In the rapidly evolving landscape of artificial intelligence, a groundbreaking study published on arXiv on February 20, 2026, introduces a novel diagnostic tool that promises to revolutionize how we understand and evaluate large language models (LLMs) in information retrieval tasks. The research paper, "Diagnosing LLM Reranker Behavior Under Fixed Evidence Pools," addresses a critical blind spot in current AI evaluation methodologies.
The Problem with Current Evaluation Methods
Traditional reranking evaluations have long suffered from a fundamental flaw: they couple ranking behavior with retrieval quality. When researchers test how an AI model reorders search results, they typically feed it documents retrieved by an upstream system. This approach makes it impossible to determine whether differences in output stem from the ranking policy itself or from variations in the retrieved documents.
As the study authors explain, "This setup couples ranking behavior with retrieval quality, so differences in output cannot be attributed to the ranking policy alone." This limitation has hampered progress in developing more effective ranking algorithms and understanding how different AI models approach information prioritization.
A Controlled Diagnostic Approach
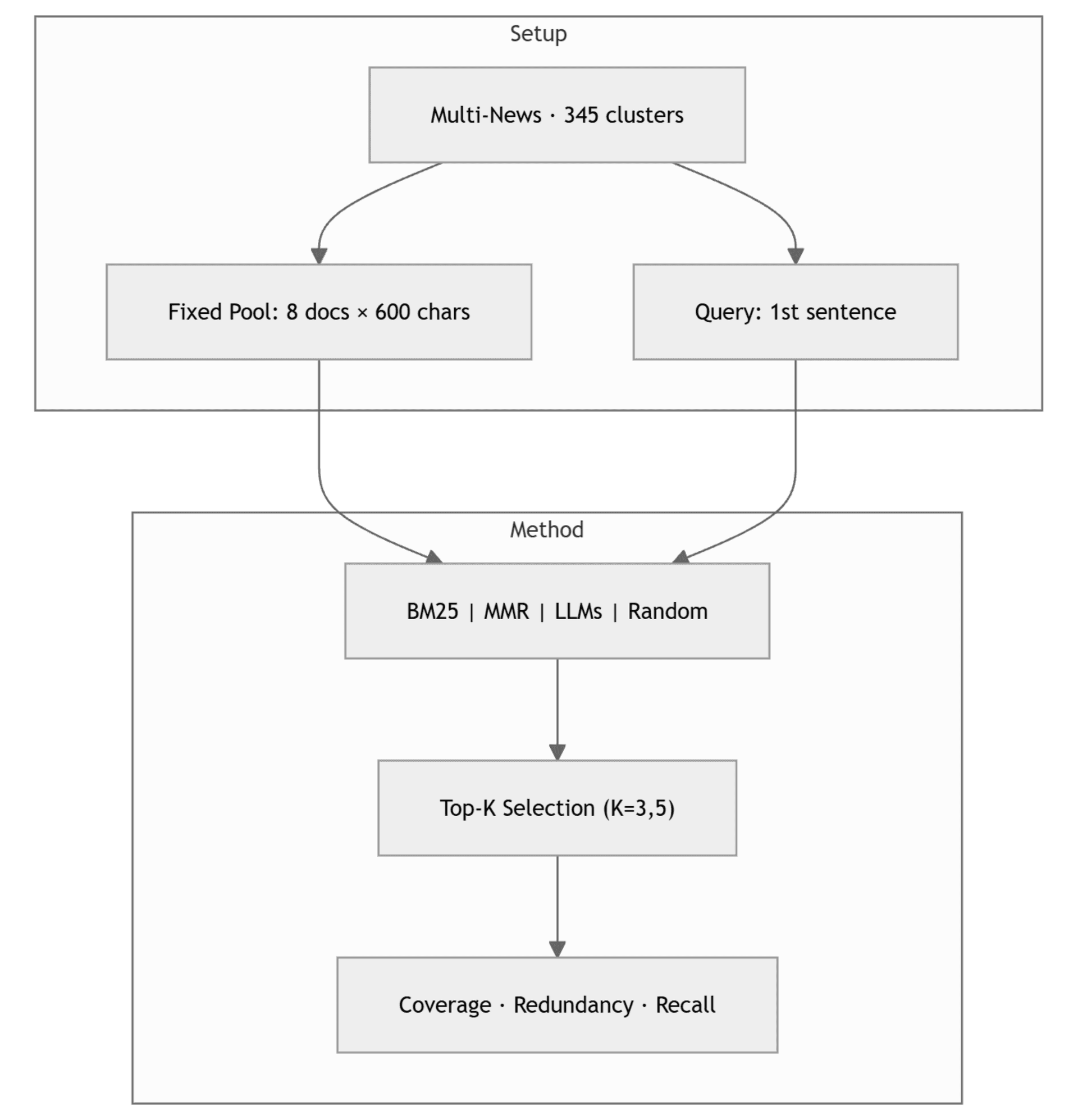
The research team developed an innovative solution using Multi-News clusters as fixed evidence pools. By limiting each pool to exactly eight documents and passing identical inputs to all rankers, they created a controlled environment where retrieval variance is eliminated. This allows researchers to attribute differences in ranking behavior directly to the ranking policy itself.
