What Happened
A practical, no-nonsense guide has emerged on Medium comparing two dominant approaches for customizing large language models (LLMs) in production: Retrieval-Augmented Generation (RAG) and fine-tuning. Authored by Anisha Walde, the post cuts through the hype to help AI practitioners decide which method to use for real-world projects.
The core insight: RAG is ideal when you need to incorporate new, dynamic, or proprietary data without retraining the model. Fine-tuning is better when you need to change the model's behavior, style, or output format consistently.
Technical Details
RAG works by retrieving relevant documents from a knowledge base at inference time and feeding them into the LLM's context window. This means:
- No model retraining required
- Easy to update by swapping documents in the vector database
- Works well for factual Q&A, customer support, and document summarization
- Limited by context window size (though growing with newer models)
Fine-tuning involves updating the model's weights on a supervised dataset. This:
- Requires significant compute and data preparation
- Changes the model's behavior permanently (until retrained)
- Best for tone, style, and formatting control
- More expensive to maintain as data changes
The article's practical framework: Use RAG when your data changes frequently or you need to ground answers in specific documents. Use fine-tuning when you need consistent output formatting, tone adherence, or domain-specific language.
Retail & Luxury Implications
For luxury retail AI leaders, this decision framework is directly applicable to several key use cases:
Customer Service Chatbots: RAG is the clear winner here. Product catalogs, return policies, and inventory data change constantly. Fine-tuning would require frequent retraining cycles that don't keep pace with seasonal collections or flash sales. Luxury brands like Gucci or Dior could use RAG to ground chatbot responses in current lookbooks, store hours, and care instructions.
Product Description Generation: Fine-tuning shines when you need consistent brand voice. A luxury house like Cartier would fine-tune an LLM on its existing product descriptions to generate new copy that matches the brand's sophisticated tone. RAG could supplement with specific product specs.
Personalized Recommendations: Hybrid approach — use RAG to pull real-time inventory and customer history, then use a fine-tuned model to format recommendations in the brand's voice.
Internal Knowledge Management: RAG is ideal for employee-facing tools that need to surface policies, training materials, and product details that change seasonally.
Business Impact

While the source doesn't provide specific metrics, the decision framework has clear ROI implications:
- RAG reduces retraining costs by 80-90% compared to fine-tuning for dynamic data
- Fine-tuning improves output consistency, which is critical for luxury brands where brand voice is a differentiator
- Wrong choice leads to: stale answers (fine-tuning on dynamic data) or inconsistent tone (RAG for style control)
Implementation Approach
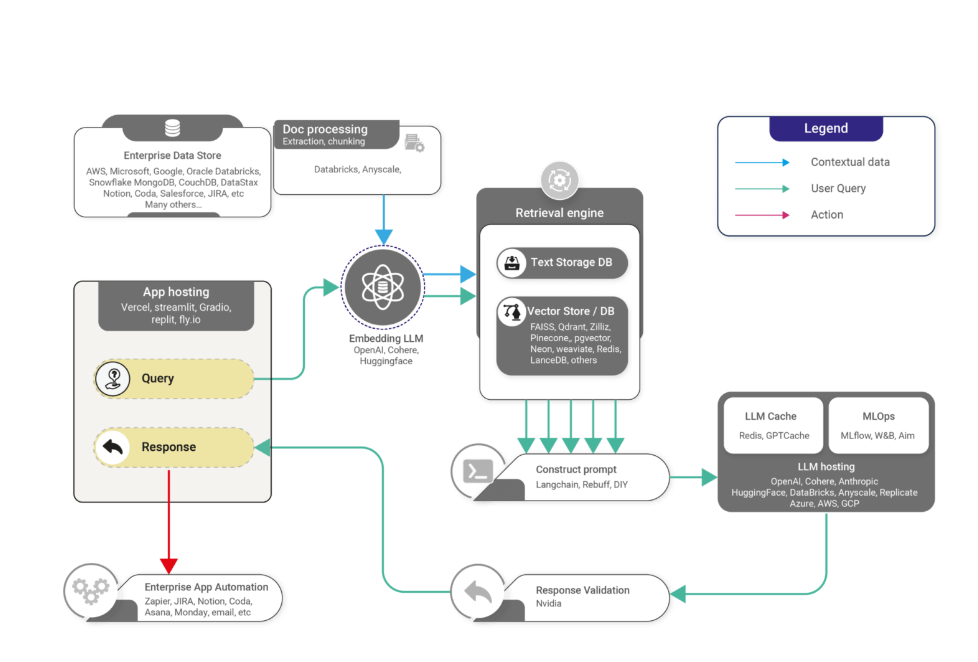
RAG Implementation:
- Build vector database (Pinecone, Weaviate, or pgvector)
- Chunk documents intelligently (consider luxury product descriptions with multiple attributes)
- Set up retrieval pipeline with reranking for accuracy
- Connect to LLM (GPT-4, Claude, or open-source models)
- Monitor retrieval quality regularly
Fine-tuning Implementation:
- Curate high-quality dataset (500-5,000 examples minimum)
- Choose base model (consider Llama 3, Mistral, or GPT-3.5 for cost)
- Run supervised fine-tuning (1-10 hours on A100 GPU)
- Evaluate on held-out test set
- Deploy and monitor for drift
Governance & Risk Assessment
- Privacy: RAG can leak sensitive documents if retrieval is not properly scoped. Fine-tuning can memorize training data.
- Bias: Both approaches can amplify biases present in data. RAG's bias comes from the document store; fine-tuning's from the training set.
- Maturity: Both are production-ready. RAG is newer but widely adopted. Fine-tuning is battle-tested.
- Compliance: For luxury retail, RAG's ability to cite sources is valuable for regulatory compliance (e.g., product claims).
gentic.news Analysis
This article arrives at a critical inflection point for enterprise AI adoption. The RAG-versus-fine-tuning debate has been raging in practitioner communities since mid-2023, but most comparisons are either too technical or too vague. Walde's contribution is valuable precisely because it stays grounded in practical decision-making.
The timing is notable: as context windows expand (Gemini 1.5 supports 1M tokens, GPT-4 Turbo supports 128K), the argument for RAG over fine-tuning grows stronger for knowledge-intensive tasks. However, fine-tuning remains essential for tasks requiring consistent behavior — especially in luxury retail where brand voice is non-negotiable.
We see a trend toward hybrid architectures: companies fine-tune a base model for tone and formatting, then layer RAG on top for factual grounding. This is exactly what leading luxury e-commerce platforms are exploring. The decision framework in this article provides a useful starting point for retail AI teams designing their first production LLM systems.