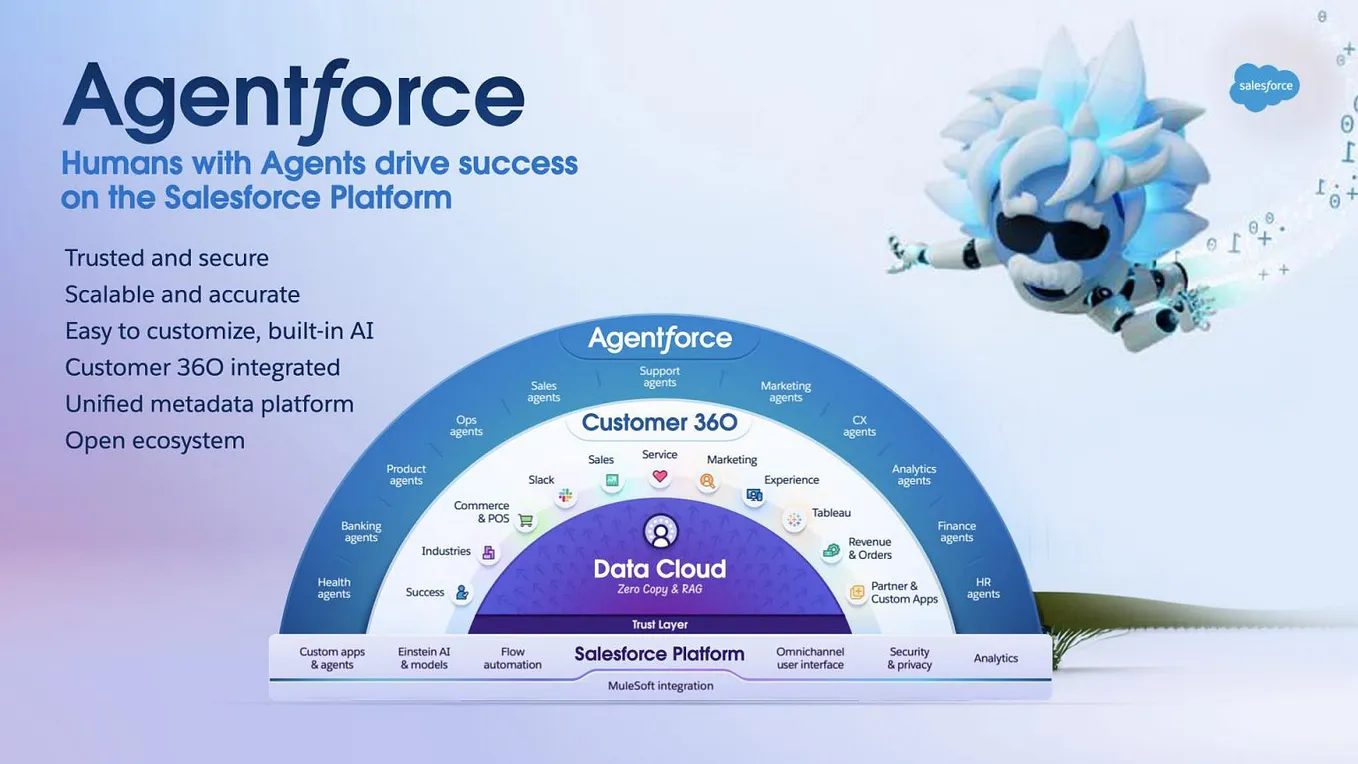
Astera Labs this week introduced its Scorpio X-Series 320-lane smart fabric switch, targeting idle GPU compute in hyperscaler clusters. The memory-semantic architecture cuts collective IO by 49%, according to analyst Brendan Burke of Futurum [per the source].
Key facts
- Scorpio X-Series has 320 lanes for high-radix fabric switching.
- Memory-semantic architecture enables load/store accelerator access.
- Analyst: cutting collective IO by 49% boosts GPU utilization.
- Shipments to hyperscalers began; broad ramp in H2 2026.
- Hypercast engine offloads collective operations into the fabric.
The gap between how AI clusters are designed and how they actually run is costing hyperscalers billions in idle compute. Astera Labs is attacking that mismatch with a new high-radix fabric switch that rethinks data movement at scale.
Key Takeaways
- Astera Labs introduced Scorpio X-Series 320-lane switch targeting 49% collective IO reduction for fragmented AI workloads.
- Shipments to hyperscalers began, with broad ramp in H2 2026.
The Fragmented Workload Problem
AI infrastructure has long assumed tightly coupled, continuous execution. That assumption is eroding as training and inference increasingly branch, pause, and wait on data or external calls. Matt Kimball, vice president and principal analyst at Moor Insights & Strategy, called the mismatch a primary source of inefficiency [per the source].
“These workloads aren’t clean, continuous jobs,” Kimball said. “They pause, they branch, they wait on data or external calls. But infrastructure is still often provisioned as if everything is tightly coupled. That gap is where utilization starts to fall apart.”
Astera's answer is the Scorpio X-Series, a 320-lane smart fabric switch using a memory-semantic architecture. Instead of layering software overhead for every data movement, accelerators access shared resources via load/store operations directly. Ahmad Danesh, associate vice president of the Compute Connectivity Group at Astera Labs, explained the impact of uneven communication paths [per the source].
“When some GPUs see one hop and others see three, the longest path dictates completion time,” Danesh said. “That leaves faster paths underutilized while others wait on data.”
The 49% Collective IO Reduction
Brendan Burke, research director at Futurum, quantified the gain: cutting collective IO by 49% means GPUs spend dramatically more time on actual computation [per the source]. At hyperscale, that efficiency translates into better tokens per watt and faster model iteration cycles.

Astera is also pushing in-network compute through its Hypercast engine, offloading collective operations into the fabric. This approach does not address scheduling or fragmentation at the application layer. But it removes friction in one of the hardest places to optimize: moving data between components at scale.
“It doesn’t solve everything,” Kimball said. “But it addresses one of the harder problems to fix. As AI infrastructure scales, that kind of architectural shift becomes more important.”
Shipments to hyperscalers have begun, with a broader production ramp expected in the second half of 2026. The company did not disclose pricing or specific customers.
What to watch
Watch for hyperscaler adoption disclosures in Q3 2026 earnings calls, and whether the Scorpio X-Series appears in reference architectures from NVIDIA or AMD. A competing high-radix switch from Broadcom or Marvell could emerge within 12 months.