
Blockify, a new RAG method from developer akshay_pachaar, reduces corpus size by 40x. It also cuts tokens per query by 3x and improves vector search relevance by 2.3x over naive RAG.
Key facts
- Blockify reduces RAG corpus size by 40x.
- Tokens per query drop by 3x.
- Vector search relevance improves 2.3x.
- Open-source implementation on GitHub.
- Specific benchmark details not disclosed.
Blockify, a retrieval-augmented generation technique shared by developer akshay_pachaar, claims dramatic efficiency gains over standard chunk-based RAG. The approach reduces the corpus size by 40x, meaning far fewer documents need to be indexed and searched. Tokens per query drop by 3x, lowering both latency and cost for downstream LLM calls. Vector search relevance improves by 2.3x, as measured by retrieval recall or precision metrics (the specific benchmark is not disclosed) [According to @akshay_pachaar].
The method's GitHub repository [Blockify GitHub] provides an open-source implementation. The core idea appears to involve block-level indexing rather than naive chunking, though full technical details (e.g., block size, embedding strategy, retrieval algorithm) are not elaborated in the source tweet. The 40x corpus reduction suggests aggressive deduplication or compression, possibly through semantic hashing or content-aware segmentation.
Key Takeaways
- Blockify claims 40x corpus reduction and 2.3x relevance gain over naive RAG.
- Open-source on GitHub, but lacks benchmark details.
The Unique Take Here
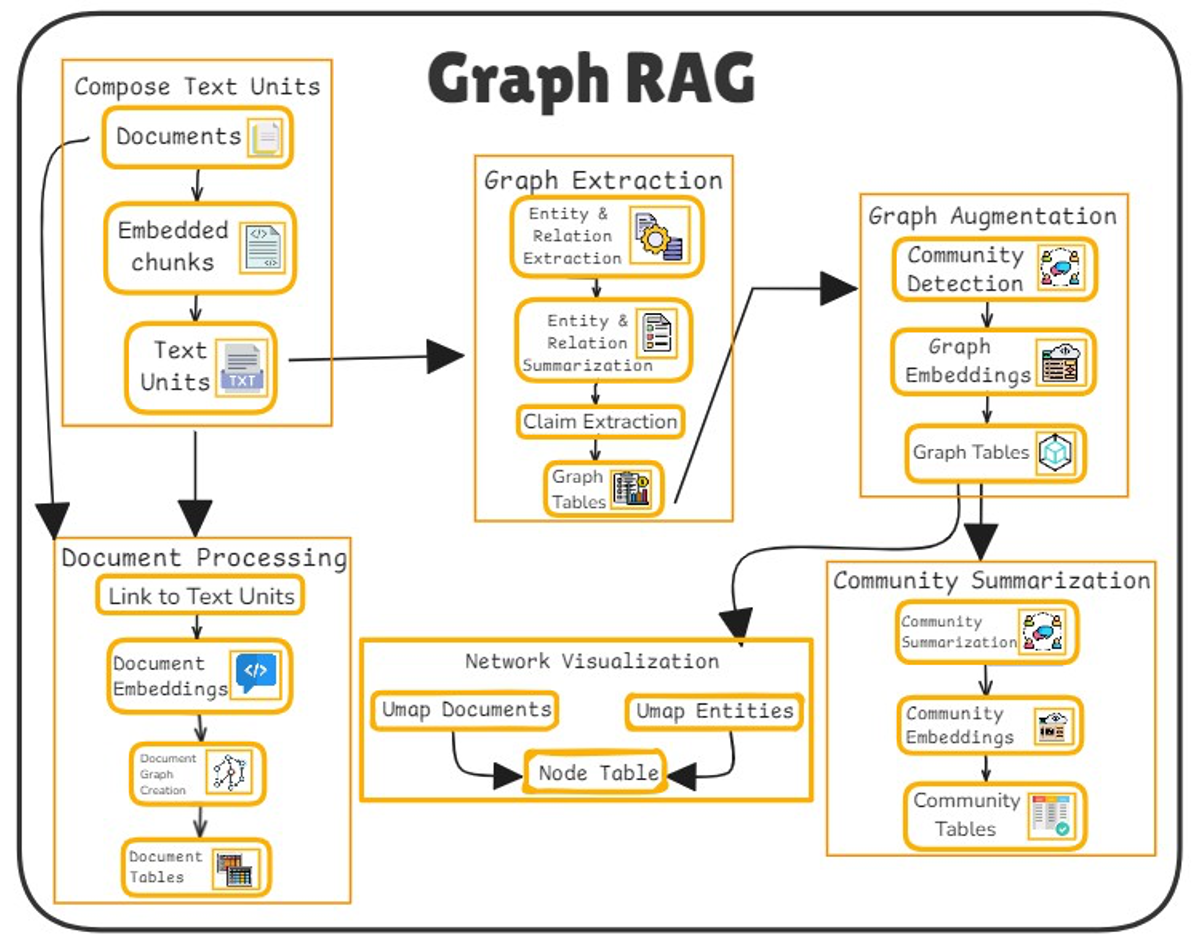
The 40x compression ratio is the standout claim. Most RAG optimization work focuses on improving retrieval recall (e.g., hybrid search, re-ranking) or reducing chunk overlap. Blockify instead attacks the index size itself, which has direct implications for storage costs, RAM usage during inference, and search latency in large-scale deployments. If the 40x number holds under replication, it would make RAG feasible for terabyte-scale corpora on consumer hardware.
