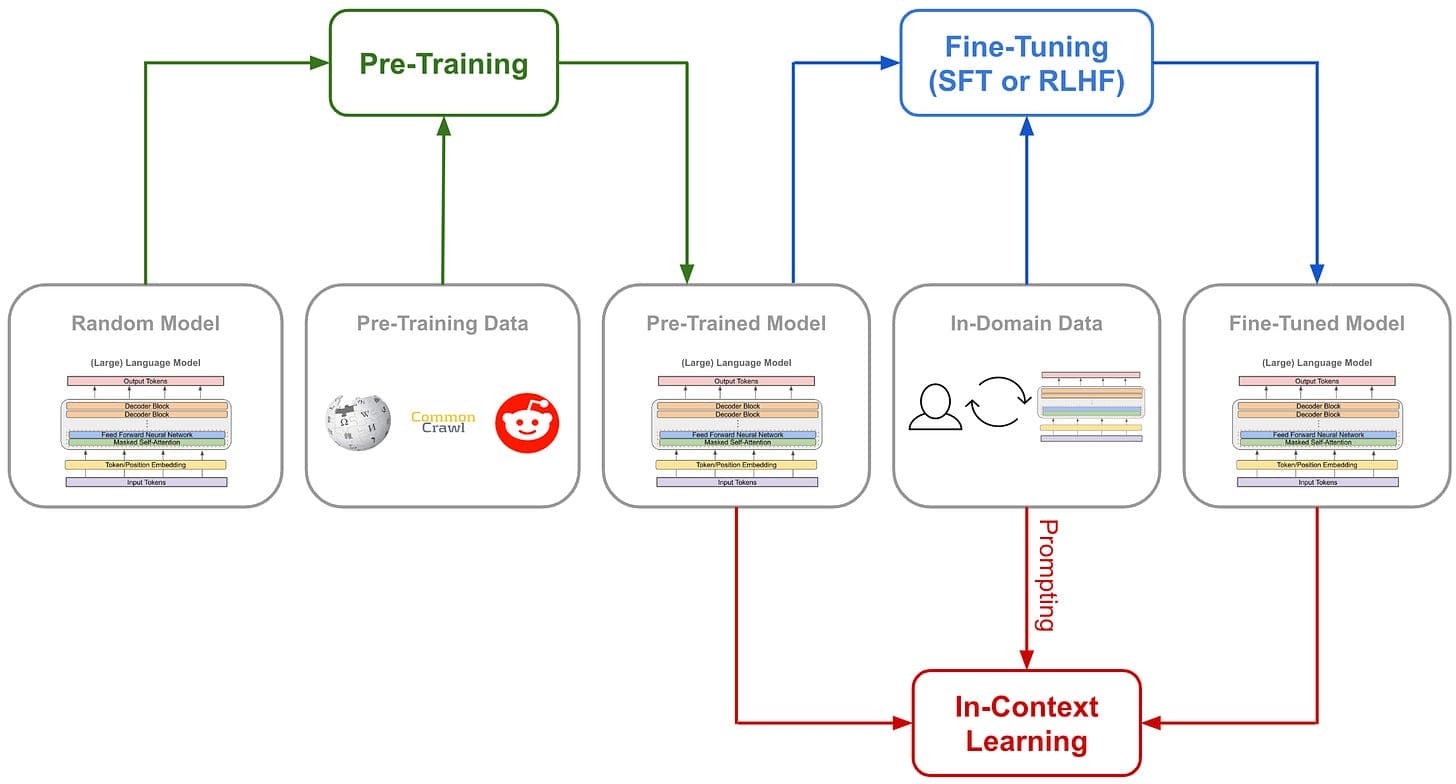
A new research direction from MIT suggests a fundamental shift in how reinforcement learning (RL) is used to align large language models (LLMs). The core argument, highlighted in a recent paper, is that RL training should optimize models to return several plausible answers rather than forcing them to converge on a single, high-probability "guess."
What the Paper Argues
The premise addresses a critical flaw in current RL-based alignment methods like Reinforcement Learning from Human Feedback (RLHF). These methods typically train a model to produce a single output that maximizes a reward model's score, which is often based on human preferences for helpfulness, harmlessness, and correctness.
The MIT researchers identify a key problem: this setup inherently penalizes diversity and plausible alternatives. In many scenarios—especially those involving reasoning, creative tasks, or questions with multiple valid interpretations—there is not one "correct" answer. A model might generate a response that is factually accurate and logically sound but differs from the single output the reward model has been tuned to prefer. Under standard RLHF, this valid alternative is discouraged, potentially reducing the model's robustness and ability to explore different reasoning paths.
