
What Happened
NVIDIA has published a research paper introducing Nemotron ColEmbed V2, a new family of embedding models designed specifically for visual document retrieval. The models achieve state-of-the-art (SOTA) performance on the ViDoRe (Visual Document Retrieval) benchmark, with the 8-billion-parameter variant ranking first on the ViDoRe V3 leaderboard as of February 2026, achieving an average NDCG@10 score of 63.42.
The research is motivated by the growing enterprise need to incorporate large catalogs of visual documents—such as PDFs, presentation slides, and scanned forms—into Retrieval-Augmented Generation (RAG) pipelines. Traditional dense retrieval methods often rely on OCR-extracted text, which can lose crucial visual layout, formatting, and embedded image information. Vision-Language Model (VLM)-based embeddings, like those in the ColEmbed family, process the document as an image, preserving this visual context and simplifying the indexing pipeline.
Technical Details
The Nemotron ColEmbed V2 family consists of three models built on different pre-trained VLM backbones:
- 3B variant: Based on NVIDIA's Eagle 2 with a Llama 3.2 3B language backbone.
- 4B variant: Based on Qwen3-VL-4B-Instruct.
- 8B variant: Based on Qwen3-VL-8B-Instruct.
The paper details several key techniques that contributed to the models' top performance:
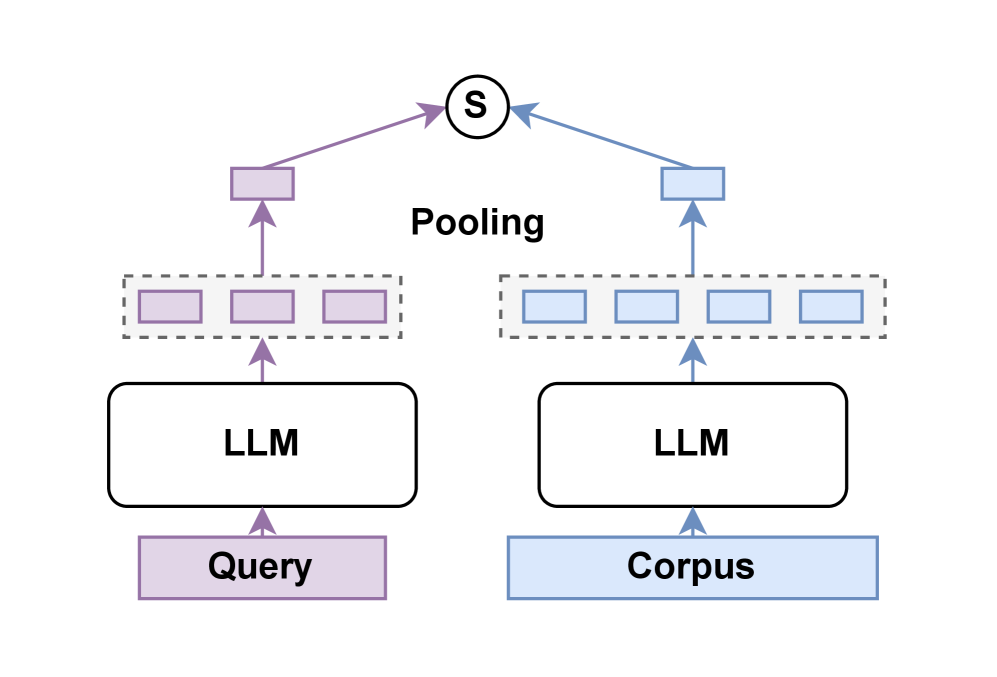
- Late Interaction: Instead of producing a single embedding vector for a query and a document, the model produces multiple token-level embeddings. The similarity score is computed by comparing all possible token pairs between the query and document embeddings. This allows for more nuanced, context-aware matching but introduces computational and storage overhead.
- Advanced Training Data Curation: The team used cluster-based sampling to ensure diverse data and hard-negative mining to teach the model to distinguish between highly similar but irrelevant documents.
- Bidirectional Attention & Model Merging: The architecture employs bidirectional attention between vision and language tokens. The final models are also the product of merging multiple checkpoints from different training stages to combine their strengths.
A significant portion of the paper is dedicated to the engineering challenges of the late interaction mechanism, which requires storing and computing over multiple embeddings per document. The researchers present experiments on compressing these embeddings to lower dimensions to find a practical balance between retrieval accuracy and storage costs.
Retail & Luxury Implications
While the paper is a technical research contribution and not a product announcement, the technology has clear, high-value applications for retail and luxury sectors, which are awash in visually complex documents.
Potential Use Cases:
- Internal Knowledge Retrieval: A designer or buyer could ask a RAG-powered assistant, "Find me all mood boards and product briefs from the last three seasons that featured 'baroque embroidery' or 'technical knitwear.'" The model could retrieve the correct PDFs or PowerPoint slides based on the visual themes and text within them.
- Vendor & Supply Chain Documentation: Retrieving specific clauses from complex, scanned contract PDFs or finding quality inspection reports (which often include photos and annotated diagrams) based on a natural language query.
- Archival and Heritage Research: Luxury houses with deep archives could use this to search through decades of scanned press clippings, lookbooks, and store design blueprints where the visual layout is as informative as the text.
- Regulatory Compliance: Quickly finding relevant safety data sheets or compliance certificates within large repositories of document images.
The core advantage here is fidelity. For a creative industry, the loss of visual information through OCR is a critical failure. A model that understands a document as a visual whole—where the placement of an image, the font of a headline, or the structure of a table carries meaning—is far more aligned with how these documents are used in practice.
The Gap to Production: It's important to note the gap between a research model and a production-ready system. The late interaction mechanism, while powerful, has non-trivial storage and compute requirements that must be engineered for scale. The 3B-8B parameter range also indicates these are not lightweight models for edge deployment. Implementing this would require a dedicated MLOps effort, likely leveraging NVIDIA's own inference platforms (like the record-setting Blackwell Ultra systems they recently highlighted) for cost-effective performance.








