimental prototypes.
What Happened
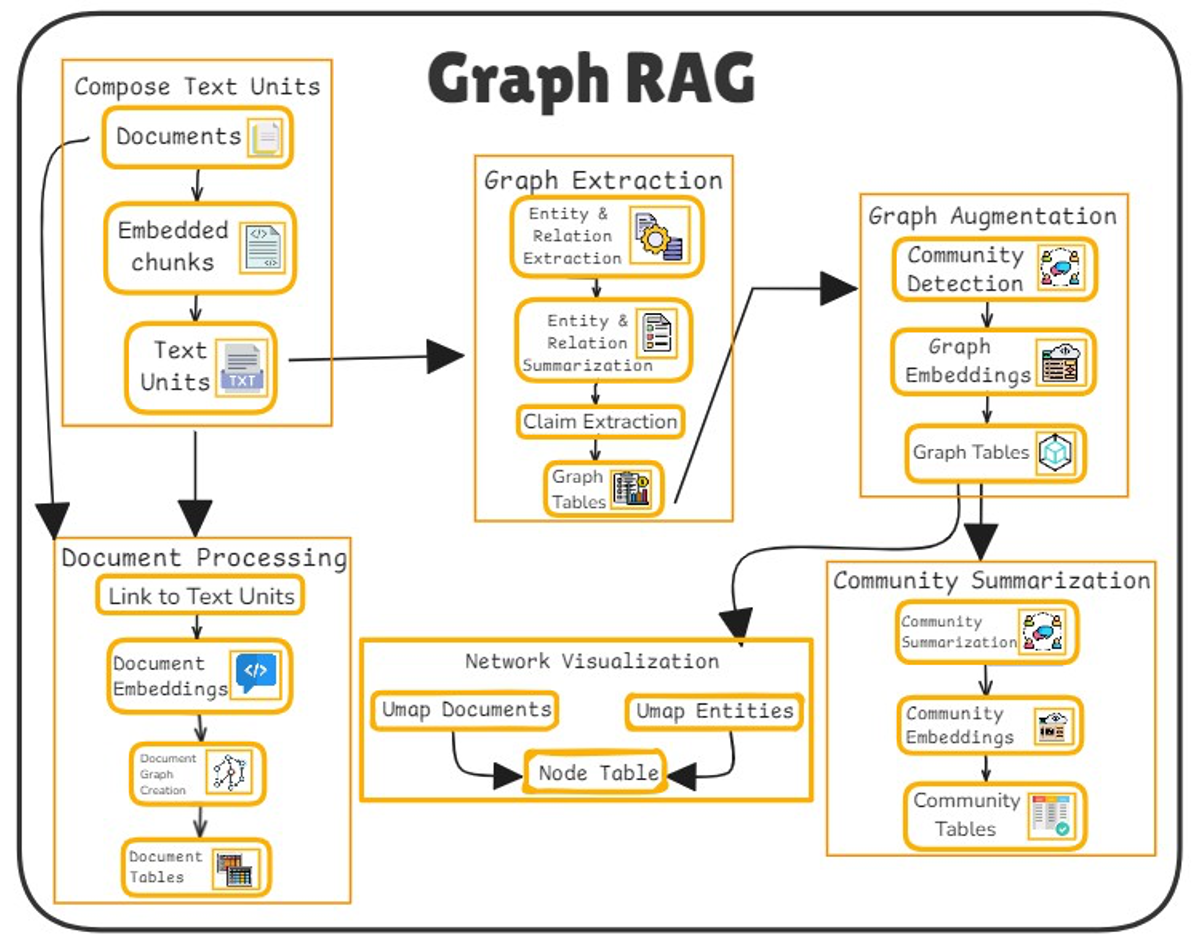
A developer has published a comprehensive guide and companion open-source repository detailing a systematic approach to building and deploying a Retrieval-Augmented Generation (RAG) system for an enterprise internal knowledge base. The project, titled "Enterprise Internal Knowledge Base RAG MCP," is explicitly framed as a blueprint to move from a Proof-of-Concept (POC) to a production-grade application. The public GitHub repository (kimsb2429/internal-knowledge-base) serves as the practical implementation of the concepts discussed in the accompanying Medium article.
While the full article is behind a Medium paywall, the public summary and repository description indicate a focus on the full lifecycle of a RAG project. The inclusion of "MCP" (Model Context Protocol) in the title suggests the system may leverage this emerging standard for tool integration with LLMs, aiming for a modular and interoperable architecture.
Technical Details
The core challenge addressed is that many RAG prototypes fail in production due to issues with scalability, security, data freshness, and response quality. A production RAG system is more than just a vector database and a language model; it requires a robust pipeline.
Based on the repository structure and common patterns for production RAG, the framework likely covers:
- Ingestion & Chunking Pipeline: Automated processes to ingest documents from various sources (PDFs, Confluence, SharePoint), parse them, and create intelligent, semantically coherent chunks for embedding.
- Embedding & Indexing: Generating vector embeddings for text chunks and storing them in a dedicated vector database (e.g., Pinecone, Weaviate, pgvector) for efficient similarity search.
