
Key Takeaways
- A tweet from @scaling01 claims to show GPT-5.5 benchmarks, but no official data from OpenAI has been released.
- The source is unverified and lacks methodology or reproducibility details.
What Happened
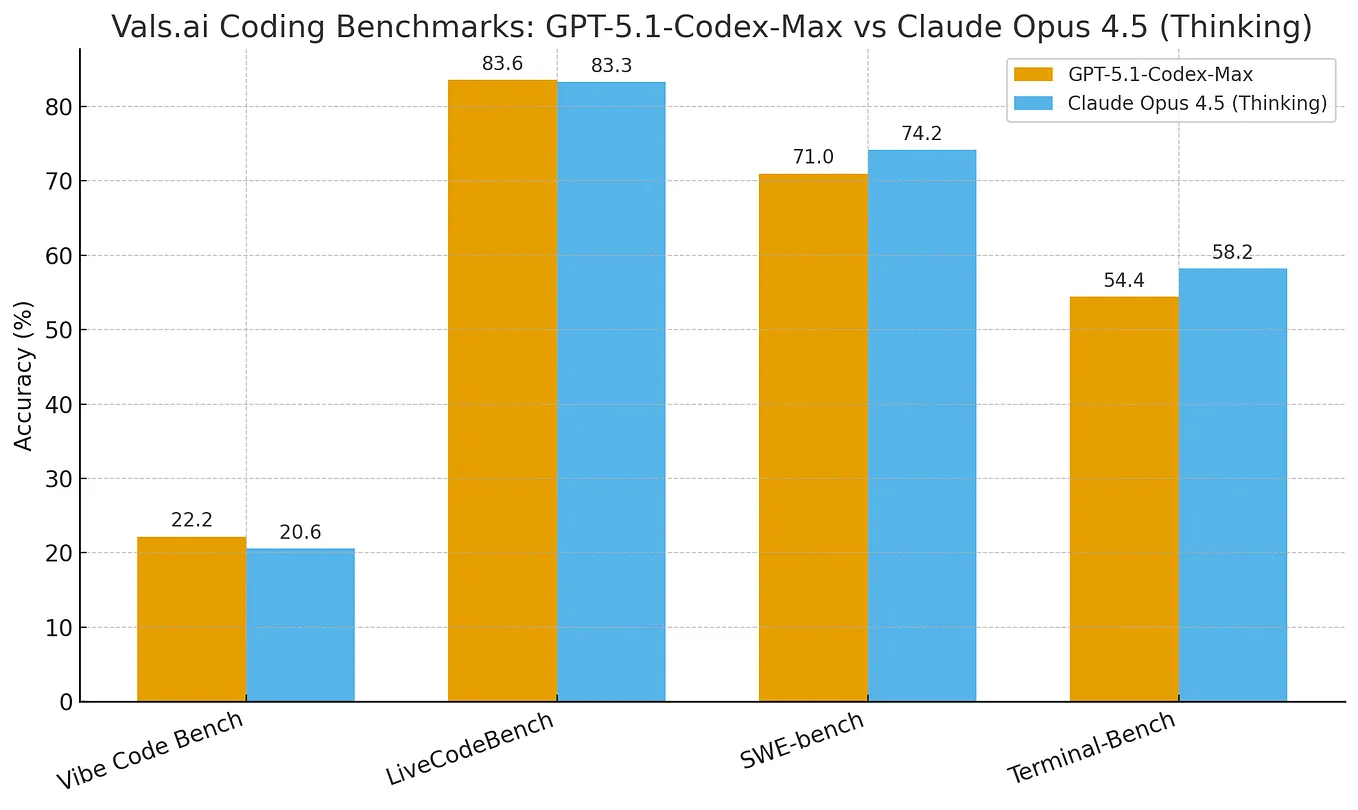
On April 4, 2026, a tweet from the account @scaling01—retweeted by @mweinbach—claimed to show benchmarks for "GPT-5.5," a potential update to OpenAI's GPT-5 model. The tweet includes a link to a purported set of benchmark results, but the destination URL (https://t.co/aCD9byiHRq) was not accessible at the time of writing. No official announcement from OpenAI or any verified source has confirmed the existence of GPT-5.5.
The tweet itself is brief: "GPT-5.5 Benchmarks" with a link. No additional context, methodology, or comparison to prior models was provided.
Context
GPT-5 was released by OpenAI in late 2025, following the GPT-4 series. It introduced significant improvements in reasoning, multimodal capabilities, and agentic workflows. A "5.5" version would imply an incremental update—likely focused on fine-tuning, cost reduction, or specific domain performance—rather than a major architectural shift.
OpenAI has historically released intermediate model versions (e.g., GPT-3.5 between GPT-3 and GPT-4), but these were typically accompanied by official blog posts, API documentation, and benchmark disclosures. The lack of any such communication here makes this claim highly suspect.
