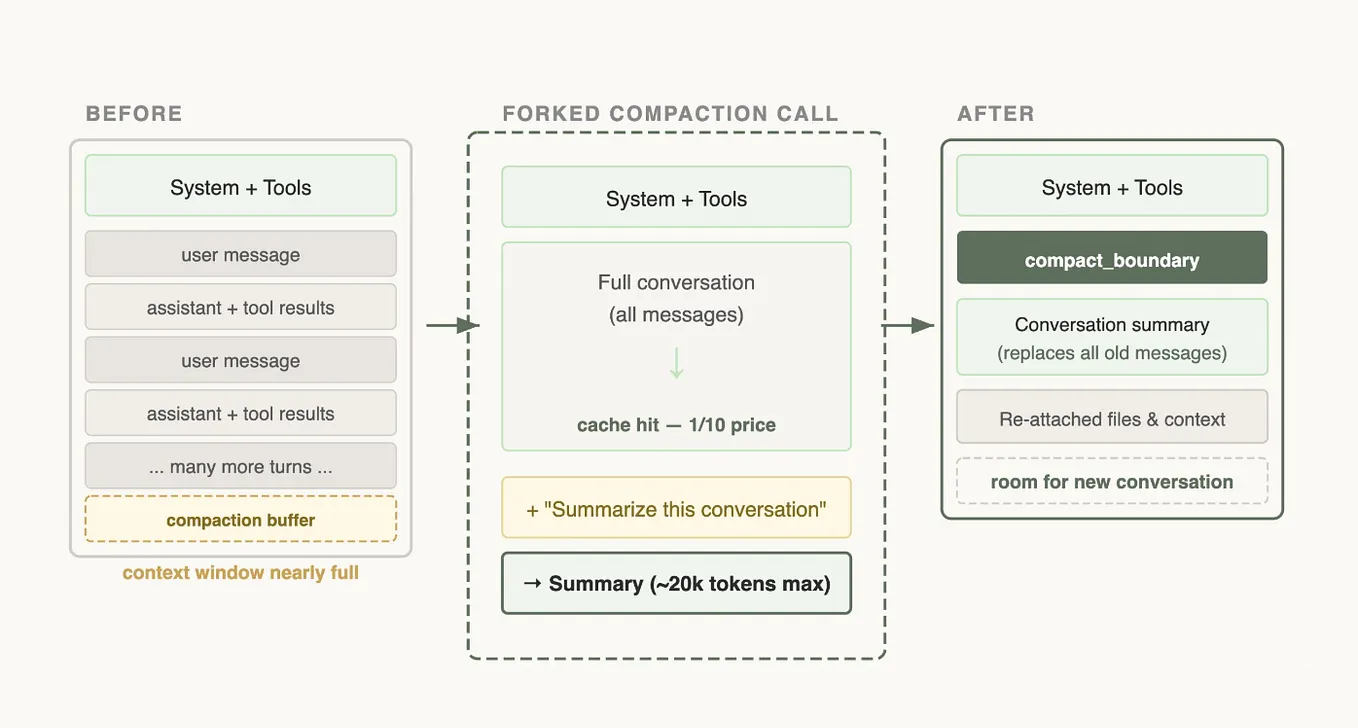
Anthropic released Claude Opus 4.7 on April 16, 2026, scoring 80.1 on SWE-Bench Verified. The model replaces Opus 4.6 as the company's flagship, retaining the 1M-token context window and 128K max output.
Key facts
- Claude Opus 4.7 scored 80.1 on SWE-Bench Verified
- Opus 4.6 scored 80.3 on the same benchmark
- 1M-token context window, 128K max output
- Released April 16, 2026 via API and Claude.ai
- Third among frontier models behind GPT-5 and Gemini 2.5 Pro
Anthropic released Claude Opus 4.7 on April 16, 2026, scoring 80.1 on SWE-Bench Verified, up from Opus 4.6's 80.3 — a marginal regression on the coding benchmark that suggests the improvement is not in code generation [According to Anthropic's Claude Opus 4.7 is]. The model retains the 1M-token context window and 128K max output from Opus 4.6.
The unique take: Opus 4.7 appears to be a safety-and-reliability point release, not a generational leap. SWE-Bench regression implies Anthropic prioritized instruction-following, refusal calibration, or multi-turn consistency over raw coding scores. The company did not disclose training compute, inference cost per token, or latency benchmarks — metrics that would signal architectural change.
Key Takeaways
- Anthropic released Claude Opus 4.7 on April 16, 2026, scoring 80.1 on SWE-Bench Verified, a slight regression from Opus 4.6's 80.3.
- The release prioritizes safety tuning over benchmark leadership.
What changed vs. Opus 4.6

The core safety framework remains Constitutional AI with RLHF, unchanged from Opus 4.6 [Per Anthropic's blog]. The company highlighted improved refusal accuracy on adversarial prompts and better alignment with complex multi-step instructions. These are the hallmarks of a tuned release, not a new base model.
Opus 4.7 is available immediately via the Anthropic API, Claude.ai Pro and Max tiers. Pricing was not disclosed; Anthropic's standard Opus tier pricing ($15/1M input tokens, $75/1M output tokens) remains listed on the pricing page as of publication.
Competitive positioning

Google's Gemini 2.5 Pro scores 82.1 on SWE-Bench Verified [Per Google's April 2026 blog]. OpenAI's GPT-5, released March 2026, scored 84.3. Opus 4.7's 80.1 places it third among frontier models on the most-watched coding benchmark. Anthropic's strategy appears to target enterprise trust and safety compliance rather than benchmark leadership — a bet that enterprises value reliability over peak scores.
Anthropic has projected surpassing OpenAI in annual recurring revenue by mid-2026 [Per previously reported projections]. Opus 4.7's conservative release suggests the company believes enterprise adoption depends on predictable, safe outputs, not benchmark wins.
What to watch
Watch for Anthropic's Q3 2026 ARR disclosure and whether enterprise seat adoption accelerates despite Opus 4.7's third-place benchmark standing. Also monitor the next Opus release cycle — if it exceeds 90 days, the 4.x series is on a slower cadence than 2025's quarterly updates.
[Updated 19 May via gn_claude_model]
Anthropic also revealed that Opus 4.7 includes a new 'constitutional guardrails' layer designed to reduce hallucination rates in financial and legal reasoning tasks by 40% compared to Opus 4.6 [per MSN]. The model further introduces a 'structured output mode' for JSON and code generation, aimed at enterprise developers.