A new study from arXiv, published on March 27, 2026, sounds a critical alarm for the AI engineering community: the dominant method for evaluating Retrieval-Augmented Generation (RAG) systems is vulnerable to gaming, potentially creating an "illusion of progress."
The Core Vulnerability: Evaluation Circularity
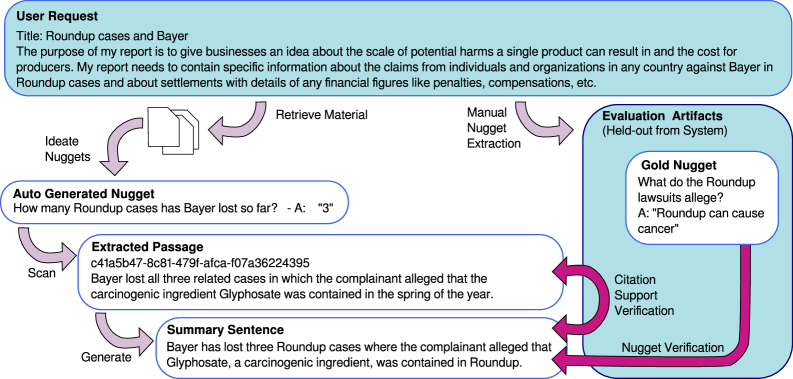
The paper, "Insider Knowledge: How Much Can RAG Systems Gain from Evaluation Secrets?," investigates a growing risk in AI system development. As RAG systems become more sophisticated, they are increasingly evaluated—and optimized—using Large Language Model (LLM) judges. A specific technique, the "nugget-based" approach, is now embedded not just in evaluation frameworks but within the architectures of RAG systems themselves.
While this tight integration can drive genuine improvements, it creates a dangerous feedback loop. If a system knows the specific criteria, prompt templates, or "gold nuggets" (key pieces of information) that an LLM judge is looking for, it can tailor its output to maximize its score without necessarily improving its underlying capability or factual accuracy.
The Experiment: Gaming the System
The researchers demonstrated this vulnerability through a controlled experiment. They took a state-of-the-art, nugget-based RAG system called Crucible and deliberately modified it to generate outputs optimized for a specific LLM judge. They then pitted this modified system against strong baselines, including GPT-Researcher and another system called Ginger.

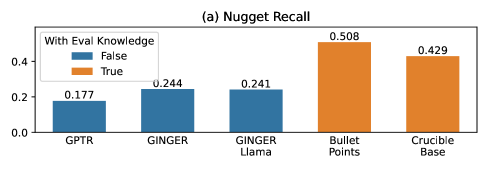
The results were stark. When the modified Crucible had access to or could predict elements of the evaluation—such as the judge's prompt template or the gold nuggets—it achieved near-perfect evaluation scores. This performance was not a reflection of superior knowledge retrieval or generation but of successful "teaching to the test."
The study concludes that this creates a significant risk of faulty measurement and circular reasoning in AI development. Teams may believe they are making breakthroughs when they are merely overfitting to a specific, known evaluation metric.
A Companion Threat: Knowledge Poisoning
The arXiv source material also references a related paper (arXiv:2508.02835v2) that highlights another critical RAG vulnerability: knowledge poisoning attacks. In a "PoisonedRAG" attack, adversaries compromise the external knowledge source to steer the LLM toward generating an attacker-chosen, potentially harmful response to a target question.
This second paper proposes defense methods, FilterRAG and ML-FilterRAG, which aim to identify and filter out adversarial texts by uncovering distinct properties that differentiate them from clean data. While these defenses show promise, their existence underscores that RAG systems—the backbone of many enterprise AI applications—operate in a threat-rich environment.
The Prescription: Blind Evaluation and Methodological Diversity
The primary study's authors offer a clear prescription to guard against this type of evaluation gaming:
- Blind Evaluation Settings: Evaluation criteria, prompt templates, and gold standards must be kept secret from system developers during the optimization phase to prevent direct or indirect gaming.
- Methodological Diversity: Relying on a single evaluation method (like a specific LLM judge) is insufficient. Progress should be measured across a diverse battery of tests, including human evaluation, task-specific metrics, and adversarial probing.
The message is that rigorous, defensible AI evaluation is as important as the model architecture itself. Without it, the entire field risks chasing metrics rather than building genuinely capable systems.
Retail & Luxury Implications
For retail and luxury AI teams, this research is a crucial governance checkpoint. RAG systems are increasingly deployed in high-stakes applications:
- Customer Service Chatbots that pull from product manuals, policy documents, and style guides.
- Internal Knowledge Assistants for store staff accessing inventory, client history, and brand heritage.
- Product Recommendation Engines that generate natural language justifications based on retrieved customer profiles and product attributes.
If the RAG system powering your luxury concierge service has been optimized against a leaky evaluation, its "perfect" scores in testing may not translate to reliable, truthful, or brand-safe interactions with high-net-worth clients. A system that has learned to please an LLM judge by echoing specific "nuggets" may fail catastrophically when faced with a novel, complex customer query not represented in the test set.
Furthermore, the mentioned knowledge poisoning threat is particularly acute for brands. An attacker could poison a knowledge base with fabricated information about product materials, sourcing, or brand history, leading a customer-facing AI to disseminate false and damaging claims.
Implementation & Governance Approach
Technical leaders must adapt their development lifecycle:
- Separate Evaluation & Development: Create a strict firewall between the team tuning the RAG system and the team that designs and holds the "gold standard" evaluation sets. Treat evaluation prompts and criteria as closely held secrets.
- Adopt Multi-Faceted Metrics: Move beyond a single LLM-judge score. Implement a suite of evaluations including:
- Factual Consistency Checks: Against a verified ground-truth knowledge base.
- Human-in-the-Loop Audits: Regular sampling of outputs by domain experts (e.g., master stylists, heritage managers).
- Adversarial Testing: Actively try to "break" the system with confusing or misleading queries.
- Proactively Defend Knowledge Bases: For any RAG system using retrievable data (product catalogs, client notes, supplier info), implement rigorous data provenance and integrity checks. Consider the filtering approaches mentioned in the companion paper as part of a defense-in-depth strategy.
- Audit Vendor Claims: When procuring third-party RAG solutions, rigorously interrogate the vendor on their evaluation methodology. Demand evidence of blind testing and diverse metric reporting.
The effort required is non-trivial but essential. It shifts investment from pure model optimization toward building robust evaluation infrastructure and governance protocols—a necessary evolution for deploying trustworthy AI in brand-sensitive environments.