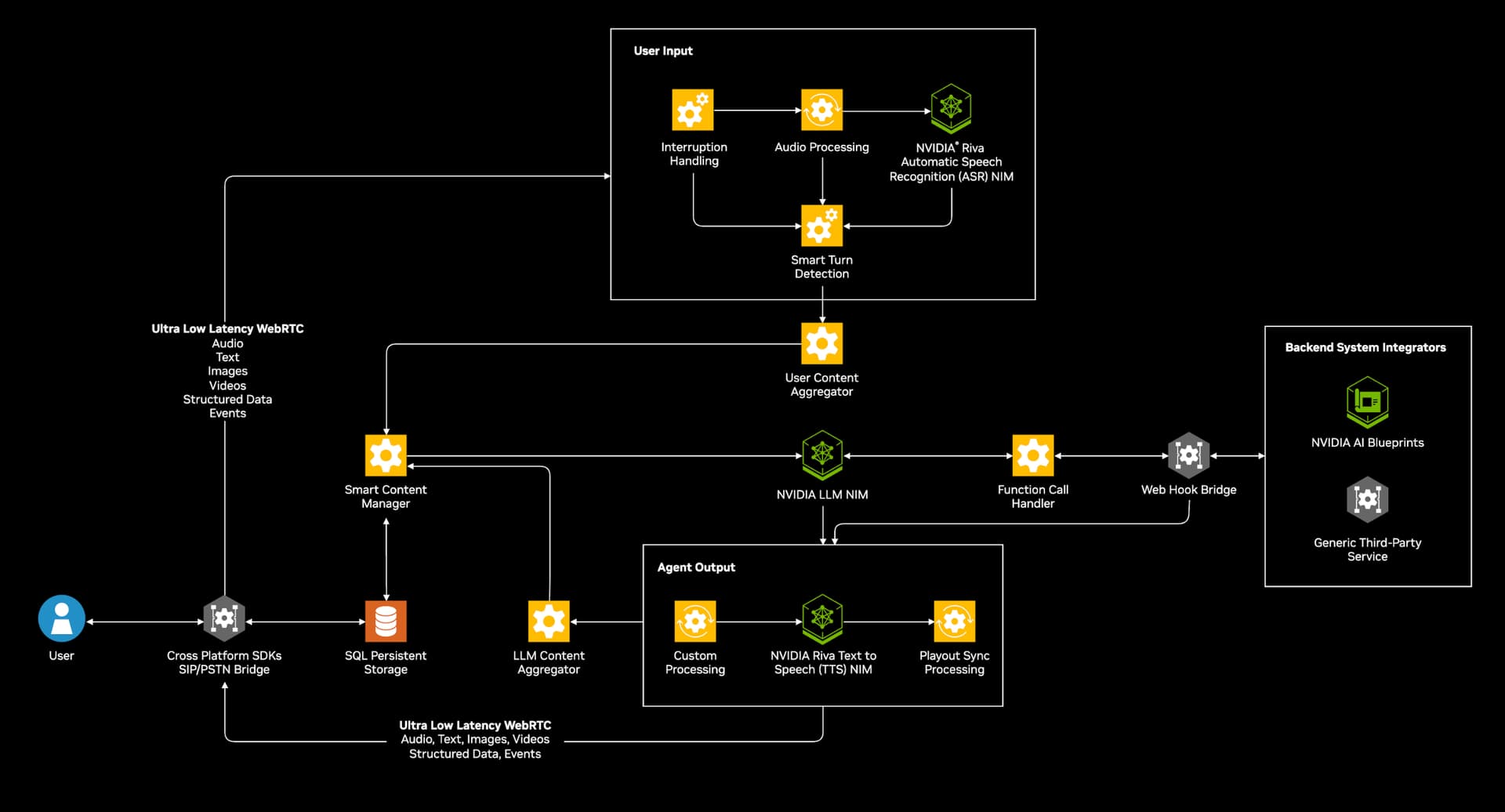
Voice AI fundamentally changes the user experience contract. As the author of a recent technical case study discovered, a two-second delay that feels acceptable in a text chatbot becomes awkward and disruptive in a voice interaction. Users wonder if they were heard, if the system failed, or if they should repeat themselves. This inherent intolerance for latency was the central challenge in building a voice-first journal application, powered by Sarvam AI for speech processing and the Redis Agent Memory Server for its core intelligence: memory.
This is a deep dive into the architectural patterns and hard-won optimizations that make a conversational voice agent feel personal and responsive.
The Innovation: A Purpose-Built Memory Architecture
The app's premise is straightforward: a user speaks, the app transcribes the audio, determines intent (e.g., save a note or ask a question), fetches relevant context from memory, and responds in voice. The complexity lies in the memory layer.
Without memory, a voice assistant is stateless—a tool, not a companion. It cannot recall past conversations, user preferences, or emerging patterns. The developer's goal was to enable memory across sessions (long-term) while maintaining coherent context within a single interaction (working memory).
The solution was built around the Redis Agent Memory Server, which provided two essential memory types:
- Working Memory: A short-term scratchpad for the active session's conversation flow.
- Long-Term Memory: Persistent storage for journal entries, mood signals, and other details that should be recalled in future sessions.
This separation is crucial. Treating every spoken turn as equally important creates noise. Voice interactions are full of filler—corrections, pauses, and half-thoughts. The system must be intentional about what it stores, how it's categorized, and how it's retrieved.
For example, when a user logs a journal entry, it's written directly to long-term memory as an episodic memory—tied to a personal experience. Lighter conversational turns stay in working memory. This intentionality is reflected in the code, where each memory record includes a memory_type, user_id, session_id, namespace, and topics for precise filtering later.
