Key Takeaways
- A technical blog clarifies that Retrieval-Augmented Generation (RAG), fine-tuning, and prompt engineering should be viewed as a layered stack, not mutually exclusive options.
- It provides a decision framework for when to use each technique based on specific needs like data freshness, task specificity, and cost.
What Happened
A technical article on GeekyPy challenges the common perception that Retrieval-Augmented Generation (RAG), fine-tuning, and prompt engineering are competing methodologies for enhancing large language models (LLMs). Instead, the author argues they are complementary layers in a technical stack. The core premise is that teams often default to one approach without considering a layered strategy that could yield superior results. The piece aims to provide a practical decision framework to guide technical leaders in selecting and combining these techniques effectively.
Technical Details: The Layered Stack
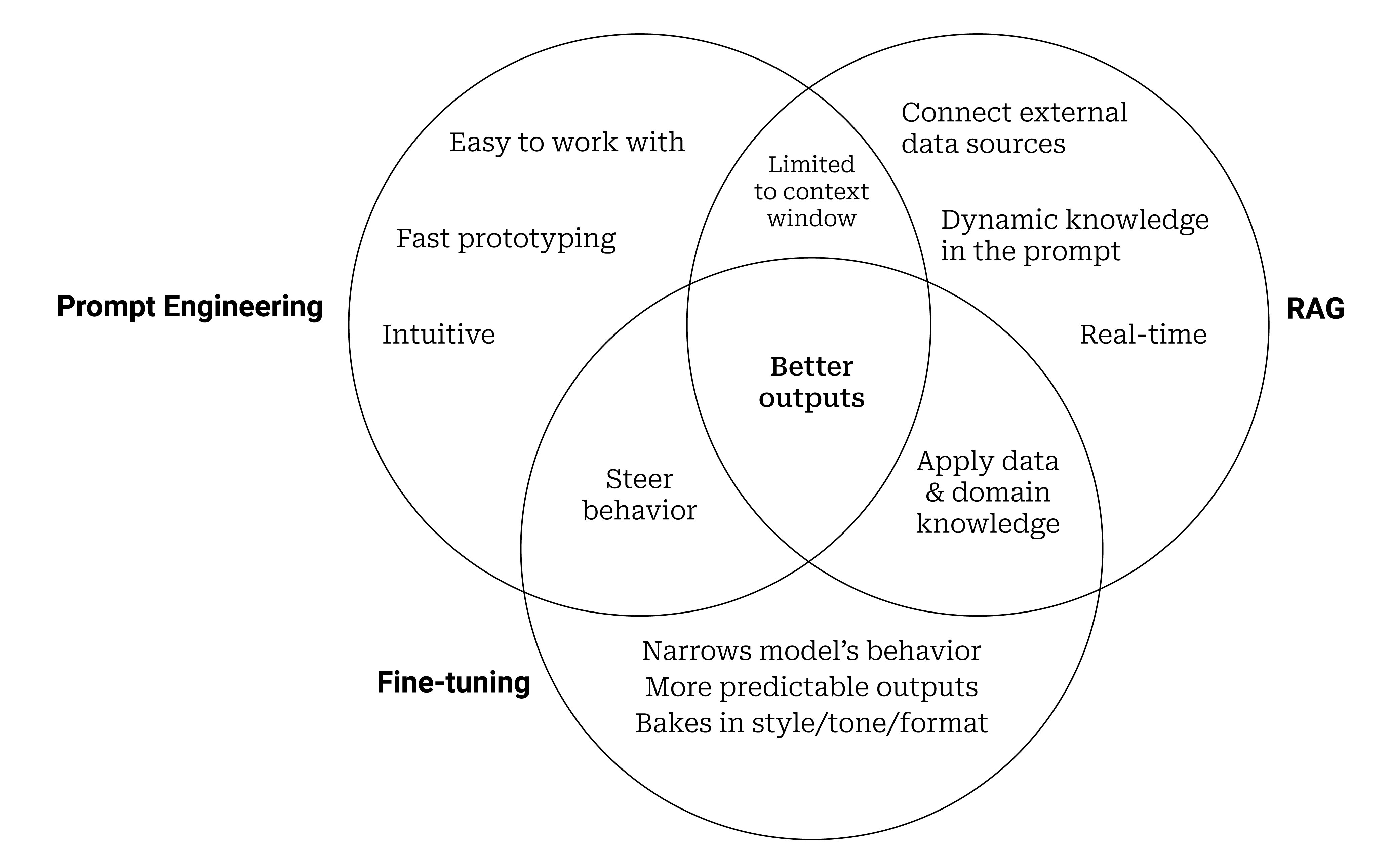
The framework positions these three techniques as addressing different fundamental problems in LLM application development:
- Prompt Engineering: This is the foundational layer, focused on instruction and context. It's about crafting the input to guide the model's behavior for a single query. It's fast, cheap, and requires no model changes, but is limited by the model's inherent knowledge and context window.
