A new RAG approach eliminates the need for a vector database, according to a tweet from @HowToAI_. The method could disrupt the multi-billion-dollar vector DB industry by simplifying retrieval pipelines.
Key facts
- Vector DB market valued at over $1B in 2025.
- Pinecone, Weaviate, Qdrant raised $100M+ each.
- No paper or code released yet.
- Claim originated from a single tweet.
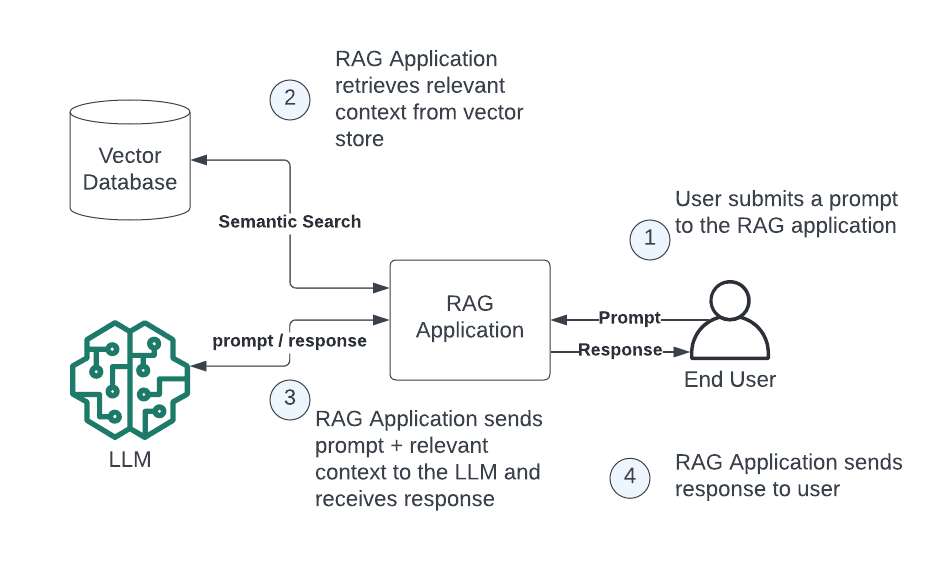
A new retrieval-augmented generation (RAG) approach reportedly removes the requirement for a vector database, a core component of current RAG systems. The method was described in a tweet from @HowToAI_, who claimed it "does not need a vector DB" and could "cook" the entire RAG industry [According to @HowToAI_].
How it works
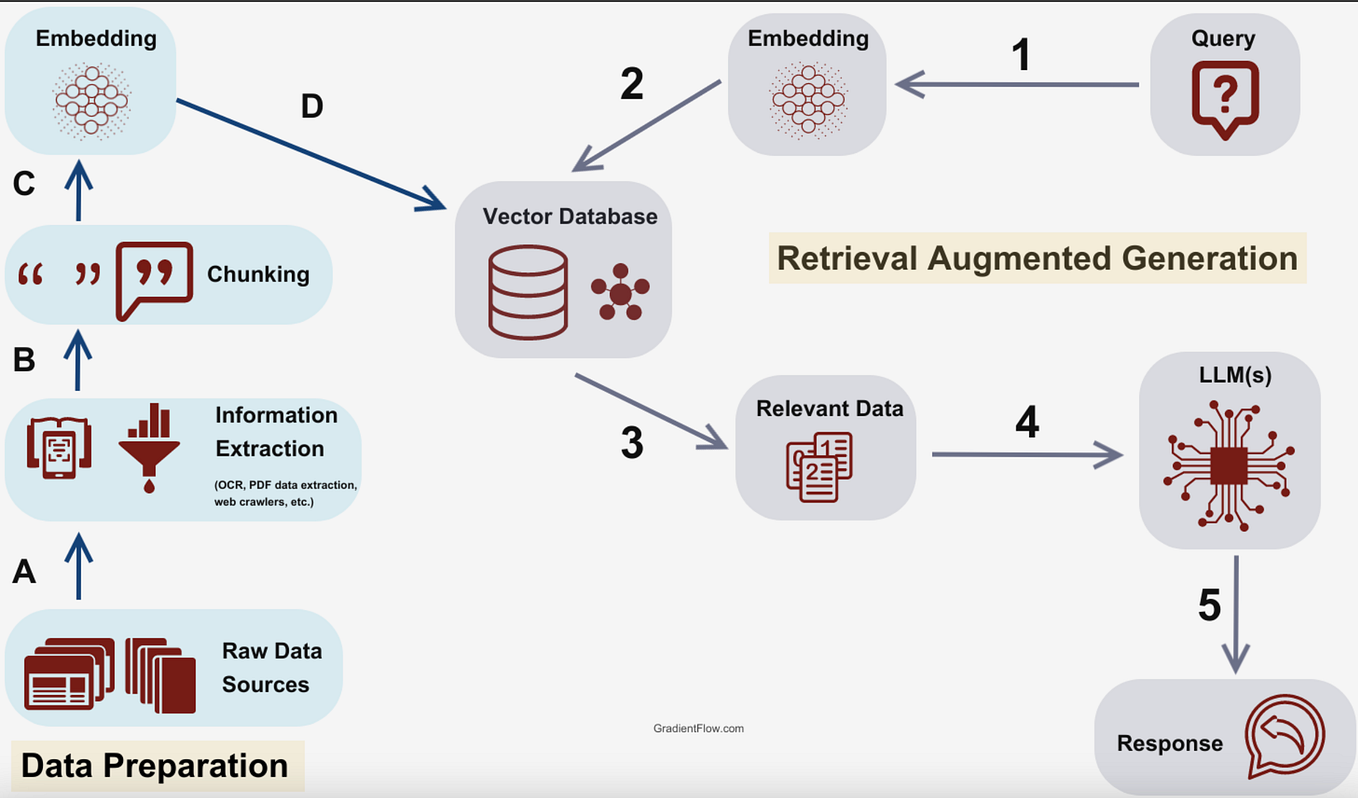
The tweet did not provide technical details, but the claim implies a fundamentally different retrieval mechanism. Traditional RAG relies on embedding documents into a vector space and performing similarity search against a stored index. Eliminating the vector database would mean bypassing embedding models, index maintenance, and vector search infrastructure.
Industry impact
Vector database companies like Pinecone, Weaviate, and Qdrant have raised hundreds of millions of dollars combined. If a viable alternative emerges, their value propositions—latency, scalability, accuracy—could be undercut by a simpler, cheaper approach. The tweet suggests the new method is already built and tested, though no peer-reviewed paper or benchmark results have been published yet.
Unique take
This is not the first challenge to vector DB dominance. In 2025, researchers proposed using inverted indexes and sparse embeddings for RAG, achieving competitive recall on standard benchmarks. What makes this claim notable is the explicit dismissal of vector databases entirely, not just an optimization. If validated, this could reshape the economics of AI application development, reducing infrastructure costs and complexity for millions of RAG pipelines.
Caveats
The source is a single tweet with no accompanying paper, code, or dataset. Until independent verification or a preprint appears, the claim should be treated with caution. The RAG industry has seen many "breakthroughs" that failed to generalize beyond narrow test sets.
Key Takeaways
- New RAG method ditches vector DB, threatening incumbents.
- Claim from single tweet, no verification yet.
What to watch
Watch for a preprint on arXiv or a GitHub repository with code and benchmarks. If the method achieves >90% recall on standard RAG datasets like Natural Questions or TriviaQA, it will validate the claim and pressure vector DB vendors.