Within this setup, the researchers used BM25 (a statistical ranking function) and MMR (Maximal Marginal Relevance, a diversity optimization algorithm) as interpretable reference points. These established baselines provide clear benchmarks for lexical matching and diversity optimization against which LLM behavior can be measured.
Surprising Findings About LLM Behavior
The study analyzed 345 clusters and revealed several unexpected patterns in how different LLMs approach reranking tasks:
1. Redundancy Patterns Vary Dramatically: One LLM was found to implicitly diversify selections at larger selection budgets, while another actually increased redundancy. This suggests that different models have fundamentally different approaches to information selection, even when presented with identical input.
2. Lexical Coverage Deficiencies: LLMs consistently underperformed on lexical coverage at small selection budgets. This indicates that current models may struggle to identify the most relevant documents when they can only select a few from a larger pool.
3. Divergence from Established Strategies: Perhaps most surprisingly, LLM rankings diverged substantially from both BM25 and MMR baselines rather than consistently approximating either strategy. This suggests that LLMs are not simply implementing known ranking strategies but are developing their own, potentially more complex approaches.
Implications for AI Development and Deployment
These findings have significant implications for the development and deployment of AI systems in real-world applications:
Search Engine Optimization: The research suggests that current LLM-based ranking systems may have hidden biases and inconsistencies that could affect search results quality. Developers need to better understand these behaviors to create more reliable systems.
Information Retrieval Systems: Organizations relying on AI for document retrieval and ranking need to be aware that different models may prioritize information in fundamentally different ways, potentially affecting decision-making processes.
AI Evaluation Standards: The diagnostic tool itself represents a significant advancement in AI evaluation methodology. By isolating ranking behavior from retrieval quality, researchers can now conduct more precise comparisons between different models and algorithms.
The Broader Context of AI Evaluation Challenges
This research arrives at a critical moment in AI development. Just days before this paper's publication, arXiv published another study revealing that nearly half of major AI benchmarks are saturated and losing discriminatory power. This growing recognition of evaluation limitations makes the development of new diagnostic tools particularly valuable.
The fixed evidence pool approach is model-agnostic and applicable to any ranker, including both open-source systems and proprietary APIs. This universality makes it particularly valuable for comparative analysis across the rapidly expanding landscape of AI models.
Future Research Directions
The study opens several promising avenues for future research:
Cross-Model Analysis: Applying this diagnostic to a wider range of LLMs could reveal patterns in how different architectures approach ranking tasks.
Training Implications: Understanding these ranking behaviors could inform how models are trained for information retrieval tasks.
Real-World Validation: While the controlled environment provides valuable insights, researchers will need to explore how these findings translate to real-world applications with more complex document sets.
Conclusion
The development of this diagnostic tool represents a significant step forward in our understanding of AI behavior. By isolating ranking decisions from retrieval quality, researchers can now peer into the "black box" of LLM decision-making with unprecedented clarity. As AI systems become increasingly integrated into information retrieval applications—from search engines to research databases to enterprise knowledge management—tools like this will be essential for ensuring these systems are reliable, transparent, and effective.
The arXiv paper, consistent with the repository's mission of accelerating scientific communication, makes this important research immediately available to the global AI community, potentially accelerating improvements in ranking algorithms and evaluation methodologies across the field.








