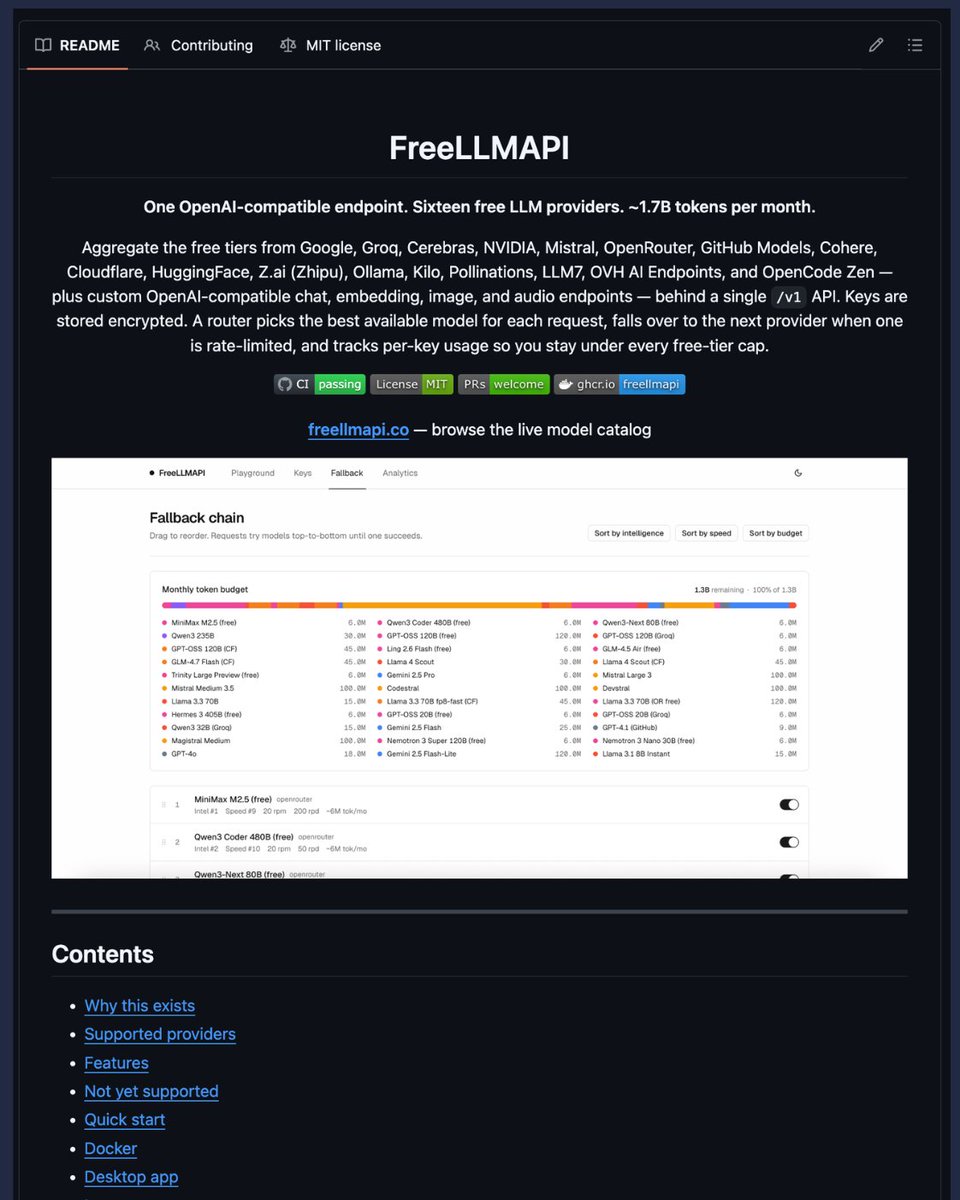
A new command-line interface tool called Insanely Fast Whisper has demonstrated dramatic performance improvements over OpenAI's standard Whisper implementation, processing 2.5 hours of audio in just 98 seconds—a 19x speedup with no reported quality degradation. The tool leverages Flash Attention 2 and optimized batching while maintaining the same Whisper large-v3 model weights.
What's New
Insanely Fast Whisper is not a wrapper or web application but a standalone CLI that transforms local hardware into a high-speed transcription engine. The tool requires no API keys, cloud services, or subscriptions, running entirely on local GPUs including NVIDIA hardware and Apple Silicon Macs. It also functions on Google Colab's free tier for users without dedicated GPU hardware.