- Retrieval & Orchestration: The "retrieval" layer that processes a user query, finds the most relevant context from the knowledge base, and formats it for the LLM. This includes advanced techniques like hybrid search (combining keyword and vector search) and re-ranking to improve precision.
- Generation & Response: Using an LLM (e.g., via OpenAI, Anthropic, or a local model) to synthesize the retrieved context into a coherent, accurate, and cited answer.
- Production Infrastructure: Deployment considerations using containerization (Docker), orchestration (Kubernetes), API gateways, monitoring, logging, and continuous integration/continuous deployment (CI/CD) pipelines.
- Security & Access Control: Critical for enterprise use, this involves integrating with existing identity providers (e.g., Okta, Azure AD) to ensure users only retrieve information they are authorized to access.
The use of the Model Context Protocol (MCP) is a notable technical choice. MCP is a protocol developed by Anthropic to standardize how applications provide context to LLMs. By adopting MCP, this framework aims to make the knowledge base a standardized "context source" that can be easily integrated into various AI assistants and agent workflows, enhancing modularity and reducing vendor lock-in.
Retail & Luxury Implications
For retail and luxury enterprises sitting on decades of unstructured data—product manuals, supplier contracts, compliance documents, internal brand guidelines, and customer service histories—the leap from a RAG demo to a trustworthy system is the central challenge. This framework provides a tangible roadmap.
Concrete Application Scenarios:
- Corporate Knowledge Hub: New hires in buying, merchandising, or store operations could query a single source for historical buying reports, brand partnership terms, or visual merchandising standards.
- Supply Chain & Compliance: Teams could instantly retrieve specific clauses from supplier agreements or navigate complex sustainability and import/export regulations by querying document repositories.
- Customer Service Elevation: Contact center agents could be equipped with an assistant that pulls accurate information from technical product catalogs, repair manuals, and past service bulletins to resolve customer issues faster and more accurately.
- Creative & Marketing Asset Management: A RAG system could help teams find past campaign briefs, visual assets, and performance reports based on semantic search, not just filenames.
The critical value of a production-focused framework like this is in addressing the non-negotiable requirements for luxury businesses: security, accuracy, and auditability. A POC that "mostly works" is unacceptable. A production system must have strict access controls, provide citations for every claim, and maintain the consistency and tone of the brand in its responses.
Implementation Approach

Adopting this framework requires a cross-functional team with expertise in machine learning engineering, backend development, DevOps, and security. The steps would involve:
- Assessment: Inventorying data sources, defining use cases, and establishing accuracy/performance benchmarks.
- Customization: Using the open-source repository as a foundation, but heavily customizing the ingestion connectors for internal systems (e.g., SAP, legacy PLM) and integrating with the company's specific identity and access management (IAM) system.
- Phased Deployment: Starting with a low-risk, high-value knowledge domain (e.g., internal IT documentation) to validate the pipeline, measure performance, and build trust before expanding to core business data.
- Governance: Establishing clear ownership for content accuracy, a feedback loop for hallucination correction, and a model evaluation regimen.
The complexity is high, but the framework reduces the initial architectural uncertainty. The decision to use cloud-based vs. on-premise LLMs and vector databases will be a key strategic choice, especially for European luxury houses with stringent data sovereignty requirements.
Governance & Risk Assessment
Data Privacy & Security: The highest priority. The system must be designed with a "zero-trust" data access model. Embedding and querying must be logged for audit trails. Personally Identifiable Information (PII) in source documents may need to be redacted or masked during ingestion.
Hallucination & Accuracy: Even with RAG, models can misinterpret context or fabricate details. A robust production system requires a "grounding" layer that forces citations and includes human-in-the-loop review for sensitive queries.
Maturity Level: The underlying RAG technology pattern is rapidly maturing but is now entering the early-adopter phase for enterprise production. Using a structured framework like this mitigates risk compared to a ground-up build. The incorporation of MCP is forward-looking but adds a dependency on an emerging standard.
gentic.news Analysis
This practical guide reflects a critical maturation in the enterprise AI landscape. The conversation is shifting from "Can we build a chatbot?" to "How do we build a reliable, secure, and maintainable knowledge infrastructure?" For the retail and luxury sector, this shift is essential. The value of AI is not in flashy demos but in systems that reliably augment employee expertise and decision-making with institutional knowledge.
The author's focus on MCP is insightful. As companies like Anthropic (with Claude) and Google (integrating MCP into Gemini Code Assist) push this protocol, luxury brands building internal AI tools must consider interoperability. An MCP-compliant knowledge base could one day seamlessly serve context to a variety of AI agents—from a design assistant to a sustainability compliance checker—without rebuilding the data pipeline for each one. This aligns with the broader industry trend towards agentic workflows, where multiple specialized AI tools collaborate. A reliable, centralized knowledge source is the foundational bedrock for such agent ecosystems.
Furthermore, this dovetails with the increasing activity from cloud providers like Microsoft Azure AI and Google Cloud Vertex AI, who are rapidly launching managed RAG services. An open-source framework like this gives enterprises the blueprint to evaluate and potentially integrate with these platforms on their own terms, rather than being locked into a single vendor's black box. The ultimate goal for a luxury group is not just a working tool, but a strategic knowledge asset that is scalable, secure, and under its own governance. This framework provides a credible path to that goal.






