Key Takeaways
- GPT-5.5 Pro, tested by Ethan Mollick, excels at novel, hard problems including autonomous social science research and RPG design, though with some jaggedness.
- It is currently considered the best model for complex tasks.
What Happened

Ethan Mollick, a professor at Wharton known for his extensive AI testing, has shared early impressions of GPT-5.5 Pro after using it for several weeks. In a post on X, Mollick reports that the model conducted "not-bad social science research on its own" and developed a novel role-playing game (RPG), among other tasks. He notes that while there is still "jaggedness" in its performance, GPT-5.5 Pro is currently the best model for hard problems.
Context
This is a preliminary, hands-on assessment from a respected AI researcher and educator, not an official OpenAI announcement. The model name "GPT-5.5" suggests an incremental improvement over GPT-5, similar to how GPT-4.5 was a refined version of GPT-4. OpenAI has not publicly confirmed the existence or release timeline of GPT-5.5.
Key Observations
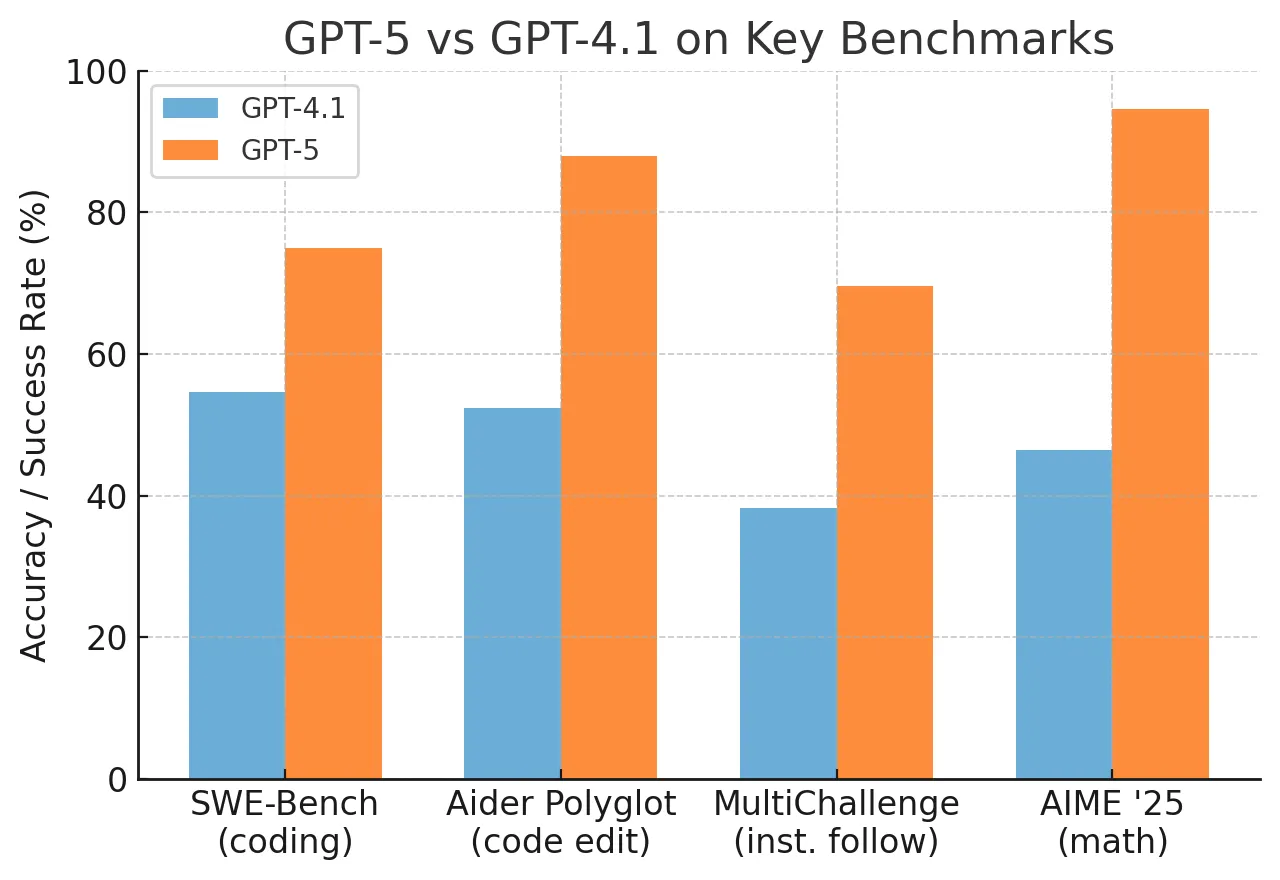
- Autonomous Research: The model conducted social science research independently, a task requiring multi-step reasoning, data analysis, and hypothesis testing.
- Creative Generation: It developed a novel RPG from scratch, indicating strong creative and world-building capabilities.
- Jaggedness: Mollick acknowledges that performance is not uniform — the model excels in some areas but shows inconsistency in others.
- Best for Hard Problems: Despite jaggedness, GPT-5.5 Pro is currently the top choice for complex, open-ended problems.
gentic.news Analysis
Mollick's assessment aligns with a pattern we've observed: frontier models are increasingly capable of autonomous, multi-step tasks. His mention of "jaggedness" is particularly important — it suggests that while raw capability has increased, reliability and consistency remain challenges. This echoes our previous coverage of GPT-5's uneven performance across different domains.
The fact that a respected academic is publicly endorsing GPT-5.5 Pro as the best model for hard problems is a strong signal. It indicates that OpenAI's iterative improvements (from GPT-5 to 5.5) are yielding tangible gains in practical, real-world reasoning — not just benchmark scores.
Frequently Asked Questions
What is GPT-5.5 Pro?
GPT-5.5 Pro is an unreleased model from OpenAI, reportedly an improved version of GPT-5. It has been tested by early users like Ethan Mollick, who describes it as currently the best model for hard problems.
When will GPT-5.5 be released?
OpenAI has not announced a release date for GPT-5.5. The model is in testing, and no official timeline has been provided.
How does GPT-5.5 compare to GPT-5?
Based on early testing, GPT-5.5 appears to be a significant improvement over GPT-5, particularly for complex, multi-step tasks. However, it still exhibits some jaggedness in performance.
Can GPT-5.5 conduct research autonomously?
According to Ethan Mollick, GPT-5.5 Pro conducted "not-bad social science research on its own," suggesting it can handle multi-step research tasks with minimal human guidance.