
Key Takeaways
- An engineer documents the process of building a semantic recommender using embeddings and vector search, focusing on the practical challenges and failures encountered.
- This is a crucial reality check for teams moving beyond collaborative filtering.
The Build: From Collaborative Filtering to Semantic Understanding
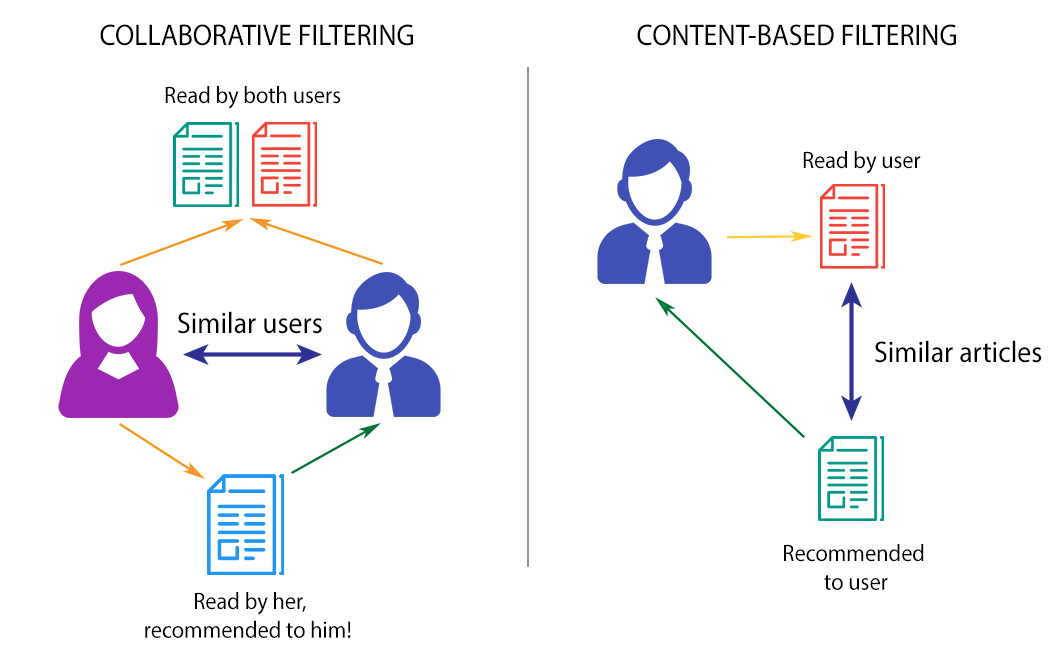
The article is a detailed technical post-mortem from an engineer who set out to build a semantic recommendation system from the ground up. The core motivation was to move beyond traditional collaborative filtering—which recommends items based on user behavior similarity—and create a system that understands the semantic content of items (like product descriptions, articles, or media) to make recommendations.
The author's architecture is emblematic of modern semantic search: transforming item text into dense vector embeddings (likely using models like Sentence-BERT or OpenAI's embeddings), storing them in a vector database (e.g., Pinecone, Weaviate, or FAISS), and performing approximate nearest neighbor (ANN) searches to find semantically similar items. The promise is a system that can recommend items based on their intrinsic properties and meaning, not just co-purchase or co-view patterns.
What Went Wrong: The Gritty Reality of Production
The true value of the piece lies in its candid catalog of failures—the "what went wrong" that most polished case studies omit.
- The Data Quality Chasm: The first major hurdle was the foundational layer: item metadata. Real-world product titles and descriptions are messy, inconsistent, and often sparse. The semantic model is only as good as the text it consumes. Garbage text in leads to nonsense embeddings out, rendering the entire "understanding" premise fragile.
- The Cold-Start Illusion: While semantic systems are often touted as a solution for cold-start problems (recommending new items with no user history), the author found this to be nuanced. A new item still requires rich, high-quality descriptive text to generate a useful embedding. A poor description for a new product yields poor recommendations, cold-start or not.
- Embedding Model Mismatch: Not all embedding models are created equal. The author likely experimented with different pre-trained models and found that a model trained on general web text may not capture the subtle nuances of a specific domain (e.g., fashion aesthetics, luxury materials, or beauty ingredients) without fine-tuning.
- Evaluation Trap: Moving away from collaborative filtering means traditional offline metrics like precision@k become trickier to define and measure. How do you quantify the business value of a "semantically similar" recommendation that a user has never interacted with before? The gap between a high cosine similarity score and a recommendation that drives engagement or conversion is vast.
- Infrastructure & Latency: Building a proof-of-concept with a few thousand embeddings is trivial. Scaling to millions of product SKUs, performing real-time ANN searches for thousands of concurrent users, and managing the pipeline to update embeddings as new products arrive is a significant engineering challenge that can derail projects.
The Path Forward: Lessons for a Viable System

The author's conclusions are not that semantic recommenders are futile, but that they require a disciplined, hybrid approach.
- Data Pipeline is Product: The first and most critical investment must be in curating, cleaning, and enriching item metadata. This is unglamorous but non-negotiable work.
- Hybrid is Hybrid for a Reason: A production-grade system rarely relies on semantics alone. The most robust approach combines semantic signals with collaborative filtering signals (what similar users liked) and other business rules (profit margin, inventory levels, campaign goals).
- Domain-Specific Fine-Tuning: For luxury and retail, where terminology and context are specific, using off-the-shelf embeddings is a starting point. The real gains come from fine-tuning embedding models on your own catalog data and user interaction logs.
- Iterative, Business-Aligned Evaluation: Start with A/B testing focused on clear business metrics—conversion rate, average order value, time on site—not just algorithmic accuracy. Validate that semantic "similarity" translates to commercial value.
Implementation Approach for Retail Teams
For a technical team in a luxury house or retailer considering this path, the roadmap is clear but demanding.
- Audit Your Metadata: Before writing a line of code, assess the quality, completeness, and consistency of product attributes, descriptions, and imagery tags. This will define your project's feasibility.
- Start with a Focused Pilot: Choose a contained, high-value use case. For example, "Complete the Look" recommendations for handbags based on product descriptions and style attributes, or content recommendations for a editorial magazine based on article embeddings. Limit the item corpus to a few thousand.
- Architect for Hybrid Signals: Design your feature store and ranking layer to accept inputs from a semantic similarity service, your existing collaborative filtering model, and a business rule engine from day one.
- Plan for Scale from Day 1: Use a managed vector database service (e.g., Pinecone, AWS OpenSearch with k-NN) unless you have a dedicated MLOps team. The operational overhead of self-managing FAISS at scale is substantial.
Governance & Risk Assessment
- Bias & Representation: Semantic models can perpetuate and even amplify biases present in training data and product copy. A system trained on historical descriptions may associate certain styles or products with specific demographics, limiting discovery.
- Explainability: It is inherently difficult to explain why a vector embedding deemed two products "similar." This "black box" characteristic can be a hurdle for merchant teams who need to understand and trust recommendations.
- Maturity Level: Medium. The core technology (transformers, vector databases) is mature and widely available. However, the practice of building reliable, business-impactful production systems with it is still evolving, as this post-mortem vividly illustrates. It is beyond the experimental phase but requires experienced practitioners to navigate the pitfalls.







