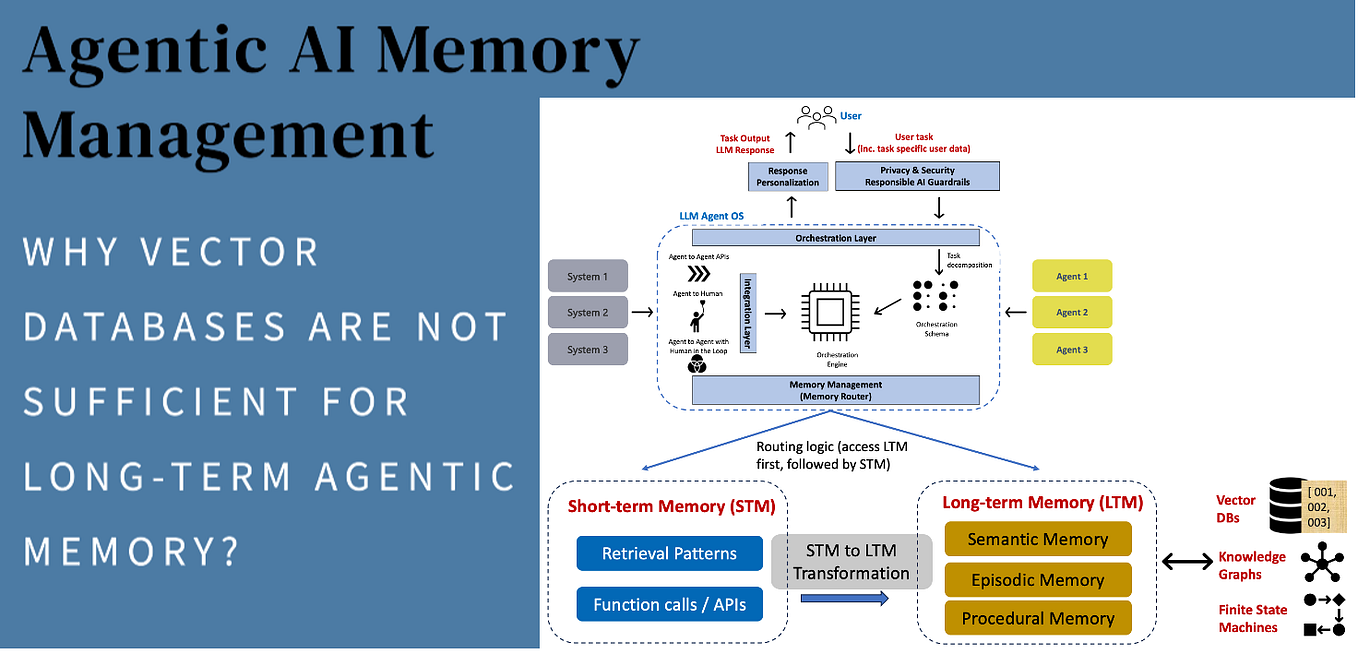
A new analysis shared by AI researcher Kimmo Kärkkäinen (known as @kimmonismus) indicates a significant milestone: the total volume of text generated by artificial intelligence systems has now exceeded the volume of text written by humans for the first time in history.
The claim is based on a chart showing a "very steep curve" of AI output growth, suggesting this crossover point represents "just the beginning" of a larger transformation in how written content is produced.
What the Data Shows
While the specific source data behind the claim isn't detailed in the tweet, the assertion points to aggregate measurements of text production across various platforms and applications. This would include content generated by:
- Large language models (GPT-4, Claude, Gemini, Llama) through public APIs
- AI writing assistants (Grammarly, Jasper, Copy.ai)
- Code generation tools (GitHub Copilot, Amazon CodeWhisperer)
- Social media and marketing automation tools
- Customer service chatbots and email responders
The "steep curve" referenced suggests exponential growth in AI text generation, likely correlating with the widespread availability of capable models and their integration into everyday workflows.
