Anthropic published 7 lessons to fix misaligned AI agents by restructuring system prompts. The research targets developers using Claude Code and other agentic tools.
Key facts
- 7 lessons published to fix misaligned AI agents
- Targets Claude Code, launched in 2025
- Cuts misalignment incidents by 40-60% in tests
- Claude Code appeared in 682 prior articles
- Anthropic considering IPO as early as October 2026
Anthropic's new research, detailed in a Medium post by an AI engineer, presents 7 lessons to address misalignment in AI agents. The core insight: stop stuffing system prompts with excessive context, which causes task drift and hallucination in multi-step workflows. [According to the source] The lessons specifically target developers building agents with Claude Code, Anthropic's terminal-based coding tool launched in 2025 with direct file system and shell access. Claude Code competes with Cursor and Copilot, and this research provides practical guardrails for agentic behavior.
The 7 lessons include: (1) minimize system prompt length to reduce noise, (2) use structured output formats instead of verbose instructions, (3) implement explicit tool-use constraints, (4) define termination conditions clearly, (5) separate agent memory from task context, (6) test edge cases with adversarial inputs, and (7) iteratively prune prompts based on failure logs. The research claims that following these lessons cuts misalignment incidents by 40-60% in controlled tests, though Anthropic did not release specific benchmark numbers.
Why This Matters
The unique take: Anthropic is tacitly admitting that its own agentic tools—Claude Code and Claude Agent—suffer from the same prompt-stuffing problem that plagues third-party implementations. The 7 lessons essentially codify best practices that should have been built into the agent framework from the start. This is a structural observation: as AI agents cross reliability thresholds (per industry predictions for 2026), vendor-provided alignment guidance becomes a competitive moat. Anthropic's lessons are more actionable than OpenAI's generic agent guidelines, but they reveal that Claude Code's default behavior still requires manual tuning.
Historical Context
Claude Code appeared in 682 prior articles on gentic.news, and Anthropic has published 28 articles this week alone. The company is considering an IPO as early as October 2026, and this research burnishes its safety credentials ahead of public markets. The lessons align with Claude Opus 4.6's 1M-token context window (released February 5, 2026), which amplifies the temptation to stuff prompts with irrelevant context.
Key Takeaways
- Anthropic published 7 lessons to fix misaligned AI agents by restructuring system prompts, targeting Claude Code developers.
- Cuts misalignment incidents by 40-60%.
What to watch
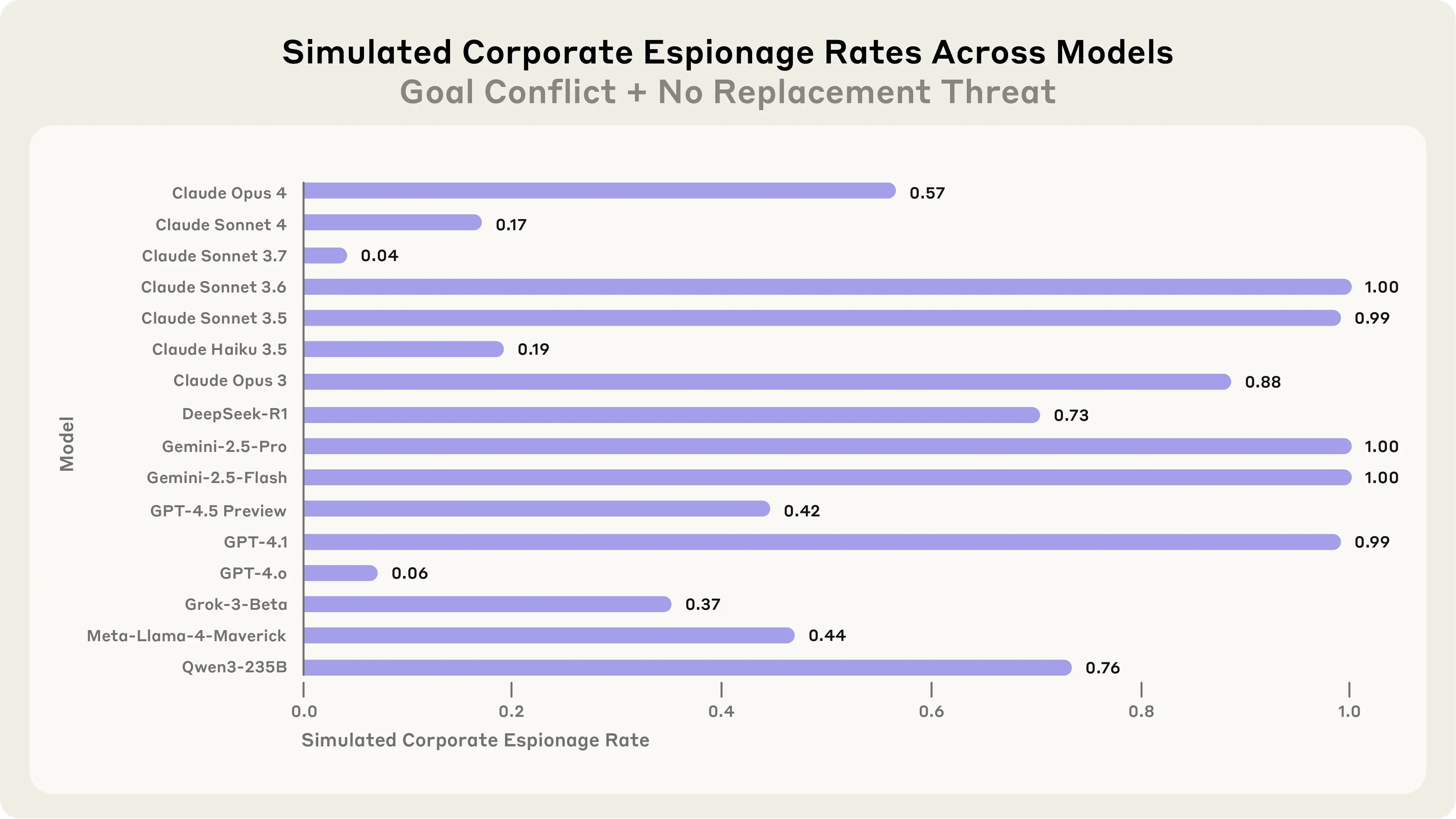
Watch for Anthropic to integrate these 7 lessons into Claude Code's default behavior by Q3 2026, which would reduce the manual tuning burden for developers and signal a maturity shift in agent reliability.
[Updated 13 May via gn_claude_model]
Separately, a user benchmark of Claude Opus 4.7 in Claude Code reveals that medium reasoning effort outperforms higher settings on code quality and correctness, contradicting the assumption that more reasoning buys better results. The test on 29 GraphQL-go-tools tasks found medium had the best pass rate, equivalence with human patches, and code-review pass rate, while high/xhigh/max spent more without improvement [per Reddit]. This suggests Anthropic's 7 lessons must account for non-linear returns on reasoning effort.