Key Takeaways
- Instacart's engineering team details a semantic ID system for product understanding at scale, using embeddings to create meaningful identifiers that enhance search and recommendations.
- This approach captures nuanced product relationships, improving relevance for grocery e-commerce.
What Happened

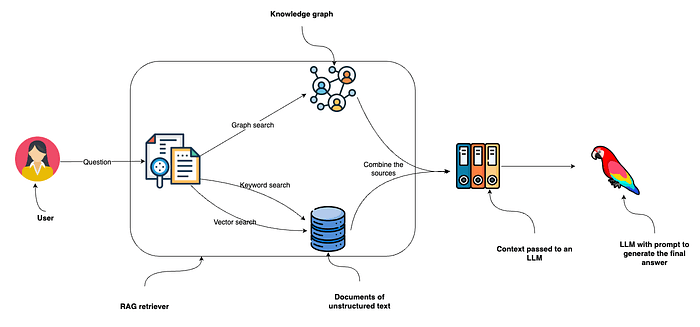
Instacart's engineering team, led by Shrikar Archak, Karuna Ahuja, Soroush Sobhkhiz, Marko Avdalovic, Xiyu Wang, JiChao Zhang, Hao Yan, and Chris Hartley, published a technical blog post detailing their approach to product understanding at scale using semantic IDs. The system moves beyond traditional product identifiers (like UPC codes) by leveraging embeddings to create unique, semantically meaningful IDs that capture product relationships.
Technical Details
Traditional product IDs are arbitrary—they don't convey anything about the product itself. Instacart's semantic IDs are generated from product embeddings, which encode attributes like category, brand, price point, and even dietary restrictions. This means products with similar characteristics have similar IDs, enabling more intelligent search and recommendation.
The system processes millions of products across Instacart's catalog, generating embeddings that are then hashed into compact, searchable IDs. This allows the platform to match products not just on exact text matches but on semantic similarity—for example, understanding that "organic whole milk" and "grass-fed whole milk" are related products even if their names don't share exact terms.
Retail & Luxury Implications
While Instacart operates in grocery, the core technology—semantic product IDs—has direct applications across retail and luxury e-commerce. For luxury brands like those at LVMH or Kering, where product catalogs are complex (think thousands of SKUs with subtle variations in color, material, or design), semantic IDs could significantly improve:
- Search relevance: A customer searching for "silk evening dress" would get results that semantically match, even if the product title says "luxury gown."
- Recommendation accuracy: Recommendations could be based on product attributes (like fabric type or silhouette) rather than just purchase history.
- Catalog management: Brands could automatically group similar products, detect duplicates, or identify gaps in their assortment.
The technology is production-ready at Instacart's scale, suggesting it could be adapted for other large retail catalogs. However, luxury brands with smaller catalogs might find simpler approaches sufficient—the value proposition increases with catalog complexity and size.
Business Impact

For retailers, the primary impact is improved customer experience through better search and recommendations, which directly drives conversion and average order value. For luxury brands, where product discovery is critical to brand experience, semantic understanding can reduce friction in the shopping journey.
The approach also reduces reliance on manual product tagging, which is costly and error-prone at scale. By automating semantic understanding, retailers can maintain consistent product discovery as catalogs grow.
Implementation Approach
Implementing semantic IDs requires:
- Embedding generation: A model to generate product embeddings from existing catalog data (titles, descriptions, images).
- Hashing mechanism: To convert embeddings into compact, searchable IDs.
- Indexing infrastructure: To support real-time search and recommendation queries.
The complexity is moderate—similar to implementing any embedding-based retrieval system. Teams with experience in NLP and vector databases will find this approachable. The primary effort is in data preparation and model training for embedding generation.
Governance & Risk Assessment
- Privacy: Low risk—the system operates on product data, not user data.
- Bias: Medium risk—embeddings can encode biases present in training data (e.g., associating certain products with demographics). Regular auditing is recommended.
- Maturity: High—Instacart has this in production at scale. The approach is well-documented and reproducible.
gentic.news Analysis
Instacart's semantic ID system is a practical application of embedding technology that has been discussed in AI research for years but rarely implemented at production scale in retail. The key insight is that product understanding doesn't require complex models—just well-designed embeddings and efficient indexing.
For luxury retail, the technology is most valuable for brands with large, complex catalogs where manual tagging is impractical. Smaller brands may not see the same ROI. The approach also aligns with broader trends in AI-powered product discovery, similar to Google's work on embeddings for search and recommendation (Google has been mentioned in 415 prior articles on gentic.news, with significant work on embedding models like Gemini Embedding 2).
However, luxury brands should note that semantic IDs based purely on product attributes may miss the experiential and emotional dimensions of luxury products—things like brand heritage, craftsmanship, or exclusivity. A purely semantic approach might group a $5,000 handbag with a $500 one if they share similar attributes, missing the brand premium. Hybrid approaches that combine semantic understanding with brand-specific signals may be more appropriate for luxury.
The broader trend here is that product understanding is moving from manual categorization to automated semantic analysis. Retailers who invest in this infrastructure now will have a competitive advantage in product discovery as catalogs grow and customer expectations rise.
Source: tech.instacart.com