Context and Implications
This milestone follows several years of rapid advancement in natural language generation. The release of GPT-3 in 2020 marked a turning point where AI-generated text became coherent enough for practical applications. Subsequent models have improved fluency, reduced harmful outputs, and become more accessible through APIs and consumer products.
The practical implications are immediate:
- Content saturation: The internet's text corpus is now being supplemented (and potentially dominated) by machine-generated content
- Detection challenges: Distinguishing AI-written from human-written text becomes increasingly difficult
- Economic displacement: Professional writing, editing, and content creation roles face new competitive pressures
- Information quality: Questions arise about the originality, accuracy, and cultural context of AI-generated text
Technical Reality Check
It's important to note what this milestone does not mean:
- Quality equivalence: Volume doesn't equate to quality, originality, or value
- Uniform distribution: AI text generation is concentrated in specific domains (code, marketing copy, customer service)
- Human replacement: Many forms of writing (creative, academic, deeply personal) remain predominantly human domains
- Autonomous creation: Most AI text generation is still human-directed through prompts and editing
The metric measures raw token output, not necessarily published, useful, or valuable content. Much AI-generated text may be intermediate drafts, code comments, automated responses, or low-quality content that never reaches an audience.
gentic.news Analysis
This development represents a quantitative inflection point with qualitative implications that our readers should understand in context. The claim aligns with trends we've been tracking across multiple domains.
First, this follows the pattern of exponential scaling we've documented in model capabilities, training compute, and now output volume. As we reported in our analysis of OpenAI's GPT-4o release, the barrier to generating coherent text has effectively disappeared for most practical purposes. What was once a research demonstration is now a utility.
Second, this milestone has particular significance for technical practitioners. The "steep curve" mentioned likely has two primary drivers: (1) the proliferation of coding assistants like GitHub Copilot (which Microsoft reported had over 1.3 million paid subscribers as of early 2024), and (2) the integration of LLMs into developer workflows through tools like Cursor, Windsurf, and Continue. Code generation represents a massive volume of structured text where AI assistance provides immediate productivity gains.
Third, this development creates new technical challenges that our audience faces directly. The increasing volume of AI-generated text affects:
- Training data contamination: Future LLM training runs will inevitably include more AI-generated content, potentially leading to model collapse or quality degradation
- Evaluation difficulty: Benchmarking models becomes harder when test sets may contain AI-generated examples
- Toolchain adaptation: Development tools need to evolve to handle mixed human-AI authorship and attribution
Practically, engineering teams should be implementing provenance tracking for AI-generated code and documentation, establishing clear policies about AI use in production systems, and considering how AI-generated content affects their own model training pipelines.
Frequently Asked Questions
How was this AI vs. human text volume measured?
The original source doesn't specify methodology, but such measurements typically aggregate data from: API call volumes to major LLM providers, usage statistics from popular AI writing tools, analysis of web content creation patterns, and estimates of human writing output based on internet usage statistics and professional writing metrics.
Does this mean AI writes better than humans?
No. This milestone measures volume, not quality. While AI excels at certain types of formulaic, technical, or repetitive writing, human writers still dominate in creative expression, original research, nuanced argumentation, and culturally contextual writing. The metric is about quantity, not capability.
What are the main sources of AI-generated text?
The largest contributors are likely: (1) programming/code generation tools, (2) customer service chatbots and email automation, (3) content marketing and SEO article generation, (4) social media management tools, and (5) academic/scientific writing assistants. Code generation alone represents billions of tokens daily.
How will this affect content detection and moderation?
Detection becomes increasingly difficult as models improve and volume increases. Most current detection tools have high error rates, especially for edited or hybrid human-AI content. This creates challenges for academic integrity, content moderation, and information authenticity that lack technical solutions.
Should developers be concerned about training on AI-generated code?
Yes, this is an emerging concern. Training future models on AI-generated code without careful filtering could lead to "model collapse" where quality degrades over generations. Teams should consider the provenance of their training data and implement safeguards against excessive AI-generated content in their datasets.