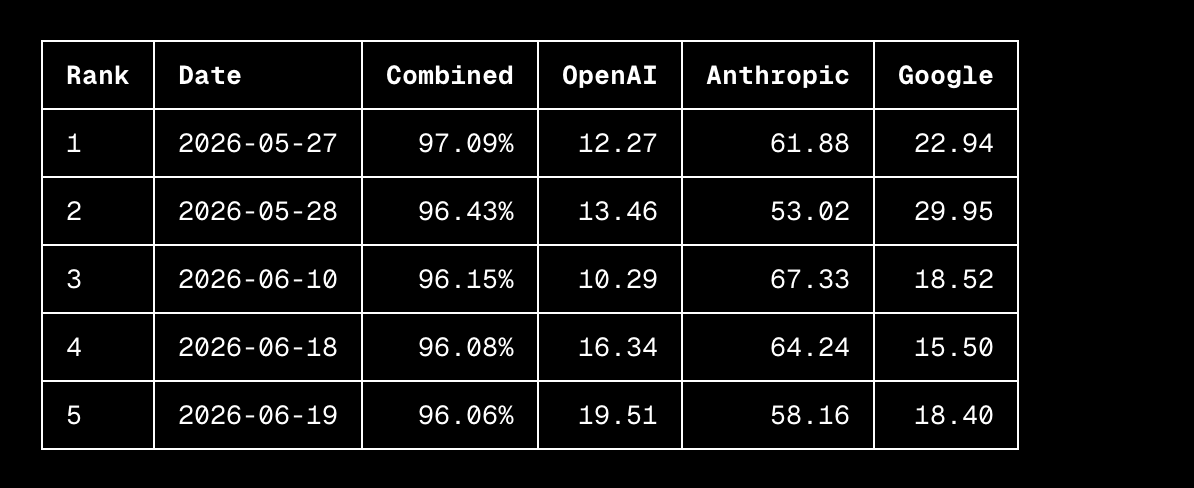
Key Takeaways
- Sanket Parmar argues that fine-tuning shapes model behaviour for your domain more than base model selection.
- The article emphasizes that investing in adaptation yields better returns than chasing the latest foundation model.
What the Source Actually Says

A new article by Sanket Parmar, AI Fine-Tuning: Why It Matters More Than the Model You Pick, makes a provocative claim: the technique you use to adapt a model to your data and tasks often outweighs the performance differences between foundation models. Parmar argues that while organizations obsess over whether to use GPT-4, Claude, Llama 3, or Gemini, the real differentiator is how well they fine-tune the chosen model for their specific context.
The core thesis is straightforward: a smaller, well-tuned model can outperform a larger, out-of-the-box one for a narrow domain. Fine-tuning — adjusting model weights on domain-specific data — embeds specialized knowledge that off-the-shelf models lack. The article positions fine-tuning as a strategic lever rather than a technical afterthought.
Why This Matters for Retail & Luxury
For retail and luxury AI leaders, this argument is immediately relevant. The industry deals with highly specific vocabularies (e.g., terms like "prêt-à-porter," "haute couture," or SKU-level product attributes), unique brand tones, and regulatory requirements around authenticity and customer data. A generic LLM might know what a "dress" is, but it won't understand a Gucci Dionysus bag's material composition or the correct brand voice for a Dior product description.
Fine-tuning enables models to internalize these nuances. Instead of relying on prompt engineering to inject brand guidelines at runtime — which is brittle and computationally expensive — a fine-tuned model can produce outputs that feel native to the brand. This has direct implications for:
- Product description generation: Fine-tuned models produce copy consistent with brand guidelines, reducing editing time.
- Customer service: A fine-tuned chatbot understands return policies, product availability, and luxury service expectations without being explicitly told each time.
- Visual search and attribute extraction: Vision-language models fine-tuned on brand catalogues can accurately identify subtle differences (e.g., a seasonal colour vs. a staple shade).
The article reinforces what we've seen across 17 prior pieces on fine-tuning: it's not about which model you pick, but how you adapt it.
Business Impact — Quantified and Unvarnished
The source does not provide metrics. However, our prior coverage allows us to contextualize. In the article "The ROI of Fine-Tuning is Under Threat from Newer" (April 14, 2026), we noted that fine-tuning projects typically require 1–4 weeks of data preparation and 2–5 days of training on moderate GPU instances. The ROI comes from reduced prompt engineering overhead and higher accuracy on domain-specific tasks.
For a luxury retailer, the cost of fine-tuning a 7B-parameter model (like Llama 3) on a product catalogue of 100K items is roughly $5K–$15K in compute. The alternative — prompt engineering with a larger model — might cost $20K–$50K annually in API calls alone, with less consistent quality. The trade-off is becoming clearer, as the article argues.
Implementation Approach

Fine-tuning for retail requires:
- High-quality domain data — Product descriptions, customer service logs, brand guidelines, and style guides. Minimum 500–2000 examples for meaningful effect.
- Clear objective definition — Is the goal tone consistency, factual accuracy, or both?
- Model selection — Start with a strong base (Llama 3, Mistral, or GPT-4 Turbo via API fine-tuning).
- Technique choice — Parameter-efficient methods (LoRA, QLoRA) reduce cost and training time, as covered in our guide "A Practical Guide to Fine-Tuning an LLM on RunPod H100 GPUs with QLoRA" (April 11, 2026).
- Evaluation — Differential testing: compare fine-tuned vs. base model on representative tasks.
Complexity is moderate: teams need ML engineering expertise, but tools (Hugging Face, Unsloth, RunPod) have lowered the barrier.
Governance & Risk Assessment
Fine-tuning carries risks:
- Overfitting — Model becomes too specialized, losing general knowledge or hallucinating on edge cases.
- Drift — Fine-tuned models can diverge from the base model's safety alignment if not careful.
- Data privacy — Customer data used in fine-tuning must be anonymized and compliant with GDPR and local laws.
Maturity level: Fine-tuning is a proven technique (production use for 2+ years in retail) but still requires careful monitoring. The article's emphasis on technique over model selection is a useful reminder: don't chase the latest model; invest in adaptation.
Gentic.news Analysis
Fine-tuning has been a recurring theme on gentic.news, appearing in three articles in the past week alone. Our recent guides have compared fine-tuning to RAG (Retrieval-Augmented Generation) and prompt engineering. Parmar's piece aligns with the consensus we've reported: fine-tuning is essential for domain mastery, especially when brand voice and specialized terminology matter.
Notably, the article does not mention the elephant in the room: the cost of fine-tuning vs. RAG. As we covered in "Fine-Tuning vs RAG: A Foundational Comparison for AI Strategy" (April 22, 2026), RAG is often cheaper and faster to deploy for knowledge-heavy tasks. However, for tasks requiring behavioral adaptation — like tone or style — fine-tuning remains superior. The source's thesis holds strongest in that niche.
For retail leaders, the takeaway is pragmatic: don't start by choosing a model. Start by defining the domain-specific behavior you need, then fine-tune the best accessible model for that behavior. The model you pick matters, but how you tune it matters more.