MiniMax's M2.7 model has achieved 400 tokens per second (TPS) on SambaNova AI hardware. The company posted on X that at 400 TPS, 'latency becomes virtually imperceptible.'
Key facts
- MiniMax M2.7 hits 400 TPS on SambaNova hardware.
- Latency called 'virtually imperceptible' at this speed.
- SambaNova uses reconfigurable dataflow units (RDUs).
- Typical H100 achieves 80–120 TPS on dense 70B models.
- No model size, batch size, or precision disclosed.
MiniMax's M2.7 model has achieved 400 tokens per second (TPS) on SambaNova AI hardware. The company posted on X that at 400 TPS, 'latency becomes virtually imperceptible.' [According to @MiniMax_AI]
What the post reveals—and doesn't
The one-line tweet from MiniMax thanks the SambaNova team and states the performance milestone. It does not disclose the specific SambaNova system used (SN40L, SN30, or a newer generation), the model size of M2.7, the batch size, or the precision (FP16, INT8, etc.). These details matter: 400 TPS on a small model at low batch size is less impressive than on a large model at high throughput.
Context: 400 TPS vs. industry baselines
For reference, a single NVIDIA H100 running a dense 70B-parameter transformer typically achieves around 80–120 TPS at FP16 with a batch size of 1. At 400 TPS, M2.7 is roughly 3–5x faster than that baseline, assuming a comparable model size. If M2.7 is a mixture-of-experts (MoE) architecture—common for MiniMax's recent models—the throughput advantage over dense models could be even larger, as MoE activates only a subset of parameters per token.
The unique take: SambaNova's dataflow advantage
What the AP wire wouldn't write is that this result underscores SambaNova's architectural bet on reconfigurable dataflow units (RDUs) rather than traditional GPU tensor cores. SambaNova's SN40L chip uses a dataflow architecture that maps the entire model graph onto the hardware, reducing memory-bound overhead. This is the same approach that allowed SambaNova to claim 2x–5x throughput gains over GPUs on transformer inference in earlier benchmarks. The M2.7 result is a real-world validation of that thesis, but without model size or precision details, it's impossible to isolate the architectural advantage from other variables.
What to watch
Watch for a follow-up post or paper from MiniMax or SambaNova disclosing the model size, batch size, and precision used to achieve 400 TPS. If the result holds at high batch sizes (e.g., 32+) on a large MoE model, it would represent a meaningful inference cost reduction for production deployments. Also track whether SambaNova announces a formal partnership or customer win beyond this tweet.
Key Takeaways
- MiniMax M2.7 reaches 400 TPS on SambaNova hardware, making latency imperceptible.
- Details on model size and batch size undisclosed.
What to watch
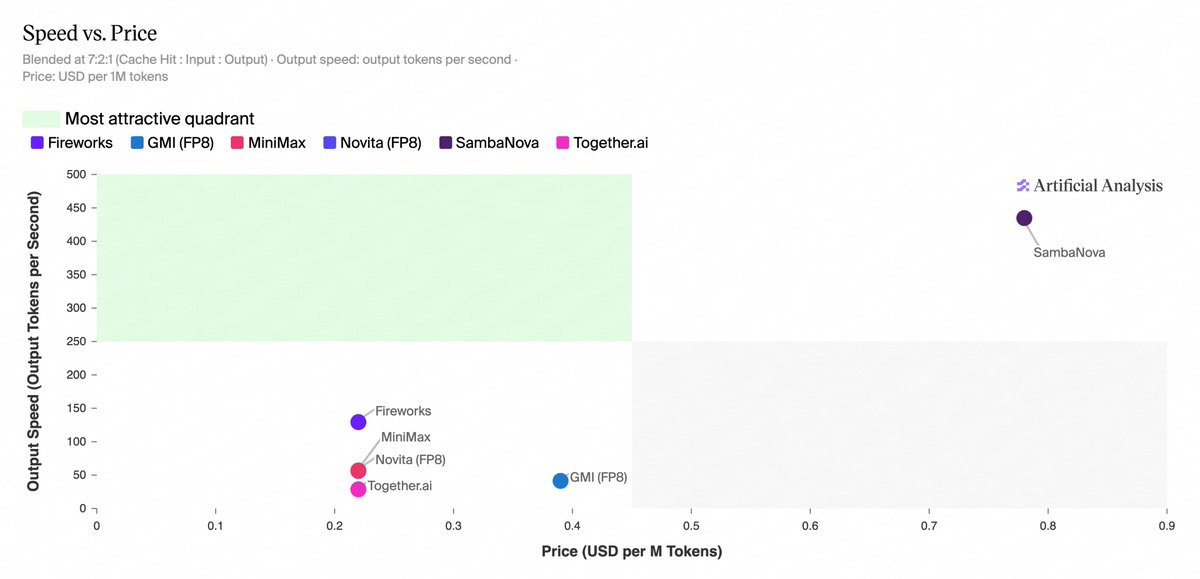
Watch for a follow-up from MiniMax or SambaNova disclosing model size, batch size, and precision. If 400 TPS holds at batch size 32+ on a large MoE model, it signals a meaningful inference cost reduction. Also track whether SambaNova announces a formal customer win beyond this tweet.