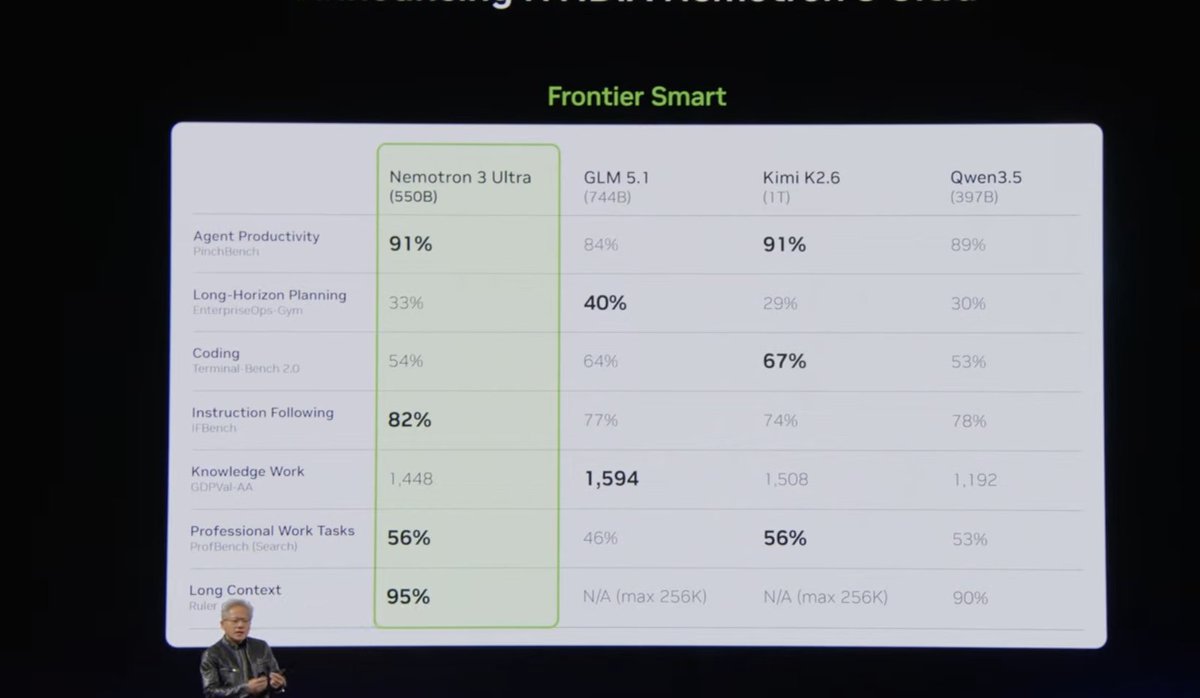
A recent social media post from a prominent AI commentator highlights a claimed breakthrough for Zhipu AI's GLM-5.1 model: the ability to autonomously evaluate and improve its own work over extended periods without relying on explicit, pre-defined human metrics.
What Happened
The claim, originating from an X (formerly Twitter) post, states that the GLM-5.1 model has demonstrated a capability to shift from producing "one-shot outputs" to engaging in "sustained, self-directed problem solving." The core assertion is that the model can perform a form of recursive self-improvement, where it iteratively assesses its own outputs and refines them over time, all without a human in the loop to provide a scoring function or reward signal for each step.
This represents a move beyond standard inference or even chain-of-thought reasoning, suggesting the model can plan and execute multi-step improvement cycles autonomously. The post links to an external source, but the primary announcement is contained within this brief social media claim.
Context
Zhipu AI, a leading Chinese AI company backed by Tsinghua University, has been a significant player in the large language model race. Their GLM (General Language Model) series has served as China's primary open-source alternative to models like LLaMA and GPT. The progression from GLM-3 to GLM-4 showed substantial gains in reasoning and tool-use capabilities.
The concept of "self-improving" AI is a long-standing goal in the field, often associated with recursive self-improvement and the path toward Artificial General Intelligence (AGI). Current methods typically require human-defined evaluation metrics (like code correctness or answer accuracy) or reinforcement learning from human feedback (RLHF). A model that can generate its own internal criteria for "improvement" and act on them would be a significant, albeit preliminary, step toward more autonomous AI systems.
The Technical Claim
The brief description suggests two key technical leaps:
- Autonomous Evaluation: The model can critique its own work without a human-provided rubric or reward model. This implies the development of an internal "critic" module or meta-cognitive capability.
- Sustained Refinement: The model can act on that critique over "long periods," implying it can plan and execute a sequence of refinements, maintaining context and a coherent improvement trajectory across multiple inference steps.
If validated, this would place GLM-5.1 in a novel category beyond today's state-of-the-art models, which, while capable of reflection and revision, generally operate within a single session or require human guidance for multi-step optimization.
What to Watch
As this is a claim made via social media, independent verification and detailed technical reports are crucial. Key questions include:
- Scope: On what types of tasks does this self-improvement work (coding, writing, reasoning)?
- Limits: How many iterative steps can it sustain before performance degrades or it diverges?
- Benchmarks: Are there quantitative results showing measurable improvement in output quality over these autonomous cycles?
- Architecture: Is this an emergent property of a scaled-up base model, or does it rely on a specific novel training technique or architectural component?
The AI community will be looking for a formal paper or technical report from Zhipu AI detailing the methods, providing benchmarks, and defining the boundaries of this claimed capability.
gentic.news Analysis
This claim, if substantiated, fits directly into the intensifying global competition for AI primacy, particularly between US and Chinese labs. Zhipu AI, with its strong academic ties and government backing, has consistently positioned the GLM series as a sovereign technology stack. A breakthrough in autonomous learning would be a major strategic win. It aligns with a broader trend we've covered, where research is shifting from pure scale to novel training paradigms and agentic capabilities, as seen in projects like Google's SIMA or Meta's research on self-improving code models.
However, extreme caution is warranted. The field has a history of over-interpreting limited demonstrations of "self-improvement." True, stable, and general recursive self-improvement remains an unsolved problem. The critical next step is transparency: Zhipu AI needs to release not just a demo but a reproducible evaluation framework. Does the model's "self-directed" improvement align with human judgment of quality, or could it optimize toward a strange, internal objective? The risk of reward hacking or divergence is high in such setups.
Practitioners should watch for two things: 1) the release of a technical report with hard numbers on benchmark improvement across iterative cycles, and 2) the open-sourcing of the model or its training methodology. Without these, the claim remains an intriguing but unverified signal from a highly competitive segment of the AI landscape.
Frequently Asked Questions
What is GLM-5.1?
GLM-5.1 is the latest reported iteration of the General Language Model series developed by Chinese AI company Zhipu AI. It is positioned as a state-of-the-art large language model and a key part of China's domestic AI ecosystem.
What does "autonomous self-improvement" mean for an AI model?
It means the model can evaluate the quality of its own outputs and generate improved versions over multiple steps without human intervention. Instead of needing a human to score each attempt or provide explicit instructions for revision, the model uses its own internal criteria to guide a sustained refinement process.
How is this different from a model just thinking step-by-step?
Standard chain-of-thought reasoning involves breaking down a single problem. Autonomous self-improvement implies the model can tackle a complex task, produce an initial solution, identify flaws in that solution on its own, and then execute a plan to fix those flaws, potentially over many cycles. It's a meta-cognitive loop of output, evaluation, and action.
Has this capability been proven?
As of this reporting, the capability is based on a claim made in a social media post. The AI community is awaiting formal publication of technical details, evaluation methodologies, and benchmark results from Zhipu AI to independently assess the validity and scope of the claim.