
Key Takeaways
- A new arXiv paper proposes using Multimodal LLMs (MLLMs) for instance-level image-to-image retrieval.
- By prompting models with paired images and converting next-token probabilities into scores, the method enables training-free re-ranking.
- It shows superior robustness to clutter and occlusion compared to specialized models, though struggles with severe appearance changes.
What Happened
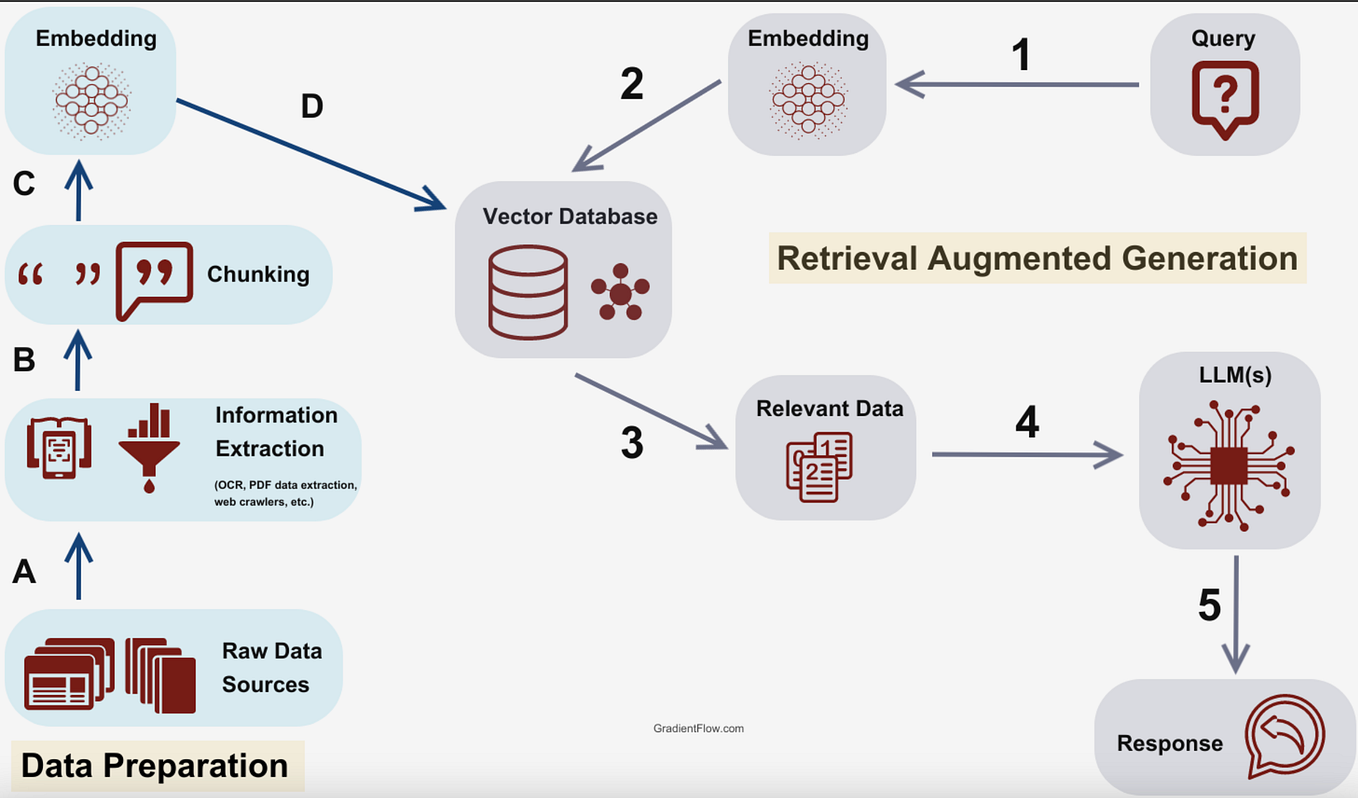
A new research paper, "Indexing Multimodal Language Models for Large-scale Image Retrieval," was posted to arXiv on April 14, 2026. The core thesis is that Multimodal Large Language Models (MLLMs), typically celebrated for cross-modal tasks like image captioning or visual question answering, possess a significant and underexplored capability for vision-only tasks. Specifically, the authors investigate using these models as training-free similarity estimators for the challenging problem of instance-level image-to-image retrieval.