Limitations and Open Questions
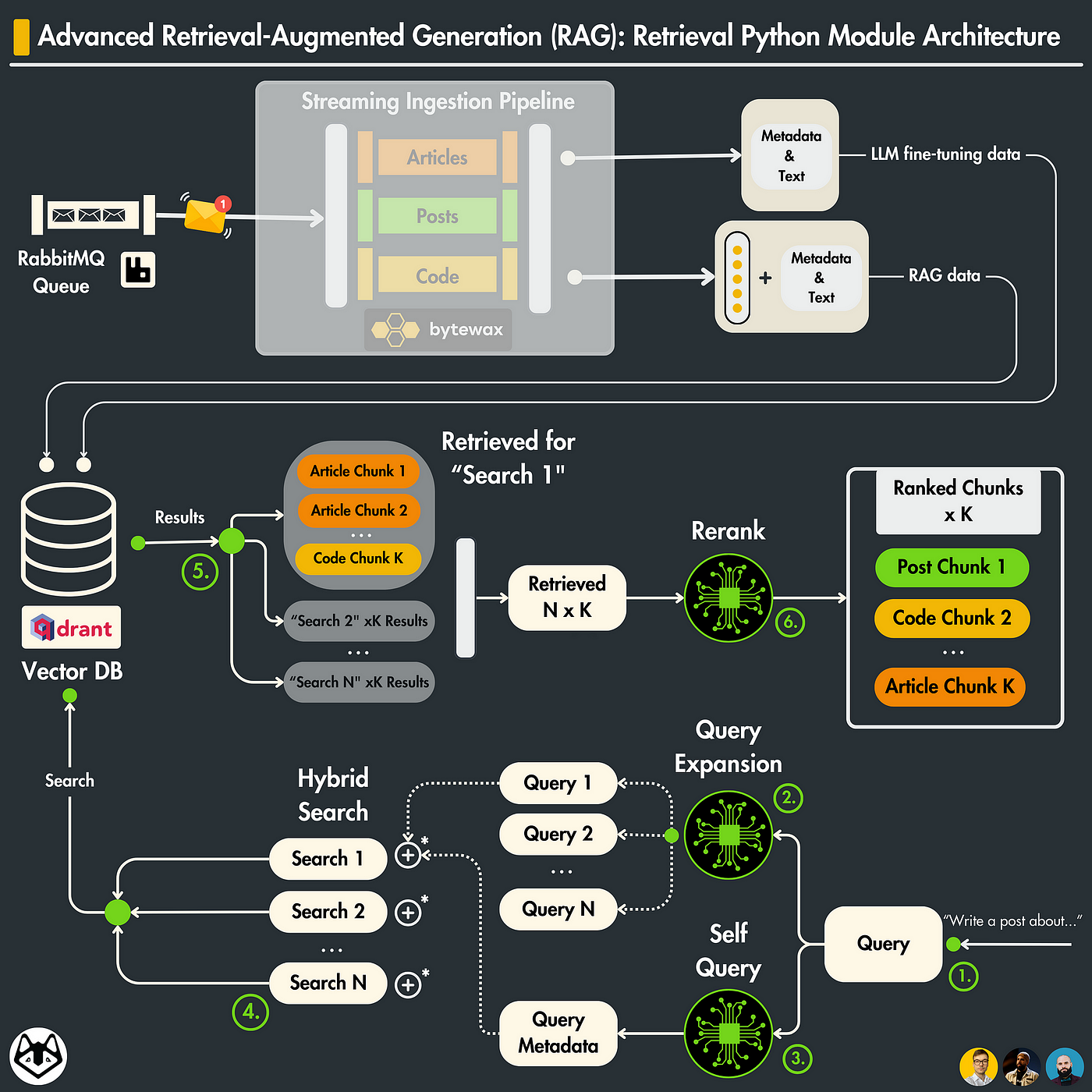
The source does not specify which benchmarks were used for the 2.3x relevance improvement — no dataset, no baseline model, no evaluation script. The tweet also omits ablation studies (e.g., impact on recall vs. precision, performance on long-tail queries). The 3x token reduction per query likely comes from shorter retrieved passages, but whether this sacrifices answer completeness is unclear. The GitHub repo may contain these details; as of this writing, it has not been independently audited.
What to watch
Watch for independent replication on standard RAG benchmarks (e.g., NQ, TriviaQA, HotpotQA) and comparison against mature methods like LlamaIndex's hierarchical chunking or Cohere's rerank. Also watch for the GitHub repository's star count and issue tracker to gauge community adoption and validation.