What This Means in Practice
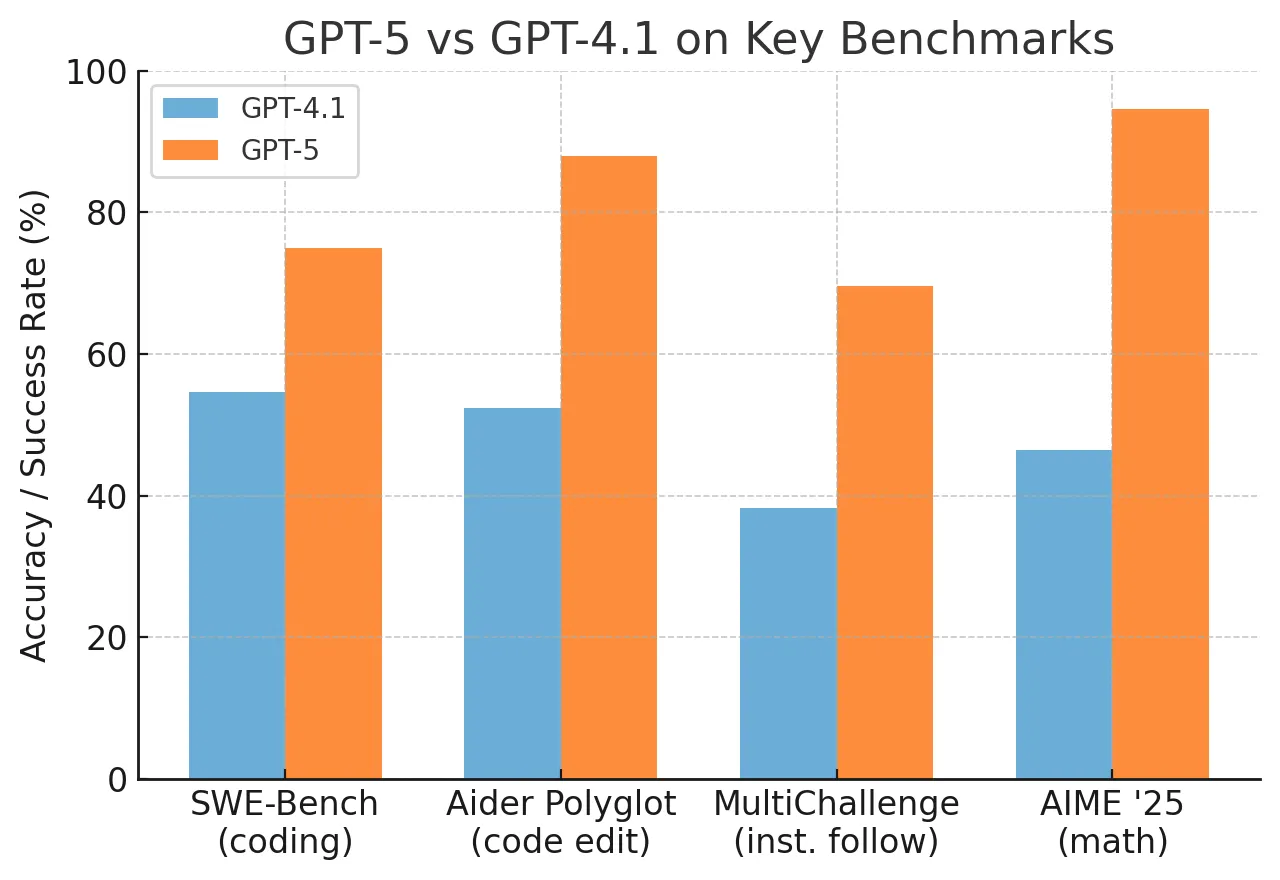
Until OpenAI publishes official benchmarks or releases model weights, practitioners should treat this as unsubstantiated speculation. If GPT-5.5 does exist, it would likely target improved efficiency or specialized task performance rather than a broad capability jump. The AI community should wait for verified data before making any decisions based on these claims.
Frequently Asked Questions
Is GPT-5.5 real?
There is no official confirmation from OpenAI. The only source is an unverified tweet from @scaling01 with no accompanying data or methodology. Treat this as rumor until proven otherwise.
How would GPT-5.5 compare to GPT-5?
If it follows the pattern of GPT-3.5, it would be a refined version of GPT-5—potentially faster, cheaper, or better at specific tasks—but not a fundamental architecture change. No comparison data is available.
Where can I find official OpenAI benchmarks?
OpenAI publishes model cards and benchmark results on their official website and in research papers. Check https://openai.com/index/ for verified information.
Should I change my AI workflow based on this tweet?
No. Wait for official communication from OpenAI. Relying on unverified benchmarks can lead to poor engineering decisions and wasted resources.