The standard pipeline for large-scale image retrieval involves a fast, approximate first-pass search (e.g., using a vector database with embeddings from a model like CLIP) to retrieve a large candidate set (top-k). A more accurate, but computationally expensive, re-ranking step then refines these results. This research posits that MLLMs can serve as a powerful, zero-shot re-ranker.
Technical Details
The proposed method is elegantly simple, avoiding specialized architectures or fine-tuning. It leverages the rich visual discrimination MLLMs learn during their multimodal pre-training on vast image-text datasets.
- Similarity Estimation via Prompting: The model is prompted with a pair of images—a query image and a candidate image from the initial retrieval—alongside a textual prompt designed to elicit a comparison. A common template might be: "Are these two images showing the same object?"
- Probability-to-Score Conversion: The model's next-token prediction probabilities for affirmative responses (e.g., "Yes") are interpreted as a similarity score. A higher probability indicates the model believes the images are of the same instance.
- Scalable Integration: To make this feasible for large-scale retrieval with millions of images, the method is not applied to all possible pairs. Instead, it is used only to re-rank the top-k candidates (e.g., 100-1000 images) returned by a fast, memory-efficient first-stage retriever. This hybrid approach balances accuracy with computational feasibility.
Key Findings from Experiments:
- Out-of-Domain Superiority: MLLMs used in this zero-shot manner outperformed task-specific re-ranking models when evaluated on benchmarks outside the re-ranker's native training domain. This highlights their generalizability.
- Robustness: The approach exhibited superior robustness to real-world nuisances like background clutter, partial occlusion, and the presence of small objects—common challenges in product and fashion imagery.
- Identified Failure Mode: The primary weakness emerged under conditions of severe appearance change, such as extreme viewpoint variation or drastic alterations in lighting and color. This points to a limitation in the current visual grounding of MLLMs.
The research concludes that MLLMs represent a promising, alternative pathway for "open-world" large-scale image retrieval, where the system must handle a vast and unpredictable array of objects without task-specific training.
Retail & Luxury Implications
This research, while fundamental, points to a tangible evolution in a core retail AI capability: visual search. The implications are most relevant for teams managing visual search engines, recommendation systems, and inventory management tools.
Potential Applications:
- Enhanced Visual Search & Discovery: A customer could upload a photo of a handbag seen on the street (with clutter, poor lighting). A first-stage retriever finds broadly similar bags. This MLLM-based re-ranker could then more accurately identify the exact model or the closest in-stock match by being robust to the occlusions and background in the user's photo.
- Deduplication & Asset Management: For e-commerce teams managing millions of product images—studio shots, user-generated content, influencer photos—this technique could improve automatic detection of duplicate or near-identical products across different shoots or marketplaces, even when presentation varies.
- Cross-Channel Style Matching: Identifying the same garment or accessory appearing in a runway show, a magazine editorial, and a social media post is a classic instance-retrieval problem. The noted robustness to occlusion and clutter could improve the accuracy of these cross-channel linking systems.
The Critical Gap: The paper's major caveat—failure under severe appearance change—is highly relevant to retail. A product image in a bright white studio versus in a dark, moody lifestyle shot represents a "severe appearance change." Direct application today would likely falter here. Furthermore, the computational cost of using large MLLMs for re-ranking, even on a top-100 set, is non-trivial for real-time, customer-facing applications. This is currently a research insight, not a production-ready recipe.
The value for technical leaders is in the direction of travel. It suggests that the massive investments in general-purpose multimodal foundation models may yield unexpected dividends in specialized vision tasks, potentially reducing the need for maintaining a zoo of fine-tuned, single-purpose models.