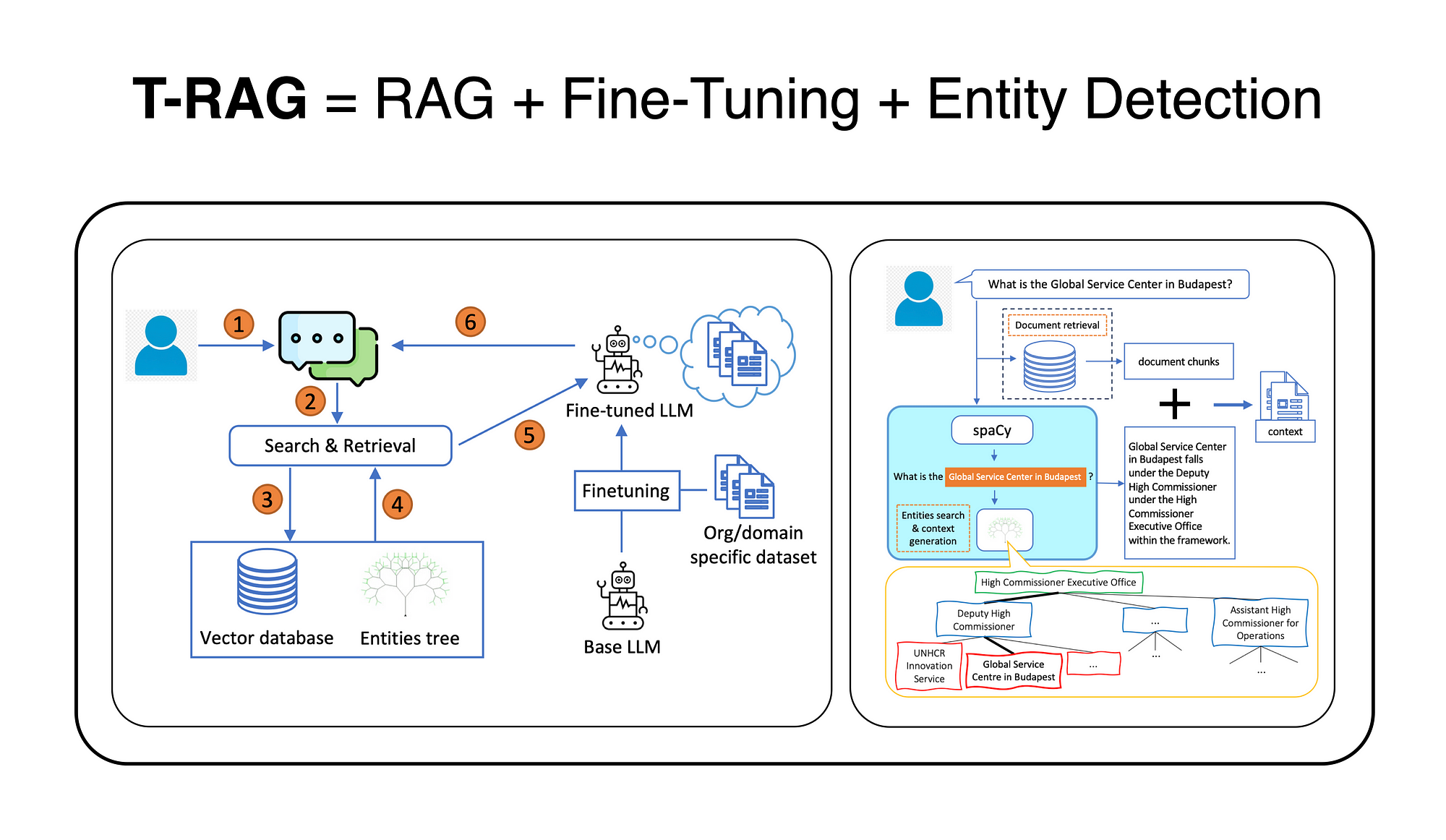
- Retrieval-Augmented Generation (RAG): This layer sits on top, solving the problem of knowledge and facts. RAG systems retrieve relevant information from external databases (like product catalogs, internal documents, or real-time inventory) and inject it into the prompt. This keeps the core model general while providing it with specific, up-to-date, or proprietary data it wasn't trained on.
- Fine-Tuning: This is the deepest layer, altering the model's behavior and style. It involves further training the base LLM on a specialized dataset to excel at a specific task (e.g., writing product descriptions in a brand's unique tone, classifying customer service emails, or generating specific code patterns). It changes the model's weights, making it more capable at its designated function but less general and more costly to implement and update.
The article's decision framework likely revolves around key questions:
- Is your data dynamic or static? For frequently updated information (pricing, inventory, policy changes), RAG is essential.
- Is the task generic or highly specialized? For unique brand voice or complex domain logic, fine-tuning may be necessary.
- What are your latency and cost constraints? Prompt engineering is instant and free; RAG adds retrieval latency; fine-tuning requires significant upfront compute and ongoing hosting costs for a custom model.
The optimal system often combines layers: a fine-tuned model for tone and task mastery, augmented by a RAG system for factual accuracy with current data, all orchestrated through carefully engineered prompts.
Retail & Luxury Implications
For retail and luxury AI leaders, this layered framework is directly applicable to the sector's most pressing AI use cases. The choice between—or combination of—these techniques dictates the quality, accuracy, and brand alignment of customer-facing and operational AI.
- Luxury Customer Service & Personal Shopping Assistants: A pure prompt-engineered chatbot on a general model will fail on brand ethos and product knowledge. A RAG layer pulling from the latest lookbooks, craftsmanship details, inventory, and client history is non-negotiable for accurate, personalized service. Fine-tuning could then be applied to ensure the assistant's communication reflects the brand's exclusive and consultative tone.
- Dynamic Product Catalog Enrichment: Generating descriptions for thousands of SKUs requires consistency. Fine-tuning a model on historical, brand-approved descriptions creates a specialist. However, to incorporate real-time data like a limited-edition drop's story or a collaboration's inspiration, a RAG system fetching from a CMS must augment the fine-tuned model.
- Internal Knowledge Management for Associates: An AI tool for store staff needs the most current information on promotions, return policies, and product care. This is a classic RAG use case, built over a vectorized knowledge base. The prompts must be engineered for concise, actionable answers.
The framework forces a strategic question: Are you building a general conversational interface (prompt engineering + RAG), or a domain-specific expert (fine-tuning + RAG)? For luxury, where brand equity is paramount, the investment in fine-tuning for stylistic control is often justified, but it remains crippled without RAG's access to the truth.