Key features include:
- 19x speed improvement: 150 minutes of audio transcribed in 1 minute 38 seconds versus 31 minutes with standard Whisper large-v3
- Full feature preservation: Maintains Whisper's auto-language detection across dozens of languages, direct English translation capability, and timestamp accuracy
- Enhanced functionality: Built-in speaker diarization identifies who spoke when, not just what was said
- Precision timestamps: Word-level and chunk-level timestamps enable exact navigation within recordings
- Cross-platform compatibility: Zero code changes required between NVIDIA GPUs and Apple Silicon Macs
Technical Details
The performance breakthrough comes from implementing Flash Attention 2, an optimized attention algorithm that reduces memory usage and increases computational efficiency, combined with intelligent batching strategies. The tool uses the exact same Whisper large-v3 model weights as the standard implementation, ensuring identical transcription accuracy while dramatically reducing inference time.
According to the source, the standard Whisper large-v3 implementation requires 31 minutes to process 2.5 hours of audio. With Insanely Fast Whisper's optimizations, the same task completes in 1 minute 38 seconds—achieving the 19x speedup through software optimizations alone, without model architecture changes.
How It Compares
Processing Time (2.5h audio) 31 minutes 1 minute 38 seconds 19x faster Model Weights Whisper large-v3 Same Whisper large-v3 Identical Quality Baseline No reported loss Equivalent Hardware Requirements GPU/CPU GPU optimized More efficient Cost Free (local) Free (local) Same Additional Features Basic transcription Speaker diarization, enhanced timestamps ExpandedThe tool positions itself against paid transcription services by offering comparable speed without recurring costs. The 98-second processing time for feature-length audio content makes local transcription competitive with cloud-based alternatives for users with capable hardware.
What to Watch
While the performance claims are impressive, real-world results may vary based on:
- GPU memory constraints: Very long audio files or high batch sizes may exceed available VRAM
- Hardware compatibility: Performance on consumer-grade GPUs versus data center hardware
- Accuracy validation: The "zero quality loss" claim requires independent verification across diverse audio types
- Maintenance burden: As an open-source project with 8.8K GitHub stars, long-term maintenance depends on community support
The project originated as a benchmark demonstration of Hugging Face Transformers capabilities rather than a planned product, evolving based on community feedback for podcast transcription, legal recordings, research interviews, and meeting notes.
gentic.news Analysis
This development represents a significant optimization milestone in the speech-to-text ecosystem, demonstrating that substantial performance gains can be achieved through inference optimization rather than model architecture changes. The 19x speedup with identical accuracy highlights how under-optimized many production implementations of foundation models remain, even from major providers like OpenAI.
The timing is particularly notable given the broader trend toward local AI inference. As we covered in our analysis of Apple's MLX framework and the growing movement toward on-device AI, there's increasing demand for performant local alternatives to cloud APIs. Insanely Fast Whisper aligns with this trend by making high-quality transcription accessible without dependency on external services—a crucial consideration for privacy-sensitive applications in legal, medical, and research contexts.
This also reflects the maturation of the Hugging Face ecosystem, where what began as demonstration code has evolved into production-ready tooling through community adoption. The project's trajectory—from benchmark to widely-used CLI—mirrors patterns we've observed with other open-source AI tools where developer adoption drives feature development. As Whisper alternatives like Google's Chirp and Meta's SeamlessM4T continue to emerge, optimization work like this ensures the original Whisper architecture remains competitive through sheer efficiency.
Frequently Asked Questions
How does Insanely Fast Whisper achieve 19x speedup without changing the model?
The speedup comes entirely from inference optimizations, primarily Flash Attention 2 and improved batching strategies. Flash Attention 2 is an optimized attention algorithm that reduces memory operations and increases computational efficiency, while intelligent batching maximizes GPU utilization. Since the underlying Whisper large-v3 model weights remain identical, transcription accuracy is preserved while processing time drops dramatically.
What hardware do I need to run Insanely Fast Whisper?
The tool runs on NVIDIA GPUs with sufficient VRAM for your audio files, Apple Silicon Macs (M1/M2/M3), and even Google Colab's free tier if you lack local GPU hardware. Performance scales with GPU capability—higher-end GPUs will achieve faster processing times. The developers claim zero code changes are needed between platforms, though actual performance will vary based on hardware specifications.
Is there any quality difference compared to standard Whisper?
According to the developers, there is "zero quality loss"—the same audio file processed through standard Whisper and Insanely Fast Whisper should produce identical transcripts. This is possible because the tool uses the exact same Whisper large-v3 model weights, only changing how those weights are executed during inference through optimization techniques.
Can I use Insanely Fast Whisper for commercial purposes?
Yes, the tool is 100% open source with no usage restrictions beyond those of the underlying Whisper model (MIT license). This makes it suitable for commercial applications including podcast production, legal transcription, academic research, and business meeting documentation. The elimination of API costs makes it particularly attractive for high-volume transcription needs where cloud service fees would accumulate quickly.