The proposed alternative is to reframe the RL objective. Instead of training a policy (the LLM) to maximize the reward for one trajectory (one sequence of tokens), the training should encourage the model to generate a set of outputs that collectively have high reward. Conceptually, this moves alignment from "find the best answer" to "find a distribution of good answers."
The Technical Problem with Single-Answer Forcing
Current alignment pipelines often create a mismatch between the training objective and real-world use. The reward model is trained on pairwise comparisons of human-preferred outputs, but it is then used to provide a scalar reward for a single sequence. This can lead to:
- Over-optimization: The LLM exploits quirks in the reward model to produce a highly-scored but potentially degenerate or overly rigid response.
- Loss of Calibration: The model becomes overconfident in its single output, even when uncertainty is warranted.
- Suppression of Valid Reasoning: Non-standard but correct solution paths are suppressed during RL fine-tuning, which could harm performance on complex, multi-step problems where the "standard" solution isn't the only one.
By designing an RL framework that rewards a collection of high-quality outputs, the researchers aim to preserve this diversity and better capture the inherent uncertainty and plurality in language and problem-solving.
Potential Implications and Next Steps
If successfully developed, this approach could influence how the next generation of LLMs is trained. The benefits might include:
- Improved Robustness: Models less prone to reward hacking and more likely to provide useful alternatives if their first answer is flawed.
- Better Uncertainty Representation: Models could inherently communicate uncertainty by offering multiple plausible completions.
- Enhanced Reasoning: For tasks like code generation or math problems, generating several candidate solutions could allow for self-verification or ensemble methods.
The paper, which appears to be in early stages (prompted by social media discussion, not a full published manuscript), joins a growing body of critical work on RLHF's limitations. It aligns with other research efforts exploring distribution matching and divergence minimization as alternatives to pure reward maximization.
gentic.news Analysis
This MIT proposal taps directly into one of the most active and critical debates in modern LLM development: the alignment bottleneck. As we covered in our analysis of Direct Preference Optimization (DPO), the field is rapidly moving beyond the initial RLHF paradigm due to its instability and complexity. This MIT work is another vector of attack, focusing not on simplifying the RL pipeline (as DPO does) but on fundamentally redefining its goal from singular to plural.
The timing is significant. This follows a series of high-profile critiques of LLM behavior post-alignment, including observations that models become more verbose, less creative, and prone to sycophancy. The push for multiple plausible answers is a direct counter to the over-smoothing effect of strong RLHF, which we noted in our coverage of Llama 3's training, where Meta highlighted a balance between helpfulness and neutrality. This MIT approach offers a technical path to preserve the model's pre-trained knowledge breadth while still steering it towards human preferences.
Furthermore, this connects to broader industry trends. Companies like Google DeepMind (with its Gemini family) and Anthropic (Claude) have invested heavily in constitutional AI and process-based supervision, which are also attempts to create more robust, nuanced alignment. The MIT proposal could provide a complementary, mathematically grounded framework for these efforts. If this research gains traction, it could influence the alignment strategies for upcoming flagship models from these and other labs, potentially shifting the standard evaluation from "best answer" to "set of good answers."
Frequently Asked Questions
What is RLHF in AI?
Reinforcement Learning from Human Feedback (RLHF) is a technique used to align large language models with human values and instructions. It involves training a separate reward model on human preferences between different model outputs, and then using that reward model to fine-tune the main language model via reinforcement learning, encouraging it to generate responses humans prefer.
Why is forcing a single answer a problem for AI models?
Forcing a single answer can penalize correct but non-standard reasoning, reduce the diversity and creativity of outputs, and make models overconfident. In many real-world scenarios, there are multiple valid answers or solution paths, and a model trained to output only one may lose its ability to generate useful alternatives or properly represent uncertainty.
How would training for multiple answers work technically?
While the full details await the paper's publication, the core idea is to change the reinforcement learning objective. Instead of maximizing the expected reward for a single generated sequence, the objective would be to maximize the reward for a distribution or collection of outputs from the model. This might involve techniques that encourage the model to allocate probability mass across several high-reward responses rather than collapsing it onto one.
Has any major AI model used this multi-answer approach?
Not in its core alignment training as proposed here. However, some model interfaces and techniques hint at this idea. For example, using a low "temperature" setting to get a deterministic answer versus a high temperature to sample diverse answers is a crude form of output multiplicity. Also, some coding assistants may generate multiple code suggestions. This MIT research proposes baking the capability to natively produce a set of plausible answers directly into the model's aligned behavior.