Why This Matters for Retail & Luxury
While the case study focuses on a personal journal app, the architectural principles are directly transferable to high-touch retail and luxury clienteling. The core challenge—creating a low-latency, memory-aware conversational interface—is identical.
Concrete Applications:
- Voice-Enabled Virtual Personal Shoppers: Imagine a client calling their dedicated concierge line. An AI agent, with a robust memory layer, could instantly recall the client's size, color preferences, past purchases, and even notes from their last styling session (e.g., "looking for a dress for the Cannes gala"). The conversation would be seamless and deeply personalized, mirroring the relationship with a human advisor.
- In-Store Assistant Integration: Staff using AR glasses or handheld devices could query a voice agent for a client's profile. The agent could pull long-term memory (purchase history, style profile) and working memory (items they've tried on in the last 30 minutes) to provide real-time, context-aware suggestions.
- Post-Purchase Engagement: A follow-up call or voice message from a "brand companion" could check in on a product, offering care tips based on the specific item purchased (long-term memory) and referencing the conversation at the point of sale (working memory).
The memory model described—separating ephemeral session data from persistent client knowledge—is precisely what's needed to power these use cases without creating a chaotic, noisy data dump.
Business Impact: From Transactional to Relational
The business impact of implementing such a system is a shift from transactional interactions to sustained, relational clienteling. Quantifying this involves key luxury metrics:
- Client Lifetime Value (CLV): A memory-powered agent can make more relevant recommendations, increasing repeat purchase rates and average order value.
- Client Retention: Personalized, frictionless service builds emotional loyalty, reducing churn to competitors.
- Operational Efficiency: Empowering human associates with instant, comprehensive client context reduces briefing time and increases the quality of every customer interaction.
However, the source material does not provide quantified business results; it is a technical blueprint. The impact is potential, hinging on flawless execution. This aligns with a concerning trend identified in our Knowledge Graph: a recent report revealed 86% of AI agent pilots fail to reach production, highlighting the gap between architectural promise and operational reality.
Implementation Approach: A Latency-First Mindset
The article's most valuable insights are the concrete optimizations for voice latency. For retail, where a slow response breaks the illusion of exclusive, attentive service, these are non-negotiable:
- Streaming Speech APIs: Using streaming for both speech-to-text and text-to-speech allows processing to begin before the user finishes speaking and audio playback to start before the full response is synthesized. "First audio byte matters more than total completion time."
- Parallel Fetches: Context gathering—fetching working memory, relevant long-term memories, and inventory data—should happen concurrently, not sequentially, to minimize the total silence perceived by the user.
- Bounded, Semantic Retrieval: The system retrieves only the top 5 most relevant memories and often uses just the top one to anchor the response. This keeps the prompt small, generation fast, and the reply focused—critical for a concise voice interaction.
- Semantic Routing for Intent: Instead of using a large, slow LLM to classify every user request (e.g., "log this," "what did I buy last month?"), the developer used RedisVL semantic router, a faster, lighter model, to direct traffic before the main LLM generates a response.
- Short, Purposeful Responses: Voice replies are kept to one or two crisp sentences. This reduces generation and speech synthesis time, maintaining a natural conversational rhythm.
Governance & Risk Assessment
Implementing a persistent memory layer for luxury clients introduces significant governance challenges:
- Privacy & Data Sovereignty: Storing episodic memories of client conversations is sensitive. Compliance with GDPR, CCPA, and internal brand privacy policies is paramount. Data must be encrypted, access-controlled, and deletable upon client request.
- Bias & Hallucination: The memory retrieval is semantic. If biased data is stored (e.g., making assumptions about a client's budget based on past purchases), it will be recalled and amplified. Rigorous data curation and monitoring are required.
- Maturity Level: The technology stack (Redis Agent Memory Server, Sarvam AI, semantic routers) is emerging. While promising, it requires specialized MLOps expertise to deploy and maintain at a luxury-grade reliability level. The high failure rate of AI agent pilots, as noted in our KG, underscores this risk.
gentic.news Analysis
This technical deep dive arrives at a pivotal moment for AI Agents in commerce. Our Knowledge Graph shows AI Agents have been mentioned in 197 prior articles, with a significant trend of 26 articles this week alone, indicating intense industry focus. The developer's pragmatic approach—focusing on a structured memory layer and ruthless latency optimization—directly addresses one of the key failure points we've recently covered.
On 2026-04-04, we reported on a new research paper identifying multi-tool coordination as the primary failure point for AI agents. This case study can be seen as a practical response: by using Redis Agent Memory Server as a central, orchestrated memory service and parallelizing fetches, the developer simplifies the coordination problem. Furthermore, the use of semantic routing (RedisVL) to avoid an LLM call for simple intent detection is an excellent example of the "right tool for the job" philosophy needed to build robust agents.
The article also connects to the broader ecosystem. The use of GitHub (mentioned in 75 prior articles) as the likely platform for such open-source tools like Redis Agent Memory Server is standard. More notably, our KG shows Shopify is already using AI Agents, suggesting the retail platform world is actively experimenting with this architecture. For luxury houses, the lesson is clear: the foundational work for agentic clienteling is being laid in open source and adjacent industries. The winning implementation will be the one that masters these architectural patterns—especially memory and latency—while layering on the unparalleled data quality and privacy standards the luxury sector demands.
This blueprint demonstrates that the path to a truly intelligent voice assistant isn't just about a better LLM; it's about designing a memory and retrieval system that is fast, intentional, and built for conversation.